







Bert模型: 无监督:预训练
有监督:微调
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,



144个self-attention机制
离当前字的距离越远,相关程度越低

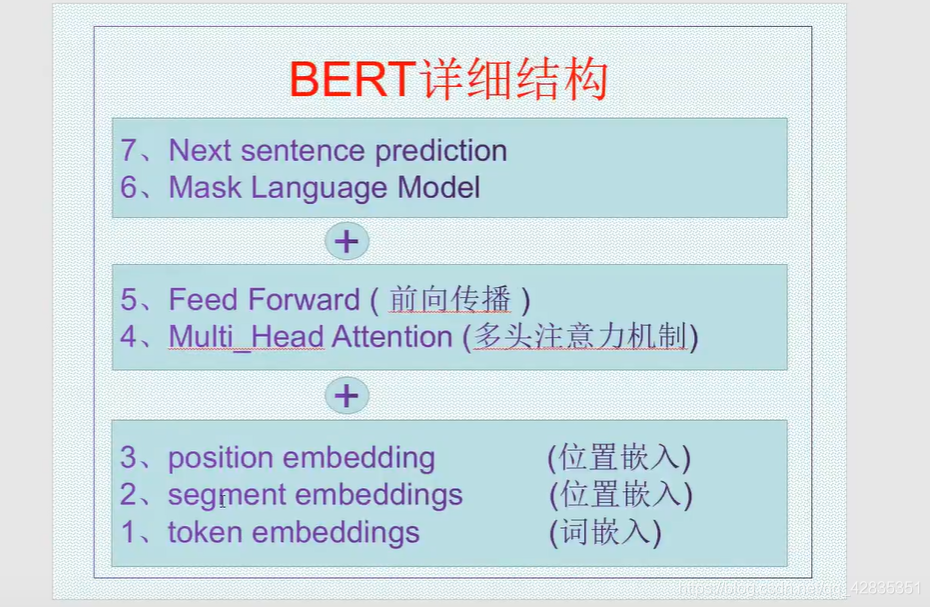
 BERT模型是一种双向Transformer编码器,包括144个self-attention机制。在预训练阶段,它通过预测被遮挡的单词和判断句子间关系进行学习。在微调阶段,可以应用于特定的下游任务。BERT的输入包含Token Embeddings、Segment Embeddings和Position Embeddings。其中,Token Embeddings中的CLS标志用于分类任务,而Position Embeddings是学习得到的。模型的两个主要任务是:遮挡词汇预测和下一个句子预测,分别通过交叉熵损失函数进行优化。
BERT模型是一种双向Transformer编码器,包括144个self-attention机制。在预训练阶段,它通过预测被遮挡的单词和判断句子间关系进行学习。在微调阶段,可以应用于特定的下游任务。BERT的输入包含Token Embeddings、Segment Embeddings和Position Embeddings。其中,Token Embeddings中的CLS标志用于分类任务,而Position Embeddings是学习得到的。模型的两个主要任务是:遮挡词汇预测和下一个句子预测,分别通过交叉熵损失函数进行优化。
Bert模型: 无监督:预训练
有监督:微调
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,
144个self-attention机制
离当前字的距离越远,相关程度越低
 3203
2513
2552
1万+
718
3203
2513
2552
1万+
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























