







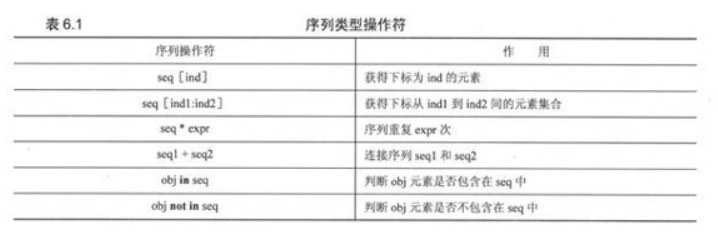
序列:
操作符:
-
innot in成员关系操作符, 判定obj在不在序列中
-
+连接两个序列
-
*将序列重复n次
-
[]切片, 前头讲过了
迭代器
python中迭代器的定义:
迭代器是指用iter(obj)函数返回的对象(实例)
迭代器可以用next(it) 函数获取可迭代对象的数据
两个重要函数:
-
iter(iterable) 从可迭代对象中返回一个迭代器(初始化为指向首元素),iterable必须是一个能提供一个迭代器的对象
一个支持迭代器的类必须有俩方法:
__iter()___next()__具体实现将在后头学习
-
next(iterator) 从iter中获取当前指向的元素, 并自动++
如果无法获取当前元素, 则返回stopIteration异常
几个简单的例子
tuple1 = (11, 22, 33, 44, 55, 66, 77, 88, 99)
tupleIter = iter(tuple1)
for i in range(0, len(tuple1), 1):
print("%d : %d" % (i, next(tupleIter)))
0 : 11
1 : 22
2 : 33
3 : 44
4 : 55
5 : 66
6 : 77
7 : 88
8 : 99
迭代器也可以丢进for中进行遍历:
tuple1 = (11, 22, 33, 44, 55, 66, 77, 88, 99)
tupleIter = iter(tuple1)
for i in tupleIter:
print(i)
print(next(tupleIter))
被for完成的iter会指向尾元素的下一个位置(尾指针), 此时如果再调用就会引发stopIteration异常
11
22
33
44
55
66
77
88
99Traceback (most recent call last):
File “d:\Visual Studio Code\Project\Python\main.py”, line 33, in
print(next(tupleIter))
StopIteration
另一种是直接使用异常判断进行遍历:
tuple1 = (11, 22, 33, 44, 55, 66, 77, 88, 99)
while True :
try:
print(next(tupleIter))
except StopIteration:
break
print("End...")
11
22
33
44
55
66
77
88
99
End…
其余部分直接参考这里, 反正最重要的还是要手撸一遍
https://www.runoob.com/python3/python3-iterator-generator.html
工厂函数
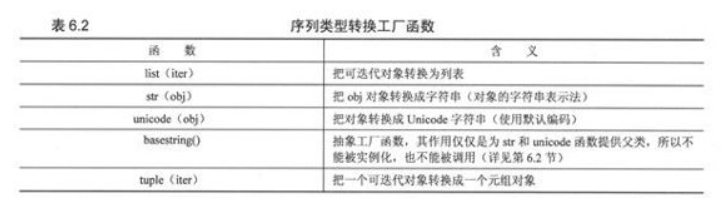
len(seq) 返回序列的长度
max(x) 返回序列的最大值的元素
min(x) 返回序列的最小值的元素
sum(x) 返回序列中所有元素的和
any(x) 真值测试,如果列表中其中一个值为真值则返回True
all(x) 真值测试,如果列表中所有值为真值则返回True
reversed(seq) 返回反向顺序的迭代器对象
sorted(iterable, key=None, reverse=False) 返回已排序的列表
相关的具体用法即时百度
字符串:
编码
从web 或 本地文件中读取数据时都会涉及到编码问题
所以这一部分还是蛮重要的
python3 默认采用Unicode编码, 所以支持多语言
当从web 或 本地文件中读写数据时, 涉及到str转换为以字节为单位的bytes类型
-
byte类型:
与str类型相似, 只不过在前头多个
b
-
编码 & 解码:
使用
encode()&decode()通常中文使用
