






pandas手册
https://pandas.pydata.org/pandas-docs/stable/index.html
文章目录
import pandas as pd
1. 文件读写
读写excel
df1 = pd.read_excel('abc.xlsx', sheet_name = 'sheet1')
# 一个excel写多个sheet
with pd.ExcelWriter('excel1.xlsx') as writer:
df1.to_excel(writer, sheet_name='I', index=False)
df2.to_excel(writer, sheet_name='II', index=False)
读写csv
data = pd.read_csv("Narrativedata.csv")
data = pd.to_csv("Narrativedata.csv", index=False, sep="\t")
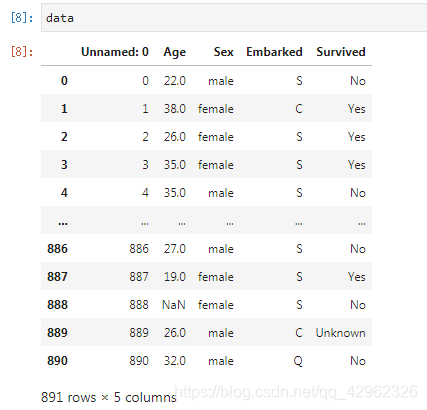
- 显示数据框信息
data.info()
2. 缺失值处理,判断是否为nan空值
- 填充缺失值 fillna
data["Age"] = data["Age"].fillna(data["Age"].mean())
3.删除缺失值 data = data.dropna()
4. 当Series中存储的是数值型的时候,里面的空是np.nan或None,统一使用np.isnan(x)进行判断
当Series中存储的是类别型的时候,里面的空是np.nan的时候,使用x is np.nan判断;里面的空是None的时候,使用x is None判断
不管Series中存储的是类别型还是数值型。如果里面的空是’‘或’ '。使用x == ‘’ 或 x.strip() == ''进行判断
if raw["GeneDetail.refGene"] is not np.nan:
3. 去重处理
4 某一列去重 labels = data["Embarked"].unique().tolist()
5. 对某一列执行 lambda
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
6.只保留除 某一列外的其他列
x = data.iloc[: , data.columns!="Survived"]
3.1 按条件删除某行
删除“1”列中位为“a”的行
frame.drop(frame.loc[frame["1"]=="a"].index, inplace=True)
多条件
df_clear = df.drop(df[(df['predict']=='####') | (df['predict']=='车位充足')].index)
4. 索引设置
7.重新设置行索引
dataframe.reset_index(inplace = True) # inplace=True是表示旧的索引当作一列新的数据添加到dataframe中 ,列名是"index",每行是原来的index号
dataframe.reset_index(drop = True) # drop=True表示将原来的索引删除,在设置新的索引
dataframe.index = [i+1 for i in range(50)] # 更换索引序号
5. 数据筛选与重新赋值
8.将列中是分类型的数据转换成0 ,1
data["Survived"] = (data["Survived"] == "YES").astype(int)
# (data["Survived"] == "YES") 返回True和false ; astype(int) 则是将True和false转换成1,0.
# 因为python中True的Int类型是1表示 ,false用0表示
9.按条件选取列
iloc为按照索引编号来选取 ,需要写前面行的信息 : ,
x = data.iloc[: , (data.columns!="Survived") & (data.columns!="Unnamed: 0")]
loc为按照索引名称选取
x = data.loc[(data.columns!="Survived") & (data.columns!="Unnamed: 0")]
10 满足条件的数据,重新赋值
col = data1.columns.tolist()
for lie in col:
