







 本文详细解析了Java线程池构造方法的七个参数,探讨了线程复用、饱和策略,并通过实例演示了`newCachedThreadPool`和`newFixedThreadPool`的区别。重点讲解了ScheduledExecutorService的使用,以及Future接口在异步计算中的应用。
本文详细解析了Java线程池构造方法的七个参数,探讨了线程复用、饱和策略,并通过实例演示了`newCachedThreadPool`和`newFixedThreadPool`的区别。重点讲解了ScheduledExecutorService的使用,以及Future接口在异步计算中的应用。
构造方法 七个参数:
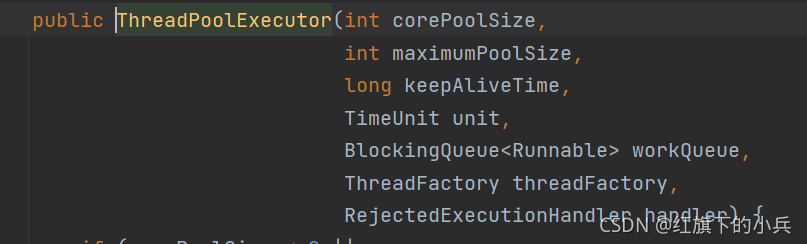
构造方法: int corePoolSize ->核心线程数量(允许刚开始创建线程的数量) int maximumPoolSize ->最大线程数量 long keepAliveTime ->最大空闲时间 TimeUnit unit ->时间单位 BlockingQueue<Runnable> workQueue ->任务列队(临时缓冲区) ThreadFactory threadFactory ->线程工厂,是一个接口(自定义创建线程) RejectedExecutionHandler handler ->饱和处理机制
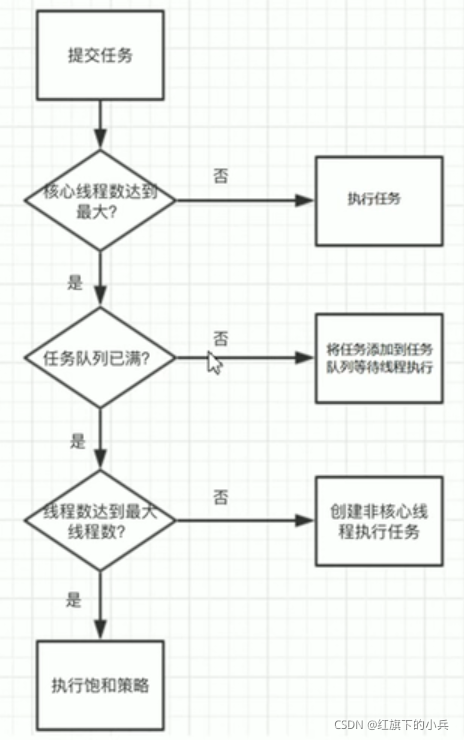
当线程数量达到核心线程数量的时候,如果再有任务提交到线程池里边,他不会立马创建新线程,它会先把你的任务加到任务队列里边去,如果任务队列也满了,它会按照设置的最大线程数量去创建新的线程,但是前提必须要保证:当前运行的线程没有达到最大线程数量,且任务队列已经满了。
包和处理机制:
达到核心线程的数量,且任务队列已经满了,且已经达到了最大线程数量,此时线程池处于一个饱和状态,饱和之后的处理策略。
一个形象的例子:

线程池工作流程:
自定义线程池 - 参数设计

(1) 核心线程数

(2)任务队列的长度

(3)最大线程数量

(4)最大空闲时间

ExecutorService
java内置的线程池接口。
常用方法:
(1)void shutdow()
启动一次顺序关闭,执行以前提交的任务,但不接受新任务(无法向线程池提交新任务)。
(2)List<Runnable> shutdownNow();
停止所有正在执行的任务,暂停处理正在等待的任务,并返回等待执行的任务列表。
(3)<T> Future<T> submit(Callable<T> task);
执行带返回值的任务,返回一个Future对象。
(4)Future<?> submit(Runnable task); 执行Runnable任务,并返回一个表示该任务的Future。
(5)<T> Future<T> submit(Runnable task, T result);
执行Runnable任务,并返回一个表示该任务的Future。


