






Sora是如何做到文生视频
文章目录
1. 背景
无论是文生图还是文生视频,很多这方面的工作其实都可以看成是自编码器的进阶版本,让我们从自编码器开始入手, 逐步了解文生视频的原理。本文将从文本生成图像到文本生成视频的技术演进角度进行剖析,解读从AE、VAE、DDPM、LDM到DiT和Sora的技术发展路线
2. 核心技术演进
2.1 自编码器-AE
Autoencoder:压缩大于生成
自编码器由编码器和解码器两个部分构成
- 编码器负责学习输入到编码的映射 ,将高维输入(例如图片)转化为低维编码 z = e ( x ) z = e(x) z=e(x)
- 解码器则学习编码到输出的映射 ,将这些低维编码还原为高维输出(例如重构的图片)
x
=
d
(
z
)
x = d(z)
x=d(z)
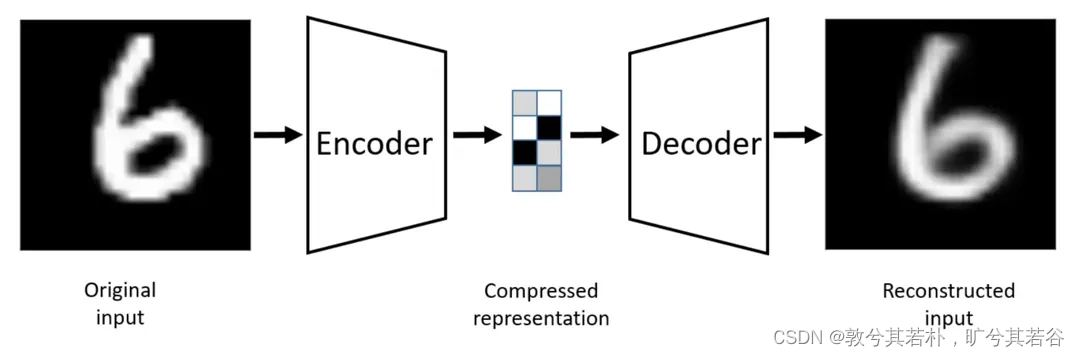
我们希望压缩前和还原后的向量尽可能相似(比如让它们的平均平方误差MSE尽可能小)
l
o
s
s
=
∣
∣
x
−
x
1
∣
∣
2
=
∣
∣
x
−
d
(
z
)
∣
∣
2
=
∣
∣
x
−
d
(
e
(
x
)
)
∣
∣
loss = || x - x_1 ||^2 = ||x - d(z)||^2 = ||x-d(e(x))||
loss=∣∣x−x1∣∣2=∣∣x−d(z)∣∣2=∣∣x−d(e(x))∣∣
这样就能让神经网络学会使用低维编码表征原始的高维向量
那有了自编码器能够做生成吗,答案是可以的,只要留下解码器,我随便喂入一个低维编码,不就能够得到一个生成的高维向量了。当然,这里可能生成一起奇奇怪怪的东西,因为这里对低维向量没有做出约束,
自编码器通过将图片转化为数值编码再还原回图片的过程,可能导致对训练数据过拟合。结果就是,对于未见过的低维编码,解码器重构的图片质量通常不佳。因此自编码器更多用于数据压缩.
自编码器不擅长图片生成是因为过拟合,那如果能够解决过拟合问题,不就能拿来生成图片了!
