






文章目录
I. 引言
A. 对AI和深度学习的简短介绍
当我们谈论人工智能(AI),我们指的是让机器模拟和实现人类的智慧行为的科学。AI的目标是创建一种可以理解、学习、适应和反应的先进技术。AI已经成为我们生活中的一个重要组成部分,从智能助手如Siri和Alexa,到推荐系统如Netflix和Amazon,再到自动驾驶汽车,AI的应用已经无处不在。
深度学习,作为AI的一个子集,是一种通过模拟人脑神经元的工作方式来学习复杂模式的方法。深度学习利用了神经网络,这些神经网络有多个隐层,可以自动学习数据中的有代表性特征。深度学习已经在许多领域取得了巨大的成功,包括图像识别、语音识别、自然语言处理等。
总的来说,AI和深度学习是推动我们社会进步的重要工具,它们正在改变我们的生活,并有望在未来继续为我们带来更多的创新和便利。
B. 对NLP(自然语言处理)的简短介绍
自然语言处理(Natural Language Processing,简称NLP)是人工智能和语言学领域的一个重要分支,它关注的是如何让计算机理解、解释和生成人类语言。换句话说,NLP的目标是让机器能够“读懂”和“生成”人类语言,从而与人进行有效的交流。
NLP涵盖了从基本的单词和句子处理(如词性标注、句法分析)到复杂的语言理解和生成任务(如机器翻译、自动摘要、情感分析、语音识别、对话系统等)。这些任务都需要机器理解语言的语法、语义、情境等复杂的人类语言特性。
近年来,随着深度学习技术的发展,NLP领域取得了巨大的进步。例如,基于Transformer的模型如BERT、GPT-3等已经在许多NLP任务上取得了超越人类的性能。而且,NLP的应用也越来越广泛,包括搜索引擎、智能助手、社交媒体分析、客户服务、教育等许多领域,都离不开NLP技术的支持。
C. 提出Transformer模型,阐述其重要性和在NLP中的应用
Transformer模型是在2017年由Google的研究员Vaswani等人在论文《Attention is All You Need》中提出的。他们提出了一个全新的模型架构——Transformer,这是一个完全依赖于注意力机制(Attention Mechanism)来捕捉序列中的全局依赖关系的模型,摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)的结构。
Transformer模型在自然语言处理(NLP)领域的重要性不言而喻。首先,它提供了一种更有效的方式来处理序列数据,通过自注意力机制,它能捕获序列中的长距离依赖关系,并且无需考虑序列的顺序,从而显著提高了处理速度。其次,由于其强大的表示学习能力,Transformer模型已经成为了许多NLP任务的基础模型,例如机器翻译,文本摘要,情感分析等。
此外,Transformer模型也孕育了一系列强大的预训练模型,如BERT, GPT-3等,这些模型已经在多个NLP任务上取得了人类水平的表现。总的来说,Transformer模型不仅改变了我们处理和理解自然语言的方式,也为NLP的未来发展打开了新的可能性。
II. Transformer模型的基本概念
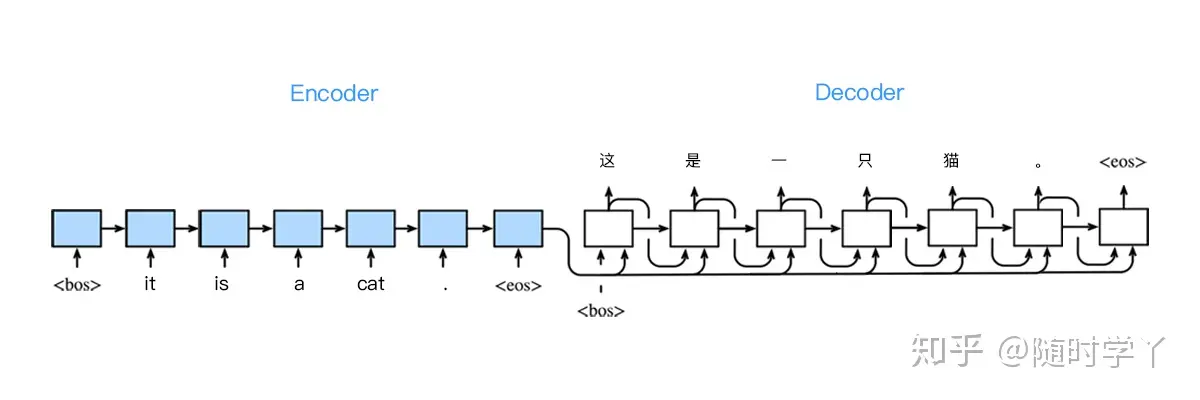
Transformer模型的主要构成部分包括编码器(Encoder)和解码器(Decoder)。编码器用于读取并理解输入数据,解码器则用于生成输出数据。每个编码器和解码器都由多个相同的层堆叠而成,而每一层又包括自注意力子层和前馈神经网络子层。
自注意力机制是Transformer模型的核心,它允许模型在处理序列数据时,对每个元素的处理都考虑到其他所有元素的信息,从而更好地理解序列中的上下文关系。此外,自注意力机制还具有并行计算的优点,大大提高了模型的训练效率。