创建线程池:
三种方式创建线程池:
方式一:Executors.newCachedThreadPool( )
方式二:Executors.newFixedThreadPool(int nThreads)
方式三:Executors.newSingleThreadExecutor( )
先来看下:
1、newCachedThreadPool()
创建线程池对象,可实现线程的复用,不会创建多余的线程。
不足:这种方式虽然可以根据业务场景自动的扩展线程数来处理我们的业务,但是最多需要多少个线程同时处理缺是我们无法控制的;
优点:如果当第二个任务开始,第一个任务已经执行结束,那么第二个任务会复用第一个任务创建的线程,并不会重新创建新的线程,提高了线程的复用率;
public class pool {
public static void main(String[] args) {
emptyParam();
}
/**
* ToDo ctrl+alt+m -> 提取一个方法
* 无参构造案例
*/
private static void emptyParam() {
// 创建获取线程池对象
ExecutorService es = Executors.newCachedThreadPool();
// 提交多个个任务,到线程池里边
for (int i = 0; i < 5; i++) {
es.submit(new MyRunnable(i));
}
}
// 任务类,包含任务编号
class MyRunnable implements Runnable{
public int id;
public MyRunnable(int id) {
this.id = id;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"\t线程执行了任务,任务编号为:"+this.id);
}
}
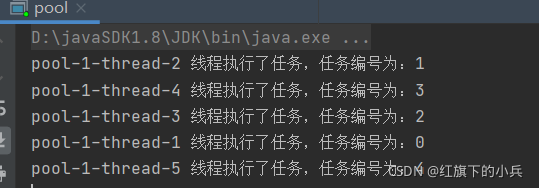
从上边结果来看,怎么没实现线程复用呢,而是创建了5个线程?我猜测原因是:for循环非常快,每一次提交任务,上一次还每执行完,这一次的又提交过来了,所以,每次都会创建新的线程来执行提交过来的任务。
模拟实际业务,在提交任务之前加了1秒等待,再看下效果:
// 提交多个个任务,到线程池里边
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
es.submit(new MyRunnable(i));
}
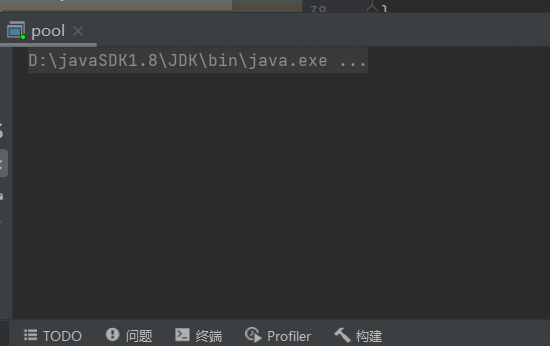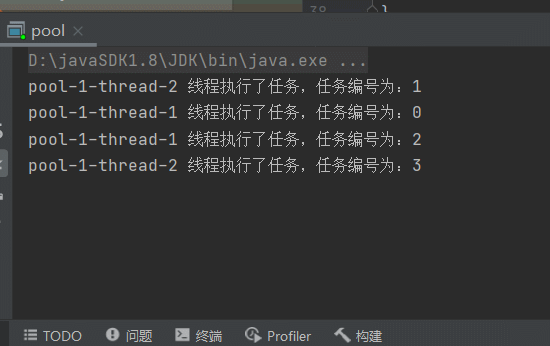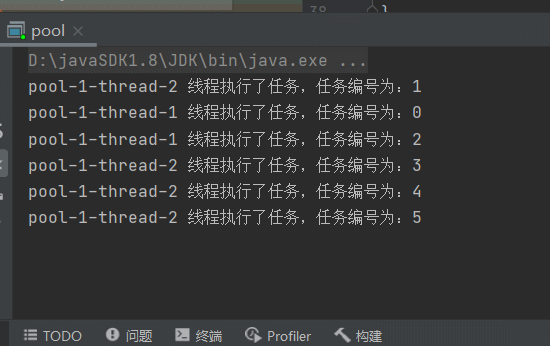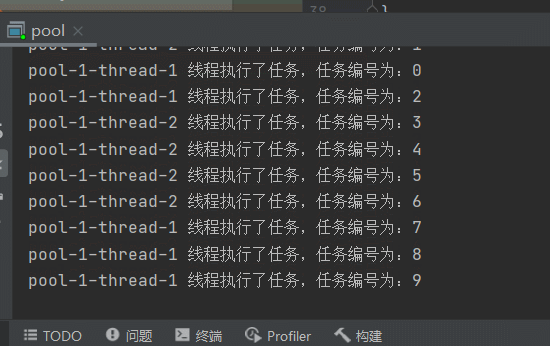
很明显,线程变成一个了,因为有延迟1秒,所以提交任务之后,执行任务,执行完时,第二个任务还没提交过来,等提交过来时,上一个线程早已经执行完毕,它会复用上一个线程,所以一直是:pool-1-thread-1线程在执行。