2.2 变分自编码器-VAE
Variational Autoencoders:迈向更鲁棒地生成
变分自编码器做的就是这么一件事:既然自编码器将图片编码为确定性的数值编码会导致过拟合,变分自编码器就将图片编码为一个具有随机性的概率分布,比如标准正态分布。 这样当模型训练好后,我们只要给解码器喂入采样自标准正态分布的低维向量,就能够生成较为“真实”的图片了。

因此,变分自编码器除了希望编码前和解码后的样本尽可能相似(MSE尽可能小),还希望用于解码的数据服从标准正态分布,也就是低维编码的分布和标准正态分布的KL散度尽可能小,损失函数加上这么一项约束。
l
o
s
s
=
∣
∣
x
−
x
1
∣
∣
2
+
K
L
[
N
(
μ
x
,
σ
x
)
,
N
(
0
,
1
)
)
]
=
∣
∣
x
−
d
(
z
)
∣
∣
2
+
K
L
[
N
(
μ
x
,
σ
x
)
,
N
(
0
,
1
)
)
]
loss = || x - x_1 ||^2 + KL[N(\mu_x, \sigma_x),N(0,1))] = ||x - d(z)||^2 + KL[N(\mu_x, \sigma_x),N(0,1))]
loss=∣∣x−x1∣∣2+KL[N(μx,σx),N(0,1))]=∣∣x−d(z)∣∣2+KL[N(μx,σx),N(0,1))]
变分自编码器中涉及到了从标准正态分布中进行采样,因此作者引入了一种参数化的技巧(也是为了误差能够反向传播),感兴趣的可以进一步了解。
此外,VQ-VAE、VQ-GAN 也是一些值得学习的工作。由于不影响对后续的理解,这里不再进行赘述。
变分自编码器减轻了自编码器过拟合的问题,也确实能够用来做图片的生成了,但是大家会发现用它生成图片通常会比较模糊。可以这样想一下,变分自编码器的编码器和解码器都是一个神经网络,编码过程和解码过程都是一步就到位了,一步到位可能带来的问题就是建模概率分布的能力有限/或者说能够对图片生成过程施加的约束是有限的/或者说“可控性”是比较低的。
2.3 去噪扩散概率模型-DDPM
慢工出细活,效果增强
既然变分自编码器一步到位的编解码方式可能导致生成图片的效果不太理想,DDPM就考虑拆成多步来做,它将编码过程和解码过程分解为多步:
编码过程
x
=
x
0
→
x
1
→
x
2
→
.
.
.
→
x
t
=
z
x = x_0 →x_1→x_2→...→x_t = z
x=x0→x1→x2→...→xt=z
解码过程
z
=
x
t
→
.
.
.
→
x
2
→
x
1
→
x
0
=
x
z = x_t →...→x_2→x_1→x_0 = x
z=xt→...→x2→x1→x0=x
因此,所谓的扩散模型由两个阶段构成
-
前向扩散过程,比如给定一张照片,不断(也就是多步)往图片上添加噪声,直到最后这样图片看上去什么都不是(就是个纯噪声)
-
反向去噪过程,给定噪声,不断执行去噪的这一操作,最终得到一张“真实好看”的照片
下图中从右往左就是前向扩散的过程,从左往右就是反向去噪的过程
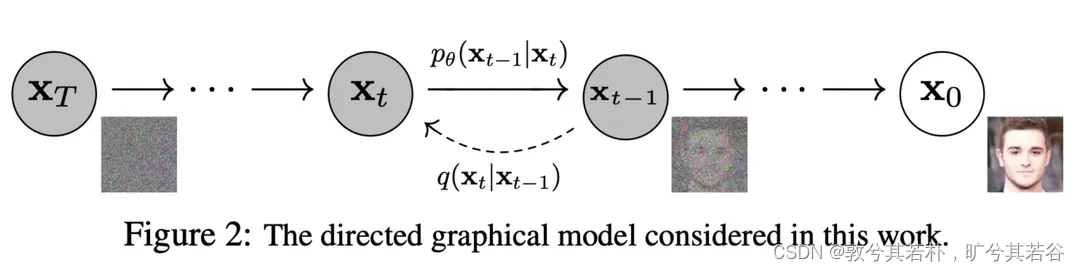
可以看到每一步的下标有一个,的范围从到,代表从数据集中采样出一张图片,前向过程在每一步从高斯分布中采样出噪声叠加到时刻的图像上,当足够大时,最终会得到一个各向同性的高斯分布(球形高斯分布,也就是各个方向方差都一样的多维高斯分布)。
引用一个大佬的比喻帮助大家理解:我们可以将扩散过程想象为建楼,其中随机噪声是砖瓦水泥等原材料,样本数据是高楼大厦,所以生成模型就是一支用原材料建设高楼大厦的施工队。这个过程肯定很难的,但俗话说“破坏容易建设难”,建楼你不会,拆楼你总会了吧?我们考虑将高楼大厦一步步地拆为砖瓦水泥的过程,当我们有了“拆楼”的中间过程后,我们知道拆楼的每一步是如何完成的,那反过来不就是建楼的一步?如果我们能学会两者之间的变换关系,那么从出发,反复地执行一步建楼的过程,最终不就能造出高楼大厦出来?