A. 介绍Transformer模型的来源和发展
Transformer模型的诞生源于Google的一篇名为《Attention is All You Need》的论文,该论文于2017年发布。在这篇论文中,Google的研究员们提出了一种全新的网络架构——Transformer,摒弃了之前深度学习模型中常见的卷积神经网络(CNN)和循环神经网络(RNN)结构,仅使用自注意力(Self-Attention)机制来处理序列数据。
Transformer模型的提出,旨在解决RNN在处理长序列数据时遇到的困难,例如长期依赖问题和计算效率问题。Transformer模型通过自注意力机制,可以并行处理序列中的所有元素,同时捕捉到序列中的长距离依赖关系,大大提高了计算效率。
自从Transformer模型的提出以来,它已经引发了一场在自然语言处理(NLP)领域的革命。一系列基于Transformer的预训练模型相继被提出,如BERT、GPT-2、GPT-3、T5等,这些模型在多个NLP任务上取得了人类水平甚至超过人类的表现,不仅推动了NLP领域的发展,也在信息检索、机器翻译、情感分析、文本生成等多个应用领域发挥了巨大的作用。
B. 解释Transformer模型的基本概念,包括自注意力机制(Self-Attention)和位置编码(Positional Encoding)
- 自注意力机制(Self-Attention):
- 位置编码(Positional Encoding):
III. Transformer模型的详细结构
整体的transformer的结构如下图所示
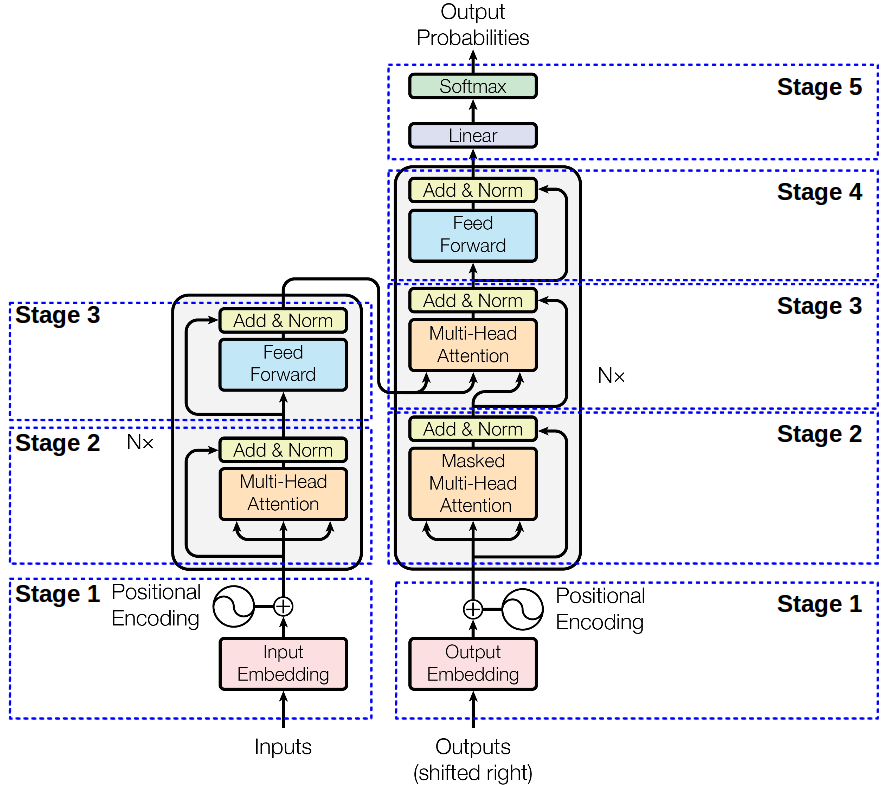
A. 详细解释Encoder-Decoder架构
Encoder-Decoder 通常称作 编码器-解码 具体实现方法,包含句子中特定位置信息的
维向量,这种编码没有整合进模型,而是用这个向量让每个词具有它在句子中的位置的信息transfomer的组成-残差连接和层归一化
|
|[7]|Transformer模型的位置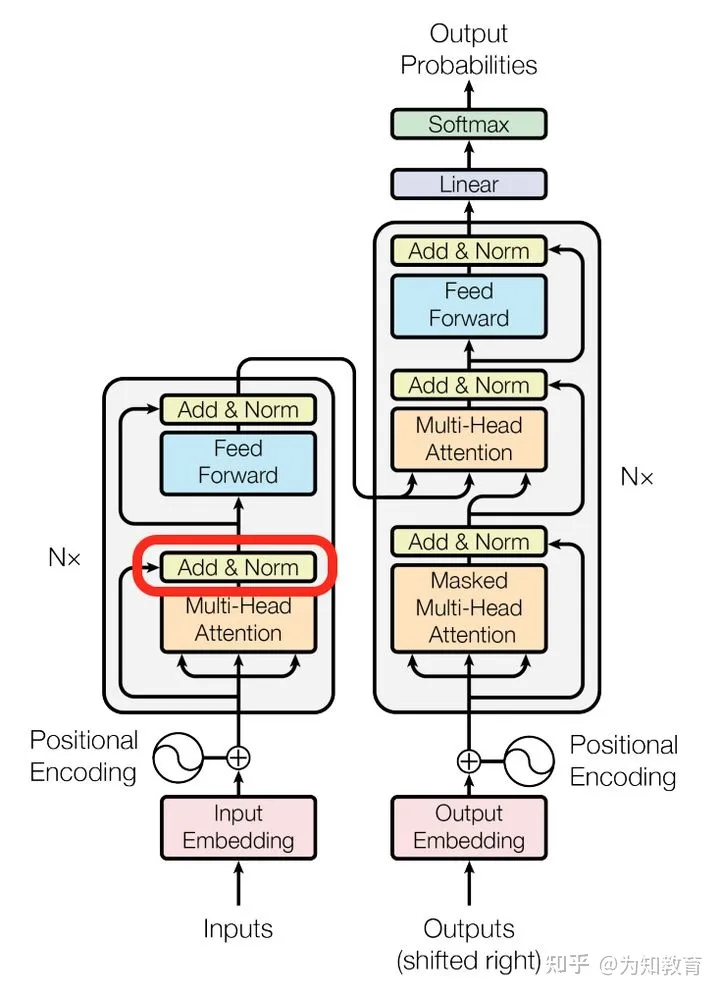 编码详解|https://zhuanlan.zhihu.com/p/10658transfomer的组成-残差连接和层归一化
编码详解|https://zhuanlan.zhihu.com/p/10658transfomer的组成-残差连接和层归一化
https://zhuanlan.zhihu.com/p/422247863|器,是深度学习中常见的模型框架,很多常见的应用都是利用编码-解码框架设计的,如:
- 无监督算法的 auto-encoding 就是利用编码-解码结构设计的。
- image caption 的应用也是利用 CNN-RNN 的编码-解码框架。
- 神经网络机器翻译 NMT 模型,就是 LSTM-LSTM 的编码-解码框架。
综合上述的应用,我们可以知道 Encoder-Decoder 并不是一个具体的模型,而是一个通用的框架。Encoder 和 Decoder 部分可以是任意文字,语音,图像,视频数据,模型可以是 CNN,RNN,LSTM,GRU,Attention 等等。所以,基于 Encoder-Decoder,我们可以设计出各种各样的模型。
上面提到的编码,就是将输入序列转化转化成一个固定长度向量。解码,就是讲之前生成的固定向量再转化出输出序列。
由此,Encoder-Decoder 有 2 点需要注意:
- 不管输入序列和输出序列长度是什么,中间的「向量 c」长度都是固定的,这也是它的一个缺陷。
