




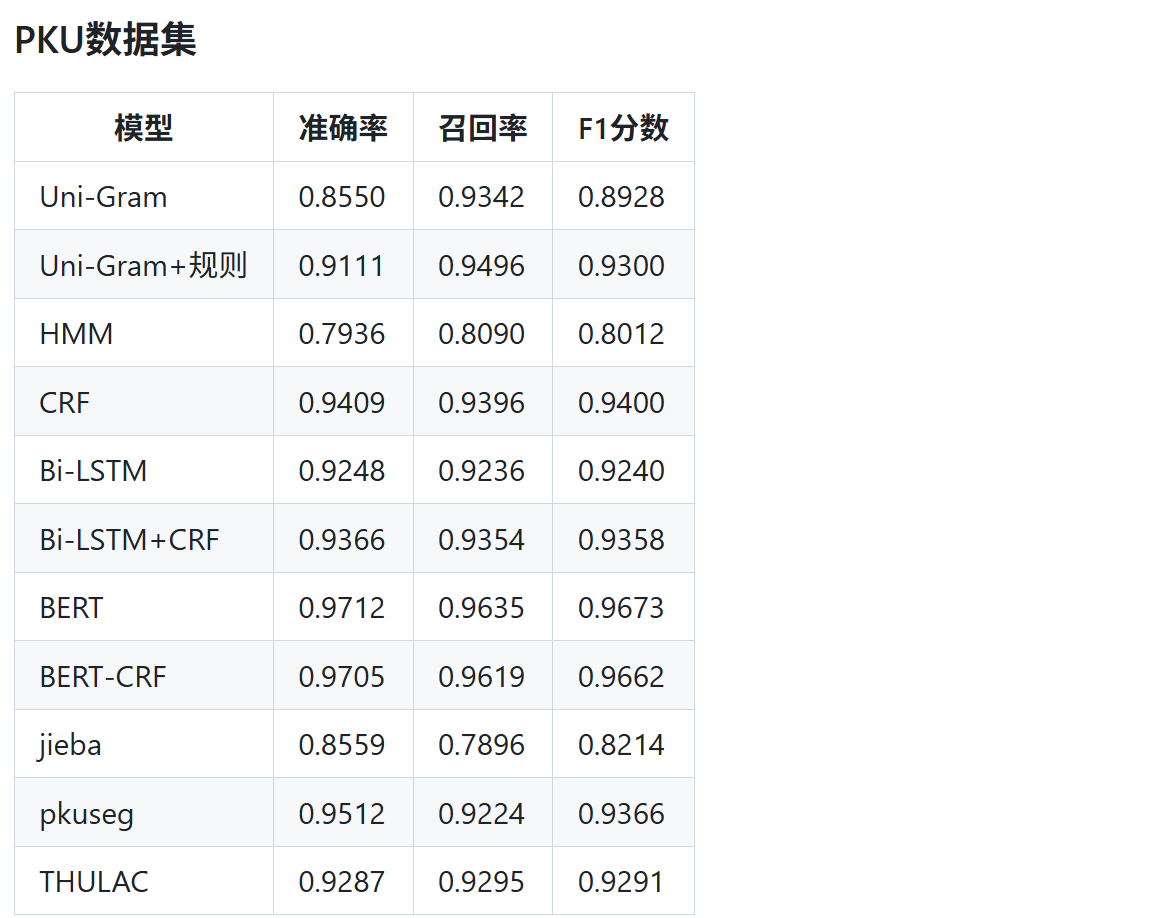
 本文探讨了中文分词的传统N-gram、HMM方法与现代神经网络技术(如CNN、LSTM)及预训练模型Bert的实践应用。通过PKU和MSR数据集实验,展示了BERT-CRF在准确率和F1分数上的显著优势,同时介绍了jieba、pkuseg和THULAC等工具的性能。
本文探讨了中文分词的传统N-gram、HMM方法与现代神经网络技术(如CNN、LSTM)及预训练模型Bert的实践应用。通过PKU和MSR数据集实验,展示了BERT-CRF在准确率和F1分数上的显著优势,同时介绍了jieba、pkuseg和THULAC等工具的性能。
自然语言处理中文分词
利用传统方法(N-gram,HMM等)、神经网络方法(CNN,LSTM等)和预训练方法(Bert等)的中文分词任务实现【The word segmentation task is realized by using traditional methods (n-gram, HMM, etc.), neural network methods (CNN, LSTM, etc.) and pre training methods (Bert, etc.)】
项目地址:https://github.com/JackHCC/Chinese-Tokenization
方法概述
- 传统算法:使用N-gram,HMM,最大熵,CRF等实现中文分词
- 神经⽹络⽅法:CNN、Bi-LSTM、Transformer等
- 预训练语⾔模型⽅法:Bert等
数据集概述
- PKU 与 MSR 是 SIGHAN 于 2005 年组织的中⽂分词⽐赛 所⽤的数据集,也是学术界测试分词⼯具的标准数据集。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