data1.loc[(data1[lie] <10)| (data1[lie] >20), lie]=1
'''
把数据框中所有列的数据,满足小于10或者大于20 这个条件的(“和” 的关系用 “&”),重新赋值为1
'''
'''或'''
data1.loc[(data1[lie] <10)| (data1[lie] >20)]=1
'''或'''
# 将 chr列为23的替换为X
frame["Chromosome"][frame["Chromosome"]==23] = "X"
# 依据某一列的条件,对另一列赋值
# RZi列小于cutoff的,对CNVstatus列赋值loss ,否则赋值 -
frame["CNVstatus"] = np.where(frame["RZi"] < cutoff, "loss", "-")
#将 FH基因的Exon10的RZi改为-30
frame.loc[(frame["gene"]=="FH") & (frame["exon"]=="Exon10")]["RZi"] = -30
上面这样写会报错
应这样写
frame.loc[(frame["gene"]=="FH") & (frame["exon"]=="Exon10"), "RZi"] = -30
- 修改特定字符
列名2这一列中的A改为a, B改为b
frame["列名1"] = frame["列名2"].map({"A":"a", "B":"b"})
6. dataframe 连接
# 注意是否需要重新格式化index
merge = pd.concat([data.iloc[:,:4], data1],axis=1, ignore_index=True)
# pd.concat([df1, df2, df3 ],axis=1) axis=0纵向连接(向下连接), axis=1横向连接(向右连接)

上图这种连接方式时按照index来连接的。所以当需要按照某一列为轴合并两个frame时,可以将那一列设置成index,再用concat合并。(这种方式会将index一样的合并,但是列中相同名的会有两列)
6.1 dataframe merge合并
# 注意是否需要重新格式化index
result = pd.merge(df1, df2, on=['chrom', 'start', 'end'])
当有多个列表想要合并时(行不同):
mergeFrame=framelist[0]
for index,frame in enumerate(framelist[1:]):
mergeFrame = mergeFrame.merge(frame,how='outer', on=['gene_name','gene_id'])
#print(mergeFrame)
7. 筛选匹配行
- Pandas提取含有指定字符串的行(完全匹配,部分匹配)
完全匹配==
df.loc[(df["lie1"]=="A")]
不完全匹配
'''
case =False 不区分大小写
'''
df.loc[df["lie1"].str.contains("A", case=False)]
多条件,不包含某个字符, 格式: df [ ~(条件) ]
df[~( (df["A"].str.contains(",")) & (df["B"].str.contains("|")) )]
'''
当df中含有缺失值时,使用contains会报错
na = False时 ,只选出符合条件的,并且不为缺失值的行, True则选出缺失值的行
'''
df.loc[df["lie1"].str.contains("A", na=False,case=False)]
筛选出 字符 在某个范围中的行
'''
筛选出等于 A 或 B 或 C 的行
'''
df.loc[df["lie1"].isin(["A","B","C"])]
'''
若筛选不在[A B C]中的行,在前边加 ~
'''
df.loc[~df["lie1"].isin(["A","B","C"])]
参数regex:使用正则表达式模式
df.loc[df["lie1"].str.contains("z.*g")]
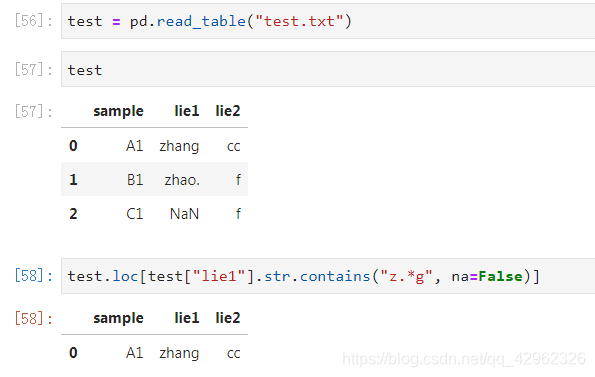
默认情况下,cintains将传入的参数按照 正则表达式去搜索 , 所以在若在搜索的字符串中含有特殊符号,如 "." , 例如,想筛选出字符串中包含 "." 的行,若直接写
df.loc[df["lie1"].str.contains(".")]
则contains会把"." 作为正则表达式的符号进行搜索