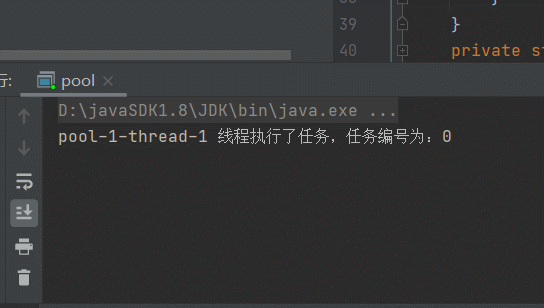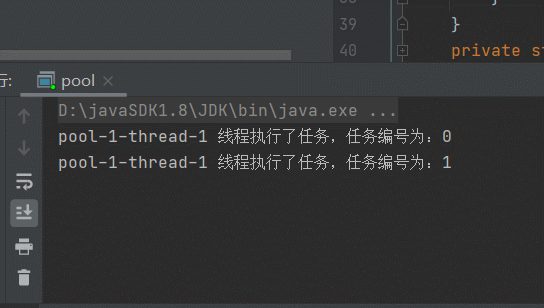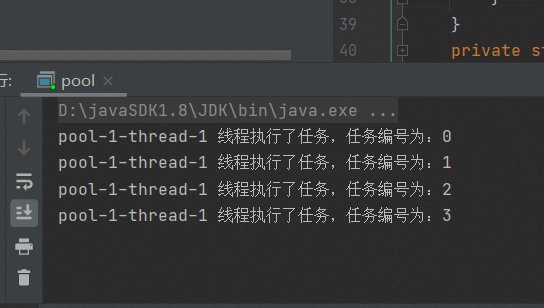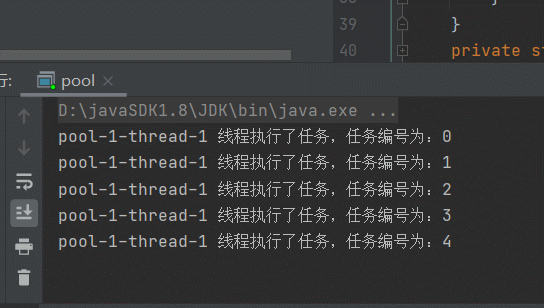
再来看另一种情况,上边是任务执行的时间一样,当任务的执行时间不一样时,效果如下,简单模拟任务执行的时间长短:
// 提交多个个任务,到线程池里边
for (int i = 0; i < 10; i++) {
try {
Thread.sleep(i%2 == 0 ? 1000 : 0); // 简单模拟下任务的执行时间不同
} catch (InterruptedException e) {
e.printStackTrace();
}
es.submit(new MyRunnable(i));
}
下边效果很明显,会创建2个线程,因为for循环时,会有延迟,并且会有2个延迟时间0秒和1秒, 有一个线程执行很快,每次执行完,下一个任务就会复用这个线程。
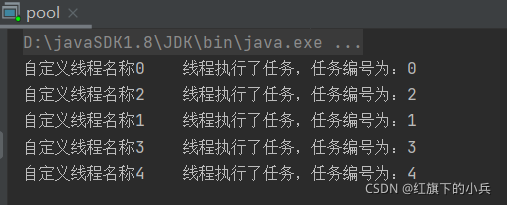
有参,主要是可以自定义线程名称:
public class pool {
public static void main(String[] args) {
hasParams();
}
private static void hasParams() {
/**
* ToDo ctrl+p 查看一个方法的参数列表
* 有参情况,通过匿名内部类来实现
*/
ExecutorService es = Executors.newCachedThreadPool(new ThreadFactory() {
int i = 0;
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "自定义线程名称"+i++);
}
});
// 提交多个个任务,到线程池里边
for (int i = 0; i < 5; i++) {
es.submit(new MyRunnable(i));
}
}
}
// 任务类,包含任务编号
class MyRunnable implements Runnable{
public int id;
public MyRunnable(int id) {
this.id = id;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"\t线程执行了任务,任务编号为:"+this.id);
}
}
2、Executors.newFixedThreadPool(int nThreads)
这种方式可以指定线程池中的线程数,举个栗子,如果一间澡堂子最大只能容纳20个人同时洗澡,那么后面来的人只能在外面排队等待。
优点:newFixedThreadPool的线程数是可以进行控制的,因此我们可以通过控制最大线程来使我们的服务器打到最大的使用率,同事又可以保证及时流量突然增大也不会占用服务器过多的资源。
ScheduledExecutorService
延迟执行或者重复执行任务。
接口
实际开发中可能会有延迟提交任务,或者每隔多长时间执行任务的情况,此时ExecutorService线程池满足不了我们的需求了,此时可以使用ScheduledExecutorService

