




 本文详细介绍了机器学习的基本分类,包括监督学习、无监督学习等,并深入讲解了sklearn库的使用方法,涵盖了数据获取、预处理、模型定义与评估等关键步骤。
本文详细介绍了机器学习的基本分类,包括监督学习、无监督学习等,并深入讲解了sklearn库的使用方法,涵盖了数据获取、预处理、模型定义与评估等关键步骤。
学习参考
机器学习方式
机器学习可以分为以下五个大类:
(1 )监督学习:从给定的训练数据集中学习出-一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是输人和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归与分类。
(2)无监督学习:无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类等。
(3)半监督学习:这是一"种介于监督学习与无监督学习之间的方法。
(4)迁移学习:将已经训练好的模型参数迁移到新的模型来帮助新模型训练数据集。
(5)增强学习:通过观察周围环境来学习。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
sklearn使用
1. 获取数据
1.1 导入sklearn数据集
sklearn中包含了大量的优质的数据集,在你学习机器学习的过程中,你可以通过使用这些数据集实现出不同的模型,从而提高你的动手实践能力,同时这个过程也可以加深你对理论知识的理解和把握。(这一步我也亟需加强,一起加油!-)
首先呢,要想使用sklearn中的数据集,必须导入datasets模块:
from sklearn import datasets
下图中包含了大部分sklearn中数据集,调用方式也在图中给出,这里我们拿iris的数据来举个例子:
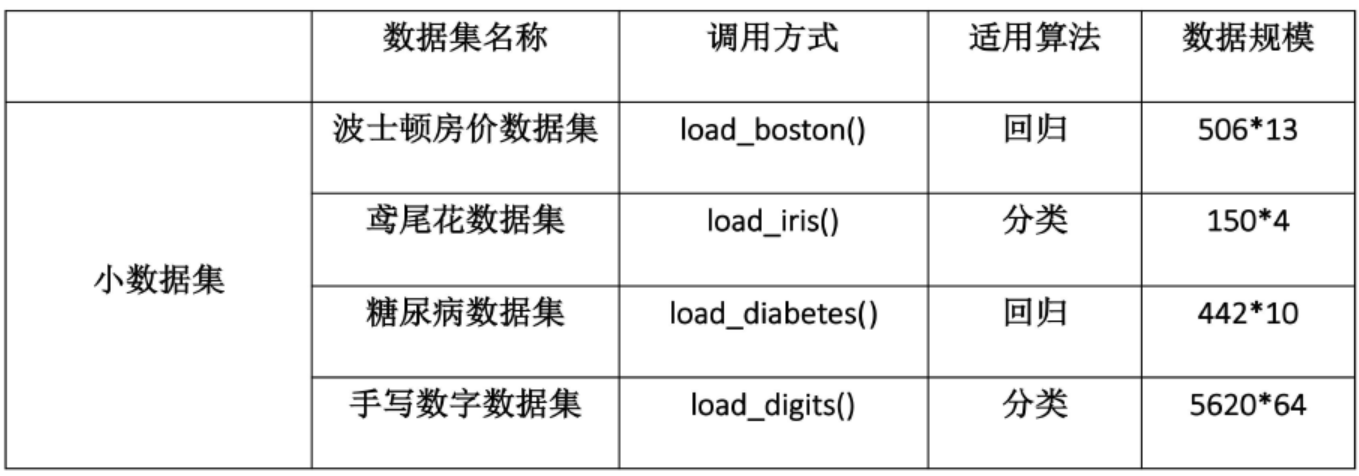
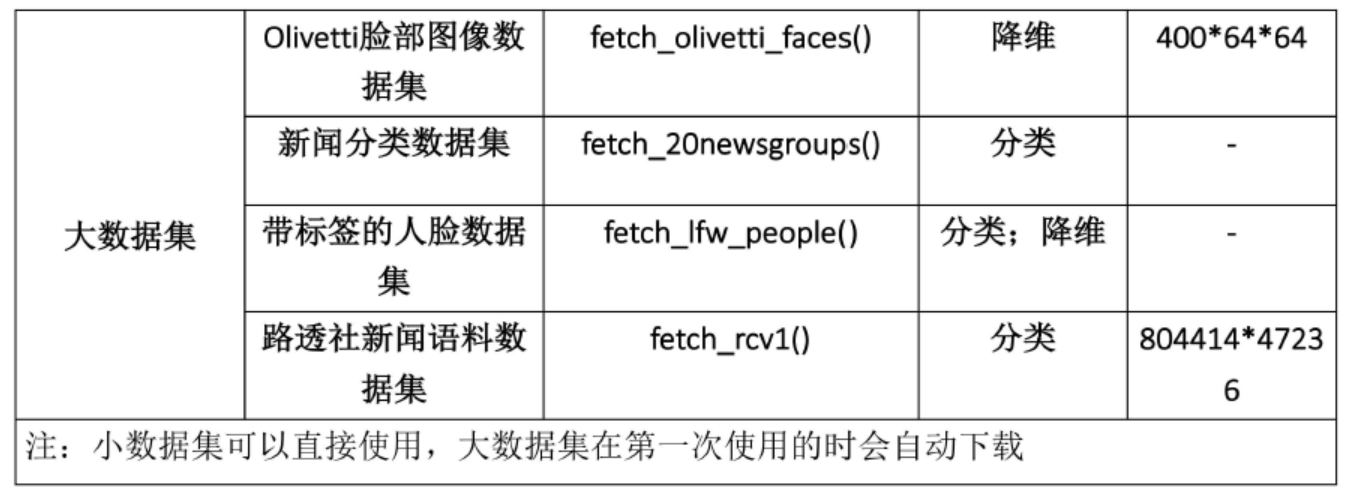
iris = datasets.load_iris() # 导入数据集
X = iris.data # 获得其特征向量
y = iris.target # 获得样本label
1.2 创建数据集
你除了可以使用sklearn自带的数据集,还可以自己去创建训练样本,具体用法参见《Dataset loading utilities》,这里我们简单介绍一些,sklearn中的samples generator包含的大量创建样本数据的方法:
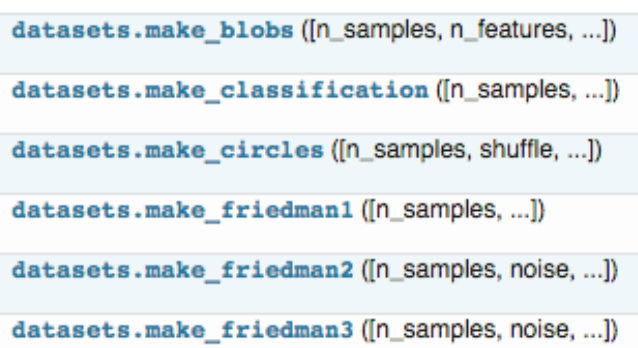

下面我们拿分类问题的样本生成器举例子:
from sklearn.datasets.samples_generator import make_classification
X, y = make_classification(n_samples=6, n_features=5, n_informative=2,
n_redundant=2, n_classes=2, n_clusters_per_class=2,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2200
2200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