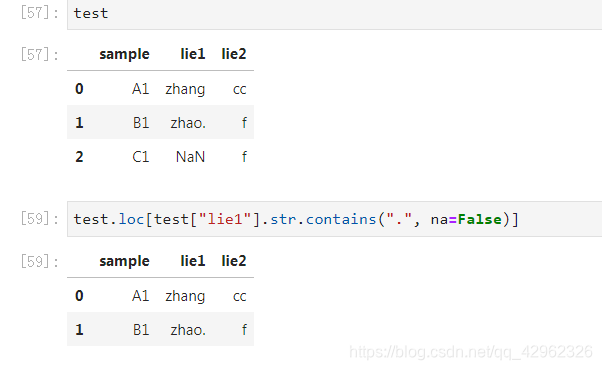
所以,要添加参数 regex=False ,表示将传入的字符串按照字符来匹配
df.loc[df["lie1"].str.contains(".", regex=False)]
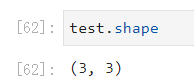
7. 数据框大小,几行几列
df.shape
(几行,几列)
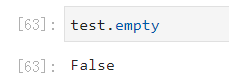
是否为空
df.empty
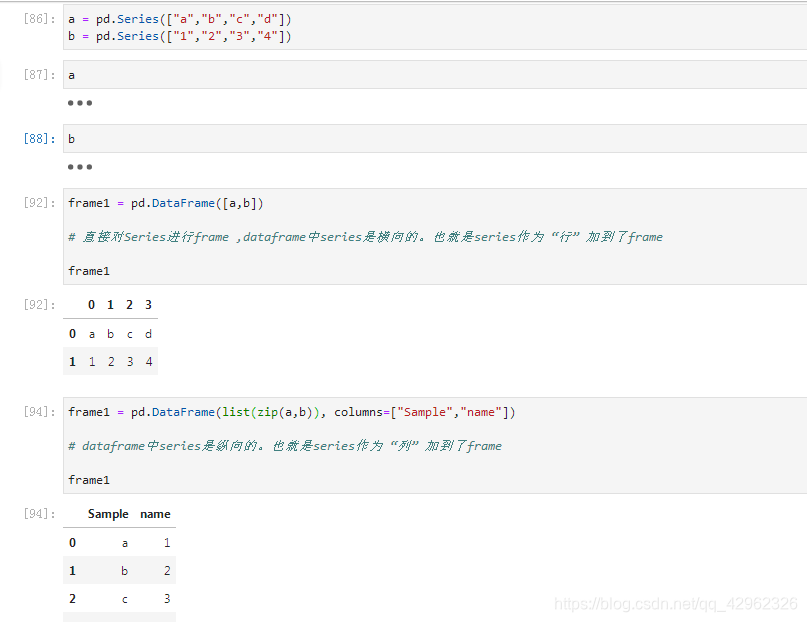
8 Series 转dataframe
a = pd.Series(["a","b","c","d"])
b = pd.Series(["1","2","3","4"])
frame1 = pd.DataFrame([a,b])
frame1 = pd.DataFrame(list(zip(a,b)), columns=["Sample","name"])
9 dataframe排序
升、降序排列
# axis=0 对列排序 ,ascending=False 降序 ,inplace=True 在原始frame更改
frame.sort_values(by=["列名"],axis=0,ascending=False,inplace=True)
按照某列的值,以给定的顺序进行排列
#将frame按照 name 列,以 'Bob', 'Tom', 'John', 'Alice' 的顺序排列
frame_order = ['Bob', 'Tom', 'John', 'Alice']
frame1_order= frame1.sort_values(by='name', key=lambda x: x.map({v: i for i, v in enumerate(frame_order)}))
10 读取文件时跳过前几行
Frame = pd.read_table(File,skiprows=1) # skiprows=1 跳过第一行
11 重新定义表头/单独修改某列名
head = ["col1","col2","col3"]
Frame.columns=head # 重新定义表头
或
df.rename(columns={'列名':'新列名'},inplace=True)
12. pandas加速处理
from pandarallel import pandarallel
pandarallel.initialize(nb_workers=20, progress_bar=True) # nb_workers 表示使用的cpu数
result = dataframe.parallel_apply(lambda x:func(x), axis=1)
13 apply返回多个值时,使用zip(*)
def a(x):
c,s,e=re.split(':|-',x)
return c,s,e
frame['chrom'], frame['start'],frame['end'] = zip(*frame['ID'].apply(lambda x:a(x)))
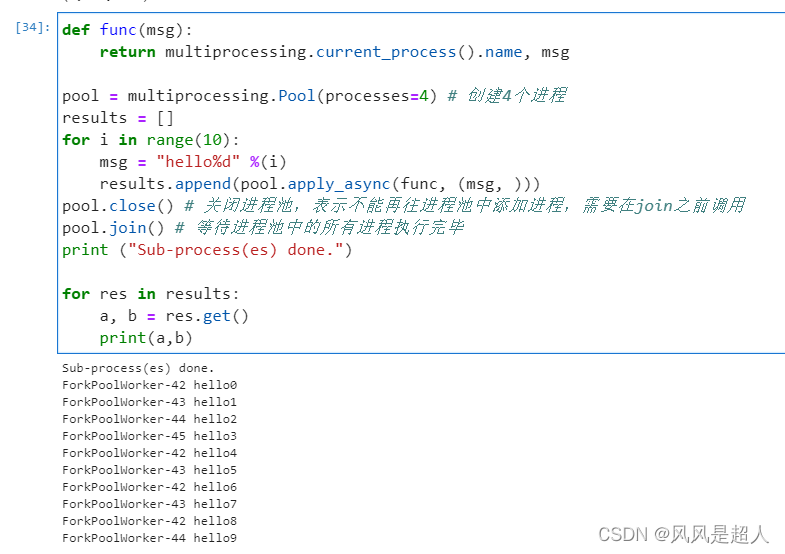
14 python 多进程
import multiprocessing
import time
def func(msg):
return multiprocessing.current_process().name, msg
pool = multiprocessing.Pool(processes=4) # 创建4个进程
results = []
for i in range(10):
msg = "hello%d" %(i)
results.append(pool.apply_async(func, (msg, )))
pool.close() # 关闭进程池,表示不能再往进程池中添加进程,需要在join之前调用
pool.join() # 等待进程池中的所有进程执行完毕
print ("Sub-process(es) done.")
for res in results:
a, b = res.get()
print(a,b)


















 1134
1134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