2、ScheduledExecutorService 常见方法

3、两个延时方法的区别:
schedukeAtfixedRate() 它是每间隔多少时间执行一次任务;
scheduleWithFixedDelay() 它是任务执行结束之后,到下一个任务开始执行之间的时间间隔;
4、测试
(1)newScheduledThreadPool()
下边main线程会先执行,2秒之后,pool-1-thread-1 线程才执行。
es.schedule() 方法 ,只会执行一次
public class schedulePool {
public static void main(String[] args) {
// 创建一个延时线程对象
ScheduledExecutorService es = Executors.newScheduledThreadPool(2);
/**
* 创建1个或多个任务对象,提交任务,且每个任务 延迟执行
* 延迟1秒
* 单位秒
*/
// 单个任务提交
es.schedule(new MyRunnables(1), 2, TimeUnit.SECONDS);
// 多个任务提交
// for(int i = 0; i < 5; i++){es.schedule(new MyRunnables(i), 2, TimeUnit.SECONDS);}
System.out.println(Thread.currentThread().getName()+"线程执行了");
}
}
class MyRunnables implements Runnable {
public int id;
public MyRunnables(int count) {
this.id = count;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"线程执行了"+this.id+"任务");
}
}
(2)es.scheduleAtFixedRate() 方法 每隔多长时间执行一次任务,无限执行。
public class schedulePool {
public static void main(String[] args) {
extractedFixed();
}
private static void extractedFixed() {
// 创建线程池对象
ScheduledExecutorService es = Executors.newScheduledThreadPool(2);
// 补充一种创建线程池对象
// ScheduledThreadPoolExecutor scheduled = new ScheduledThreadPoolExecutor(2);
/**
* 创建1个任务对象,提交任务,且开始1秒之后执行第一个任务,之后每隔2秒执行一次任务
* 单位秒
*/
es.scheduleAtFixedRate(new MyRunnables(1), 1, 2, TimeUnit.SECONDS);
System.out.println(Thread.currentThread().getName()+"线程执行了");
}
}
class MyRunnables implements Runnable {
public int id;
public MyRunnables(int count) {
this.id = count;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"线程执行了"+this.id+"任务");
}
}
异步计算结果Future

常用方法如下:
(1)boolean cancel(boolean mayInterruptIfRunning); 试图取消对此任务的执行。
(2)V get()
等待计算完成,然后获取其结果。
(3)V get(long timeout, TimeUtil util)![]()
(4)boolean isCancelled()
如果在任务正常完成前将其取消,则返回true。
(5)boolean isDone()
如果任务完成,则返回true。
总结:
线程池的作用主要是为了提升系统的性能以及使用率。文章刚开始就提到,如果我们使用最简单的方式创建线程,如果用户量比较大,那么就会产生很多创建和销毁线程的动作,这会导致服务器在创建和销毁线程上消耗的性能可能要比处理实际业务花费的时间和性能更多。线程池就是为了解决这种这种问题而出现的。
同样思想的设计还有很多,比如数据库连接池,由于频繁的连接数据库,然而创建连接是一个很消耗性能的事情,所有数据库连接池就出现了。

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