utf-8, 纯英文使用ascii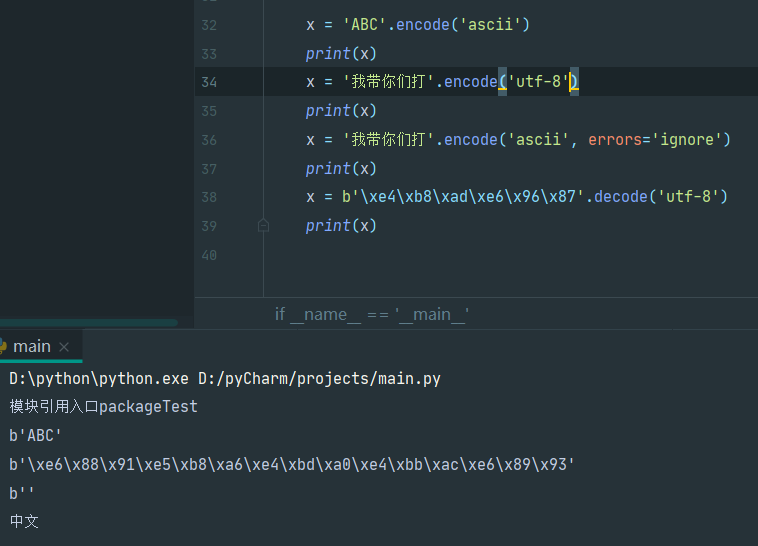
如果decode()中有无法解码的字节, 则会报错
可以使用
error='ignore'忽略
格式化输出:
printf()风格
前头讲过了:
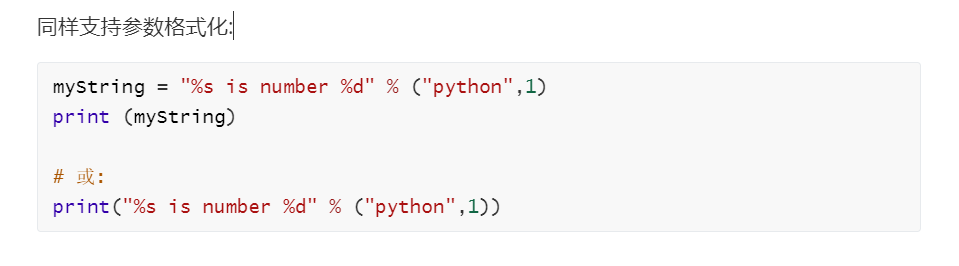
其他风格:


其中format为比较新的函数, 未来会更多的时候用format格式, 所以推荐使用format()
print常用的格式化:
两个比较常用的参数:
-
end:
print默认结尾为
\n, 即end='\n'修改可变更结尾符
-
seq:
print分隔符, 缺省情况为seq=
' '修改可变更分隔符
字符串CURD:
创建:
与其他类型相同
使用
""或''都可以
访问:
-
之前的切片
-
C风格的
[]下标访问alphabate = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" for i in range(10): print(alphabate[i:i+5])ABCDE
BCDEF
CDEFG
DEFGH
EFGHI
FGHIJ
GHIJK
HIJKL
IJKLM
JKLMN
修改:
字符串本身相当于char* const , 即指向const string 的指针, 内容本身不能被修改!
任何对字符串的改动都会引发报错
-
整体赋值
-
使用切片+拼接部分修改
alphabate = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" alphabate=alphabate[0::3] print(alphabate)ADGJMPSVY
-
由于string修改方面较为困难, 所以使用正则还是比较方便的选择
详见正则表达式章节
删除:
-
赋个空串
'' -
del
del删除之后, 编译器就根本不认这个标识符了:
alphabate = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" del(alphabate) print(alphabate)Traceback (most recent call last):
File “d:\Visual Studio Code\Project\Python\main.py”, line 35, in
print(alphabate)
NameError: name ‘alphabate’ is not defined
字符串操作符:
-
支持C++
string类的操作符
-
切片的正&反向索引:
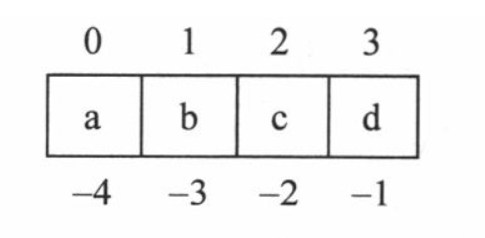
可以理解为字符串为循环链表, 尾元素为首元素index-1=0-1=-1
所以反向迭代通常这样写:
for i in range(-1, -len(s)-1, -1):
print(s[i])
alphabate = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
for i in range(-1, -len(alphabate)-1, -1):
print(alphabate[i], end="")
ZYXWVUTSRQPONMLKJIHGFEDCBA
- 成员操作符
就是in & not in
之前讲过了
alphabate = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
print("A" in alphabate)
print("a" in alphabate)
True
False
-
原始字符串
前头多加个
r就是了 -
Unicode字符串
前头多加个
u
常用字符串操作函数:
-
len()
-
max() & min()
-
enumerate()
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
