







 Seq2Seq模型是Google开发的经典NLP模型,常用于机器翻译、人机对话等场景。该模型由编码器和解码器组成,其中编码器将输入序列转化为隐藏向量,解码器则根据此向量生成输出序列。在训练过程中,encoder的最后一个状态传递给decoder,通过不断优化损失函数更新模型参数。双向LSTM可以改进模型的记忆能力,但decoder必须保持单向以确保序列生成的顺序。
Seq2Seq模型是Google开发的经典NLP模型,常用于机器翻译、人机对话等场景。该模型由编码器和解码器组成,其中编码器将输入序列转化为隐藏向量,解码器则根据此向量生成输出序列。在训练过程中,encoder的最后一个状态传递给decoder,通过不断优化损失函数更新模型参数。双向LSTM可以改进模型的记忆能力,但decoder必须保持单向以确保序列生成的顺序。
seq2seq(sequence to sequence)模型是NLP中的一个经典模型。最初由Google开发,并用于机器翻译。它基于RNN网络模型构建,能够支持且不限于的应用包括:语言翻译,人机对话,内容生成等。Seq2Seq,就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
- Seq2Seq 属于 Encoder-Decoder 的大范畴
- Seq2Seq 更强调目的,Encoder-Decoder 更强调方法
seq2seq模型结构和特点
seq2seq指的是从序列A到序列B的一种转换。主要是一个由编码器(encoder)和一个解码器(decoder)组成的网络。编码器将输入项转换为包含其特征的相应隐藏向量。解码器反转该过程,将向量转换为输出项,解码器每次都会使用前一个输出作为其输入。
搭建encoder+decoder训练模型
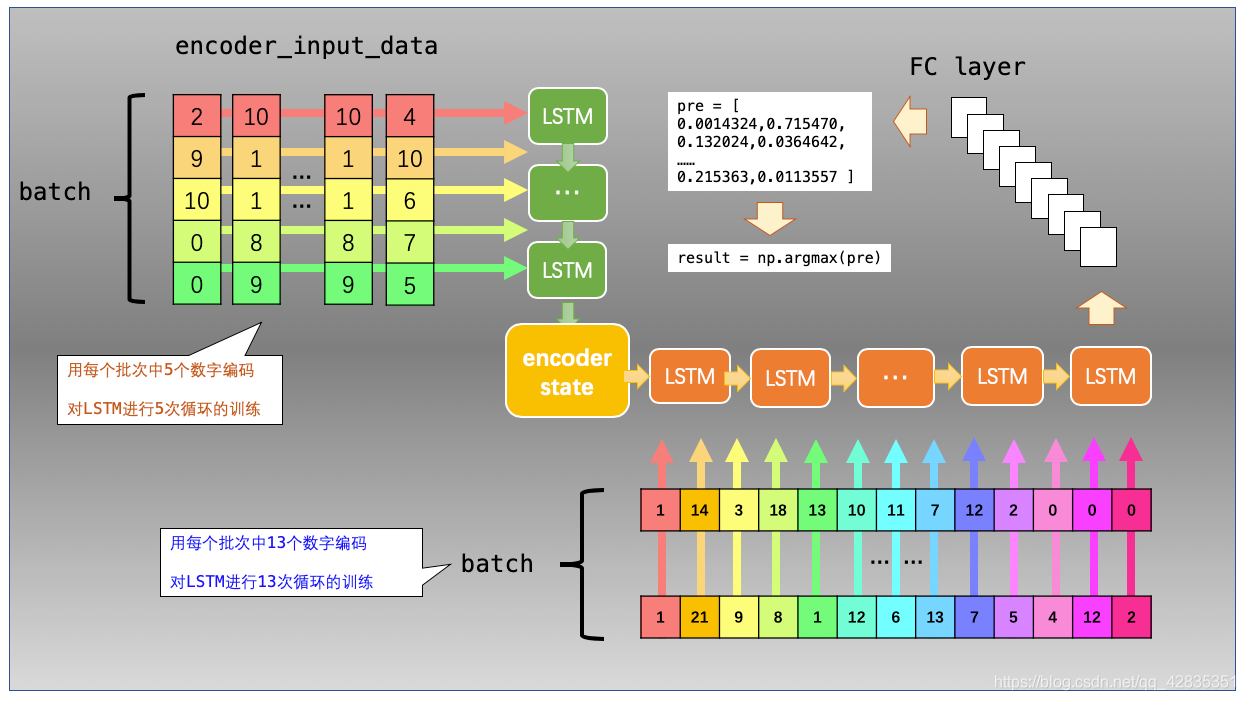
encoder模型在进行训练后,需要把自身的state导出。作为decoder模型的输入,所以需要定制LSTM的两个参数:return_state和return_sequences
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