DDPM通过多步迭代生成得到图片缓解了变分自编码器生成图片模糊的问题,但是由于多步去噪过程需要对同一尺寸的图片数据进行操作,也就导致了越大的图片需要的计算资源越多(原来只要处理一次,现在有几步就要处理几次)。
2.4 潜在扩散模型-LDM
借助VAE来降本增效
既然DDPM在原始空间(像素级别的图片)进行扩散模型的训练(hundreds of GPU days)和采样比较费资源的,那我们就可以考虑把它降维后在latent space进行操作。因此Latent Diffusion Models的做法就是安排上一个自编码器来对原始图片进行降维,比如原来的图片是的512 * 512,降成6464后再来进行DDPM这一套流程,生成图片时则是通过扩散模型拿到6464大小的图片,再通过自编码器的解码器还原为512*512的图片。
2.5 Diffusion Transformers-DiT
当扩散模型遇到Transformer
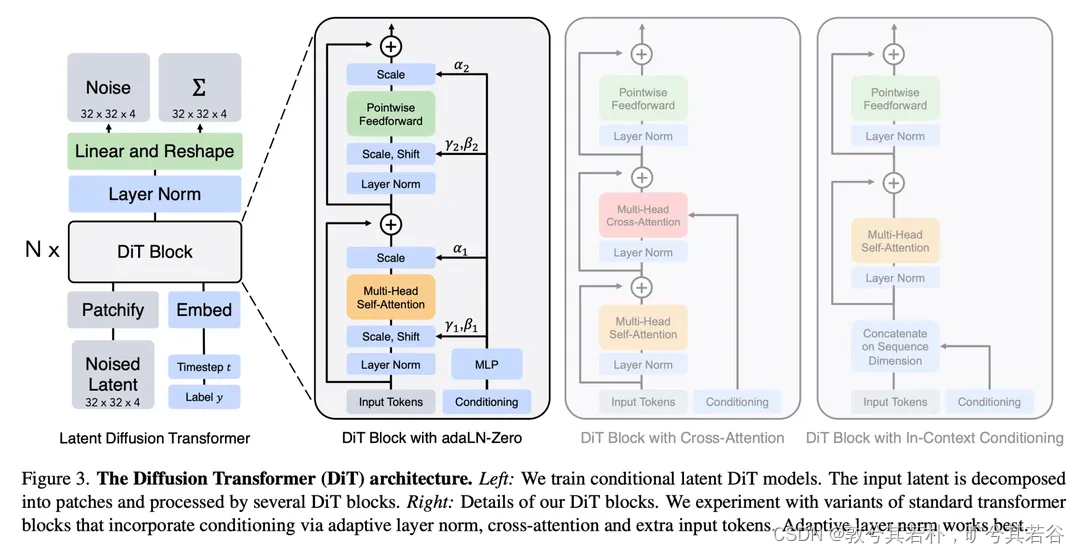
LDM的扩散模型使用了U-net这一网络结构,但这个结构会是最佳的吗?
参考其他领域或者任务的经验,比如去年火了一整年的大语言模型、多模态大模型绝大部分用的都是Transformer结构,相比于U-net,Transformer结构的Scaling能力(模型参数量越大,性能越强)更受大家认可。因此,DiT其实就是把LDM中的U-net替换成了Transformer,并在Vision Transformer模块的基础上做了略微的修改使得在图片生成过程能够接受一些额外的信息,比如时间步t,标签y。
2.6 Sora
视频生成的新纪元 先抛出我的观点:Sora就是改进的DiT。
而DiT本质上是 VAE编码器 + ViT + DDPM + VAE解码器;从OpenAI的技术报告体现出来的创新点我认为主要有两个方面:
- 改进VAE -> 时空编码器
- 改进DiT -> 不限制分辨率和时长
至于图像分块、Scaling transformers、视频re-captioning、视频编辑(SDEdit)这些其实都是已知的一些做法了。
3. 总结
本文以Sora文生视频的技术为切入点,从原理演进的角度逐步剖析了文生视频的演进方向和特点,最后讲述了Sora是如何做到文生视频的。有很多部分着重原理方向的概述,比如VAE、DDPM、LDM、DiT等,对细节部分描述的较少,感兴趣的同学可以自行学习。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