不同的任务可以选择不同的编码器和解码器 (RNN,CNN,LSTM,GRU)。 - Encoder-Decoder 有一个比较显著的特征就是它是一个 End-to-End 的学习算法,以机器翻译为力,可以将法语翻译成英语。这样的模型也可以叫做 Seq2Seq。
B. 自注意力机制(Self-Attention)的深入理解和示例
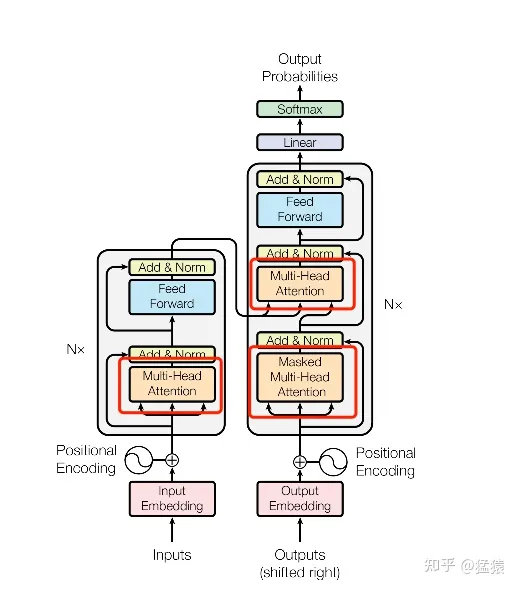
注意力机制 其实是源自于人对于外部信息的处理能力。由于人每一时刻接受的信息都是无比的庞大且复杂,远远超过人脑的处理能力,因此人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
自注意力机制 和注意力机制的区别就在于,注意力机制 的 查询和键是不同来源 的,例如,在Encoder-Decoder模型中,键是Encoder中的元素,而查询是Decoder中的元素。在中译英模型中,查询是中文单词特征,而键则是英文单词特征。而自注意力机制的查询和键则都是来自于同一组的元素,例如,在Encoder-Decoder模型中,查询和键都是Encoder中的元素,即查询和键都是中文特征,相互之间做注意力汇聚。也可以理解为同一句话中的词元或者同一张图像中不同的patch,这都是一组元素内部相互做注意力机制,因此,自注意力机制(self-attention)也被称为内部注意力机制(intra-attention)。
C. 位置编码的实现和作用
- 为什么需要位置编码?引入位置编码主要归因于两方面:
- 对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
I do not like the story of the movie, but I do like the cast.
I do like the story of the movie, but I do not like the cast.
上面两句话所使用的的单词完全一样,但是所表达的句意却截然相反。那么,引入词序信息有助于区别这两句话的意思。
-
Transformer模型抛弃了RNN、CNN作为序列学习的基本模型。我们知道,循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
-
具体实现方法,包含句子中特定位置信息的
维向量,这种编码没有整合进模型,而是用这个向量让每个词具有它在句子中的位置的信息
D. 阐述残差连接和层归一化的作用
其中Add代表了Residual Connection,是为了解决多层神经网络训练困难的问题,通过将一部分的前一层的信息无差的传递到下一层,可以有效的提升模型性能——因为对于有些层,我们并不确定其效果是不是正向的。加了残差连接之后,我们相当于将上一层的信息兵分两路,一部分通过我们的层进行变换,另一部分直接传入下一层,再将这两部分的结果进行相加作为下一层的输出。这样的话,其实可以达到这样的效果:我们通过残差连接之后,就算再不济也至少可以保留上一层的信息,这是一个非常巧妙的思路。
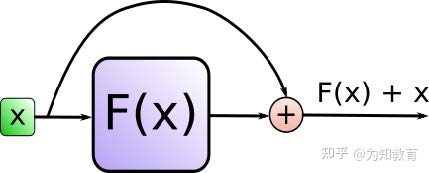
而Norm则代表了Layer Normalization,通过对层的激活值的归一化,可以加速模型的训练过程,使其更快的收敛
E. 介绍Feed Forward Neural Network在Transformer中的角色
FeedForward的输入是什么呢?是Multi-Head Attention的输出做了残差连接和Norm之后得数据,然后FeedForward做了两次线性线性变换,为的是更加深入的提取特征。

可以看出在每次线性变换都引入了非线性激活函数Relu,在Multi-Head Attention中,主要是进行矩阵乘法,即都是线性变换,而线性变换的学习能力不如非线性变换的学习能力强,FeedForward的计算公式如下:max相当于Relu

