







计算机系统结构复习(六):Limits to ILP and SMT指令级并行的限制和同时多线程
指令级并行的限制
限制因素:
功耗太高(提升ILP的方法会带来更多的功耗增加)。
编译器的复杂度太高。
硬件的复杂度太高,适合计算密集型任务,不适合数据密集型任务。
理论上可以解决,实际上利用现有硬件,无法继续提升。
完美机器模型:完美分支预测无误判,没有控制相关,reg重命名,存储器别名分析解决RAW。
ILP其他缺点:
ILP并行是隐式并行,为了发觉指令级并行潜力而一 味强化乱序执行和分支预测,以至于处理器复杂度 和功耗急剧上升,得不偿失。
ILP本身也不适应计算应用类型的变化,更适用于传统计算密集型应用。
指令窗口
定义:指等待被检测是否能同时发射的指令总数。
大小影响因素: 和检测冲突所需的代价有关(50个指令就需要 2500 次检测),也和cpu存储大小有关(窗口中的指令都是在处理器中)
TLP线程级并行
TLP和DLP是显式并行。
TLP:线程级并行,线程是最小的运行单元,一个进程中可以并发多个线程(MIMD)。 线程级并行是比指令级并行更高的层次,可以显式地将几个线程并行执行,共享执行单元。
DLP数据级并行
DLP:数据级并行是比指令级并行更低的层次,允 许单一指令对多个操作数进行计算。
举例:(a+b)*(c+d),过程如下:
e = a + b
f = c + d
m = e * f
SIMD:3的结果依赖于1和2,而1和2都单纯的加法操作,所以开始想办法让1和2同时计算,那么CPU 只要两步得到答案,步骤1和2一次算出来的结果, 直接进行乘法运算。
线粒度切换方式
细粒度切换(fine grain):每条指令之间都可进行线程交换,因此线程之间是交替执行(常采用时间 片轮转方法).
粗粒度切换(coarse grain):只在某个线程发生代价较高、时间较长的Stall时(例如Cache不命中) 才进行线程交换.
| 种类 | 优点 | 缺点 |
|---|---|---|
| 细粒度切换 | CPU中可同时执行多个线程的指令;降低Stall概率,增加吞吐率。 | 使用轮换,每个独立进程的执行减慢;每个周期切换,切换速度要求高。 |
| 粗粒度切换 | 不会减慢独立线程的执行;切换线程的速度要求不高 | 不能有效减少吞吐率;因为新线程的流水线建立需要时间开销 |
线程建立时间开销
线粒度:cpu可以执行多个线程的指令,也就是对他们一视同仁。
粗粒度:只能执行一个线程的指令,因此发生阻塞时必须排空或者暂停,阻塞后切换的新的线程在指令执行产生结果之前必须先填满整个流水线。所以粗粒度仅仅在pipeline refill << stall time的时候 (也就是停顿时间远大于流水线建立时间)有效。
同时多线程 (SMT = ILP+TLP)
SMT是一种在多流出、动态调度的处理器上同时开发线程级并行和指令级并行的技术,是多线程技术的一种改进。
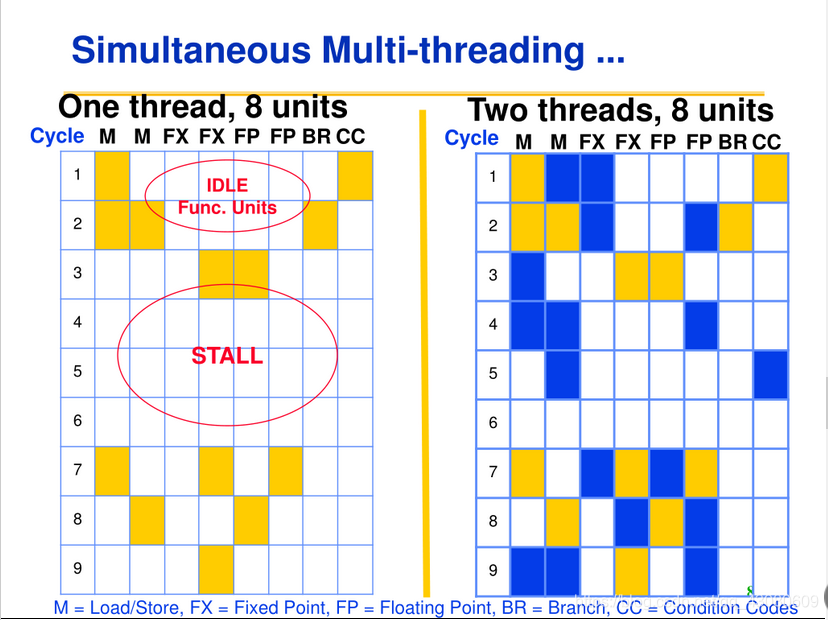
产生SMT技术的两个主要原因是什么?
原因一:现代多流出处理器通常含有多个并行的功能单元,单个线程不能有效地利用这些单元;
原因二:通过寄存器命名和动态调度机制,来自各个相互独立的线程的多条指令可以同时流出,而不用考虑它们之间的相互依赖关系
动态调度对SMT的影响
动态调度对SMT机制来说是必须的。只有通过动态调度,才可以使各个线程充分利用不同的功能单元。 使用动态调度技术的处理器已经具有了开发线程级并行的硬件设置。
1.动态调度中由大量虚拟寄存器,可以用来保存线程的寄存器状态
2.动态调度中寄存器换名可以保证线程的数据通路互不干扰
3.额外硬件用来存储线程的状态(PC,重命名表)
多线程的方式
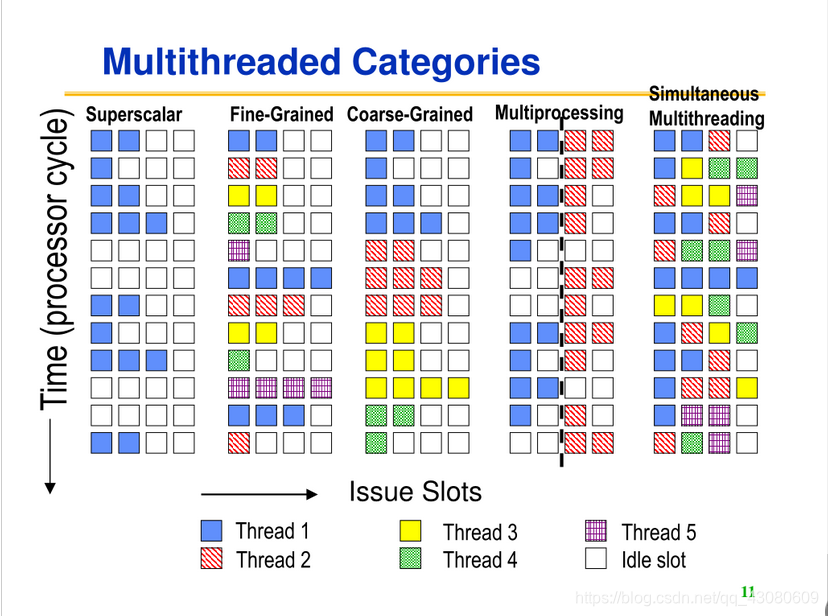
上图从左到右依次是:超标量、线粒度切换、粗粒度切换、多核多线程、同时多线程。
多核多线程:基于多核进行并行程序设计,把一个应用程序按照任务划分尽可能分解为多个任务,每个任务实现一个线程。
power5
power5 在 power4 的基础上增加了SMT。双线程,带宽增加。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