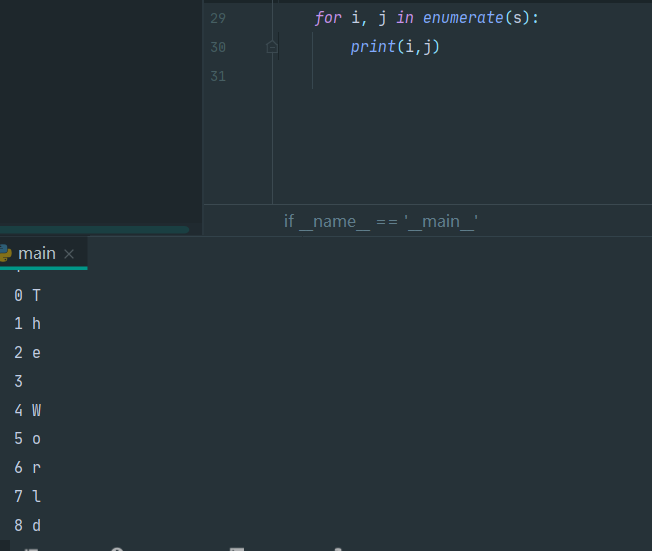
这玩意挺特殊的, 可以理解为一堆tuple组成的list, 每个tuple都是下标+对应的string元素:
alphabate = "WDNMD"
temp=enumerate(alphabate)
print(type(temp))
for i in temp:
print(i)
<class ‘enumerate’>
(0, ‘W’)
(1, ‘D’)
(2, ‘N’)
(3, ‘M’)
(4, ‘D’)
-
zip()
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换
具体使用:
https://www.runoob.com/python3/python3-func-zip.html
其他的字符串内建函数直接现查现用
字符串特性:
三引号
三引号中的内容所见即所得
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的
print("""What you see
is
what you get
""")
注意, 三引号换行头的空格也会被算在内
What you see
is
what you get
不可变性:
字符串本身相当于char* const , 即指向const string 的指针, 内容本身不能被修改! 这一点与C++不同
任何对字符串的改动都会引发报错
alphabate = "WDNMD"
alphabate[1]='P'
print(alphabate)
Traceback (most recent call last):
File “d:\Visual Studio Code\Project\Python\main.py”, line 30, in
alphabate[1]=‘P’
TypeError: ‘str’ object does not support item assignment
如果需要部分修改字符串, 则需要在原有的基础上构建新串
列表List
list逻辑上可以理解为数组, 只不过比C++更为自由, 支持各种类型的数据
List の CURD
-
创建 & 访问与string差不多
-
修改:
-
根据下标直接赋值:
-
使用append附加在末尾
temp = [1,2,3,4,5] print(temp) temp[1]="W" print(temp) temp.append("WDNMD") print(temp)[1, 2, 3, 4, 5]
[1, ‘W’, 3, 4, 5]
[1, ‘W’, 3, 4, 5, ‘WDNMD’]
- 删除:
-
根据下标直接del
-
pop([index])弹出
-
remove(index)删除
temp = [1,2,3,4,5] del(temp[1]) print(temp) temp.pop(1) print(temp) temp.remove(1) print(temp)[1, 3, 4, 5]
[1, 4, 5]
[4, 5]
操作符 & 内建函数
基本上与String相同
不多做介绍了
List の 特殊属性:
List相当于一个队列
而后就懂了吧
元组:
也基本和string 相似
元组具有不可变性
但是元组内部的元素是可修改的
关于tuple与list
tuple可以看做是struct, list可以看做是数组
前者整体上不可变, 但内部数据可修改, 后者整体上可修改
浅拷贝 & 深拷贝
这种情况会发生浅拷贝
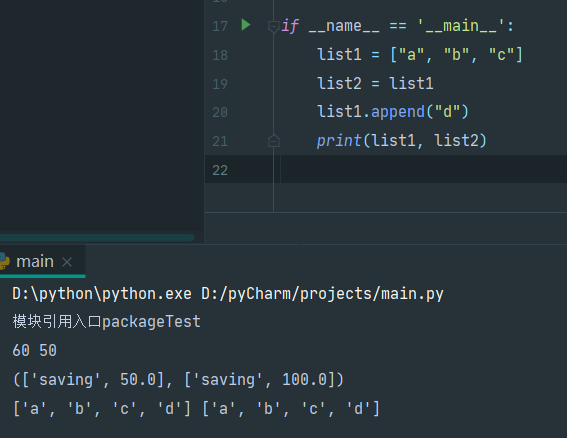
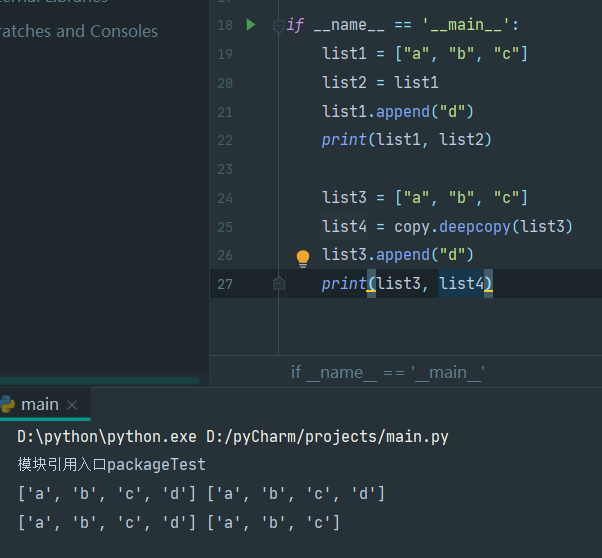
使用copy.deepcopy()函数进行深拷贝

















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