所以FeedForward的作用是:通过线性变换,先将数据映射到高纬度的空间再映射到低纬度的空间,提取了更深层次的特征
IV. Transformer模型的训练
A. 描述Transformer模型的训练过程和优化算法
有很多方法可以避免显存不足以及训练时间过长的方法,这篇文章的主要贡献就是介绍了这些方法的原理以及如何实现,具体包括以下几种方法:
- 梯度累积(Gradient Accumulation)
- 冻结(Freezing)
- 自动混合精度(Automatic Mixed Precision)
- 8位优化器(8-bit Optimizers)
- 梯度检查点(Gradient Checkpointing)
- 快速分词器(Fast Tokenizers)
- 动态填充(Dynamic Padding)
- 均匀动态填充(Uniform Dynamic Padding)
其中 1-5 是神经网络通用的方法,可以用在任何网络的性能优化上,6-8 是针对 NLP 领域的性能优化方法。
B. 介绍损失函数和评价指标
损失函数的设计较为简单,需要考虑输出的句子和真正的目标句子是否为同一句子。只需要使用一个交叉熵函数。有一点需要注意,由上一章数据处理可以看出,数据中含有大量的填充(补0),这些填充不能作为真正的输入来考虑,因此在损失函数的计算中,需要将这些部分屏蔽掉。
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def loss_function(real, pred):
# 对于mask,如果编码句子中出现了值为 0 的数据,则将其置 0
mask = tf.math.logical_not(tf.math.equal(real, 0))
# 输出句子和真正的句子计算交叉熵
loss_ = loss_object(real, pred)
# 将无效的交叉熵删除
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
# 返回平均值
return tf.reduce_mean(loss_)
同时,定义两个指标用于展示训练过程中的模型变化:
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
name='train_accuracy')
C. 介绍过拟合的问题以及如何防止(例如:Dropout、正则化)
V. Transformer模型的应用
Transformer 是构建世界上大多数最先进模型的主要架构之一。它在各个领域取得了巨大成功,包括但不限于以下任务:语音识别到文本转换、机器翻译、文本生成、释义、问答和情感分析。这些任务中涌现出了一些最优秀和最著名的模型。
A. 详述Transformer在机器翻译中的应用
B. 介绍Transformer在文本摘要、情感分析等NLP任务中的应用
C. 提及基于Transformer的模型,如BERT、GPT-3等
VI. Transformer模型的挑战和未来发展
A. 讨论Transformer模型的局限性和挑战
与基于 RNN 的 seq2seq 模型相比,尽管 Transformer 模型在自然语言处理领域取得了巨大的成功,然而,其本身也存在一些局限性,主要包括以下几个方面:
-
高计算资源需求: Transformer 模型通常需要大量的计算资源进行训练和推理。由于模型参数众多且复杂,需要显著的计算能力和存储资源来支持其运行,从而使得在资源受限的环境下应用 Transformer 模型变得相对困难。
-
