



 该论文提出了一种新的策略,用prototype语义描述像素信息,以减少计算量。通过设计自适应频率滤波块(AFF),在空间域中捕获高频和低频特征,增强了语义分割的效果。文章还介绍了FSK模块,它使用位置编码学习关键组件,并采用了不同于常规自注意力的计算方式。DLF和DHF模块分别处理低频和高频信息,以保留图像细节。尽管Seaformer参数量大,但计算量较小,提高了效率。
该论文提出了一种新的策略,用prototype语义描述像素信息,以减少计算量。通过设计自适应频率滤波块(AFF),在空间域中捕获高频和低频特征,增强了语义分割的效果。文章还介绍了FSK模块,它使用位置编码学习关键组件,并采用了不同于常规自注意力的计算方式。DLF和DHF模块分别处理低频和高频信息,以保留图像细节。尽管Seaformer参数量大,但计算量较小,提高了效率。
AAAI2023
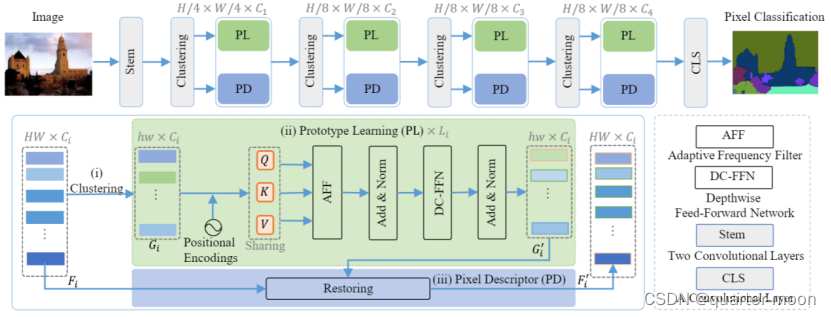
1、要提取图像语义,可以在高分辨率特征中提取图像语义,但引入了大量的计算,所以提出了一种用prototype语义描述像素语义信息的新策略。2、并且,模型对频率信息的去除极其敏感,即使去除少量也会导致显著的性能下降。挖掘更多的频率信息可以增强类别之间的差异,使每个类别之间的边界更加清晰,从而提高语义分割的效果。一般采用傅里叶变换和反变换,但计算开销大,很多硬件上都不支持。因此,从频谱相关性的角度设计了基于vit的自适应频率滤波块AFF,直接在空间域中捕获重要的高频和低频特征。
对于每个阶段,给定一个特征F∈RH×W ×C,先经过stem。Stem是两个3x3的stride为2的卷积。我们首先初始化一个网格G∈Rh×w×C作为图像的原型。初始化的方式也就是图中clustering,clustering会输出两个分支,第一个分支会在第二个stage的时候用depthwise pointwise conv下采样一半,第二个分支是在第3个stage下采样一半,第四个stage下采样1/4,不下采样的时候也是depthwise pointwise conv。第一个分支是输出的F,第二个分支输出的G。其中G中的每个点作为一个局部聚类中心,可以通过更新G而不是F来减少参数量。用transformer更新的G(原型语义)结合F(像素语义,会先把F映射为低维度的特征)来恢复特征,是上采样到一样分辨率后用相加的方式来恢复,再接卷积和激活nn.hardswish得到被恢复的特征。这里的Transformer的FFN在第一次全连接后加了depthwise conv。
AFF(对应transformer的attn)由三部分实现:动态卷积核部分在同一个stage多个transformer是共享参数的。
![]()
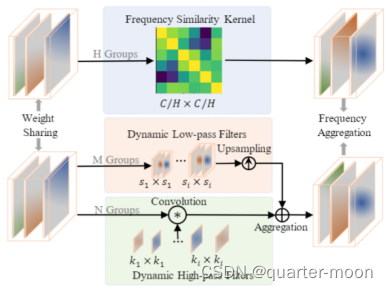
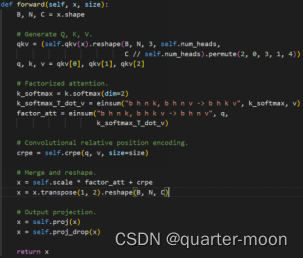
FSK模块选择和增强有助于语义解析的重要组件,对G加上通过G接的depthwise卷积学习到的位置编码,这个位置编码是一个stage多层transformer共享的。在transformer的attn位置,论文用不共享的映射头对特征映射成q、k、v,与寻常自注意力不同,首先对key在hw上softmax,和value得到矩阵相乘得到通道之间的相似度,再与query矩阵相乘,得到被更新后的query。H代表是分成了H组,结果是在H上concat。
Dynamic Low-Pass Filters (DLF)模块:低频分量在绝对图像中占据了大部分能量,代表了大部分语义信息。分成M组(4组)控制不同的内核和步长,用AdaptiveAvgPool 得到不同大小特征图,最后上采样到一样分辨率后在通道上concat。
![]()
DHF模块:高频信息是分割中保留细节的关键。卷积可以过滤掉不相关的低频冗余分量,保留有利的高频分量。分成N组,使用具有不同核的depthwise卷积层(具有不同膨胀率)来模拟不同高通滤波器的截止频率。
![]()
此外,使用query和高频特征的按元素乘积来抑制物体内部的高频,对应DHF模块的输出。
CLS分割头就是单纯的一层卷积加group norm和relu激活。
结果:
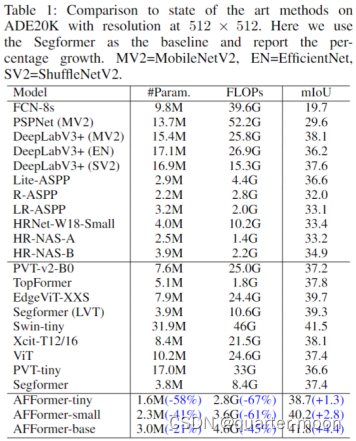
而seaformer的参数量大,但是计算量少。
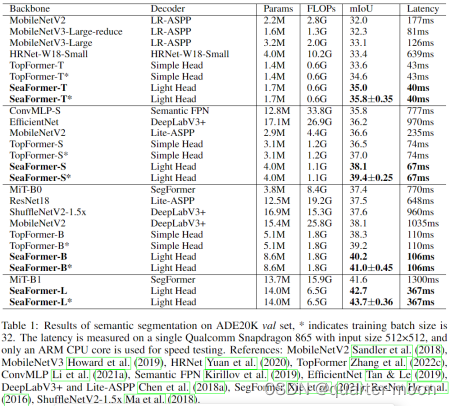
问题:
- FSK模块代码实现中的k_softmax_T_dot_v(对应Ai,j)和论文计算Ai,j的公式不一致,不太理解。并且是先在key的hw上softmax,再将key和value相乘得到attn matrix,再将attn matrix和query相乘,和寻常在attn matrix上softmax不同,也不太理解。


















 1587
1587




 到【灌水乐园】发言
到【灌水乐园】发言







