




CVPR2022
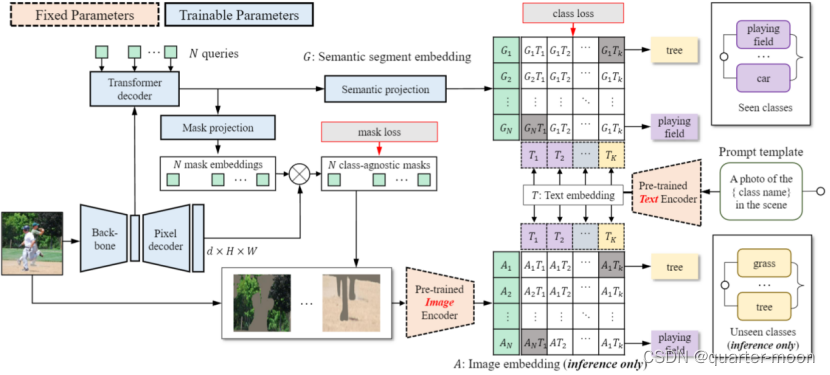
进行Zero-shot语义分割的ZegFormer:首先将N个query(N取100,一般小于语义数量)和backbone得到的特征提供给transformer decoder,生成N个segment embedding。然后将每个segment embedding分别再经过一层全连接改变通道数得到语义嵌入,以及通过mlp得到mask embedding。Mask embedding与pixel decoder的输出相乘得到不知道对应类别的二进制掩码,而语义嵌入则通过用clip得到的文本嵌入进行分类。
训练阶段,只使用所看到的类来训练分类头,在生成的二进制掩码mask和语义嵌入经过文本嵌入作为分类器得到的分类logits,使用bipartite matching,损失和二分图匹配的cost与mask former一样。
Inference阶段,通过二进制掩码mask原图(或者crop原图,论文消融分析得到mask同时crop原图效果最好),得到只包含对应语义的图,将其输入clip预训练好的image encoder得到图片embedding,和训练阶段类似使用文本嵌入作为分类器得到预测语义类。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