长文本处理困难: 在某些特定的场景下,由于 Transformer 模型中自注意力机制的特性,其对于长文本的处理存在一定的困难。随着文本长度的增加,模型的计算复杂度和存储需求也会显著增加。因此,对于超长文本的处理,Transformer 模型可能会面临性能下降或无法处理的问题。
-
缺乏实际推理机制: 在实际的业务场景中,Transformer 模型通常是通过在大规模数据上进行预训练,然后在特定任务上进行微调来实现高性能,从而使得模型在实际推理过程中对于新领域或特定任务的适应性有限。因此,对于新领域或特定任务,我们往往需要进行额外的训练或调整,以提高模型的性能。
-
对训练数据的依赖性: Transformer 模型在预训练阶段需要大量的无标签数据进行训练,这使得对于资源受限或特定领域数据稀缺的情况下应用 Transformer 模型变得困难。此外,模型对于训练数据的质量和多样性也有一定的依赖性,不同质量和领域的数据可能会对模型的性能产生影响。
-
缺乏常识推理和推理能力: 尽管 Transformer 模型在语言生成和理解任务上取得了显著进展,但其在常识推理和推理能力方面仍存在一定的局限性。模型在处理复杂推理、逻辑推断和抽象推理等任务时可能表现不佳,需要进一步的研究和改进。
尽管存在这些局限性,Transformer 模型仍然是当前最成功和最先进的自然语言处理模型之一,为许多 NLP 任务提供了强大的解决方案。未来的研究和发展努力将有助于克服这些局限性,并推进自然语言处理领域的进一步发展。
VII. 附录
| 序号 | 标题 | 链接 |
|---|---|---|
| [1] | 《Attention is All You Need》 | https://arxiv.org/pdf/1706.03762.pdf |
| [2] | 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》 | https://arxiv.org/pdf/1810.04805.pdf |
| [3] | 拆 Transformer 系列一:Encoder-Decoder 模型架构详解 | https://zhuanlan.zhihu.com/p/109585084 |
| [4] | 拆 Transformer 系列二:Transformer 模型结构详解 | https://zhuanlan.zhihu.com/p/338817680 |
| [5] | Transformer:注意力机制(attention)和自注意力机制(self-attention)的学习总结 | https://blog.youkuaiyun.com/weixin_43610114/article/details/126684999 |
| [6] | 一文读懂Transformer模型的位置编码 | https://zhuanlan.zhihu.com/p/106644634 |
| [7] | transfomer的组成-残差连接和层归一化 | https://zhuanlan.zhihu.com/p/422247863 |
| [8] | Transformer学习笔记二:Self-Attention(自注意力机制) | https://zhuanlan.zhihu.com/p/455399791 |
| [9] | 对Transformer中FeedForward层的理解 | https://blog.youkuaiyun.com/weixin_51756104/article/details/127250190 |


















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











