







 该博客探讨了RNN在文本生成任务中的应用,对比了单向和双向RNN的效果。实验显示,双向RNN相比单向RNN在准确率上有提升,但存在过拟合问题。通过学习曲线分析,提出了LSTM作为防止过拟合的解决方案,并介绍了数据预处理和模型构建的过程。
该博客探讨了RNN在文本生成任务中的应用,对比了单向和双向RNN的效果。实验显示,双向RNN相比单向RNN在准确率上有提升,但存在过拟合问题。通过学习曲线分析,提出了LSTM作为防止过拟合的解决方案,并介绍了数据预处理和模型构建的过程。
模型建立
embedding_dim = 16
batch_size = 512
single_rnn_model = keras.models.Sequential([
# 1. define matrix: [vocab_size, embedding_dim]
# 2. [1,2,3,4..], max_length * embedding_dim
# 3. batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim,
input_length = max_length),
# rnn return_sequences 返回的最后一步的输出还是所有输出 false最后一步输出
keras.layers.SimpleRNN(units = 64, return_sequences = False),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
single_rnn_model.summary()
single_rnn_model.compile(optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy'])

训练
history_single_rnn = single_rnn_model.fit(
train_data, train_labels,
epochs = 30,
batch_size = batch_size,
validation_split = 0.2)

学习曲线
def plot_learning_curves(history, label, epochs, min_value, max_value):
data = {}
data[label] = history.history[label]
data['val_'+label] = history.history['val_'+label]
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()
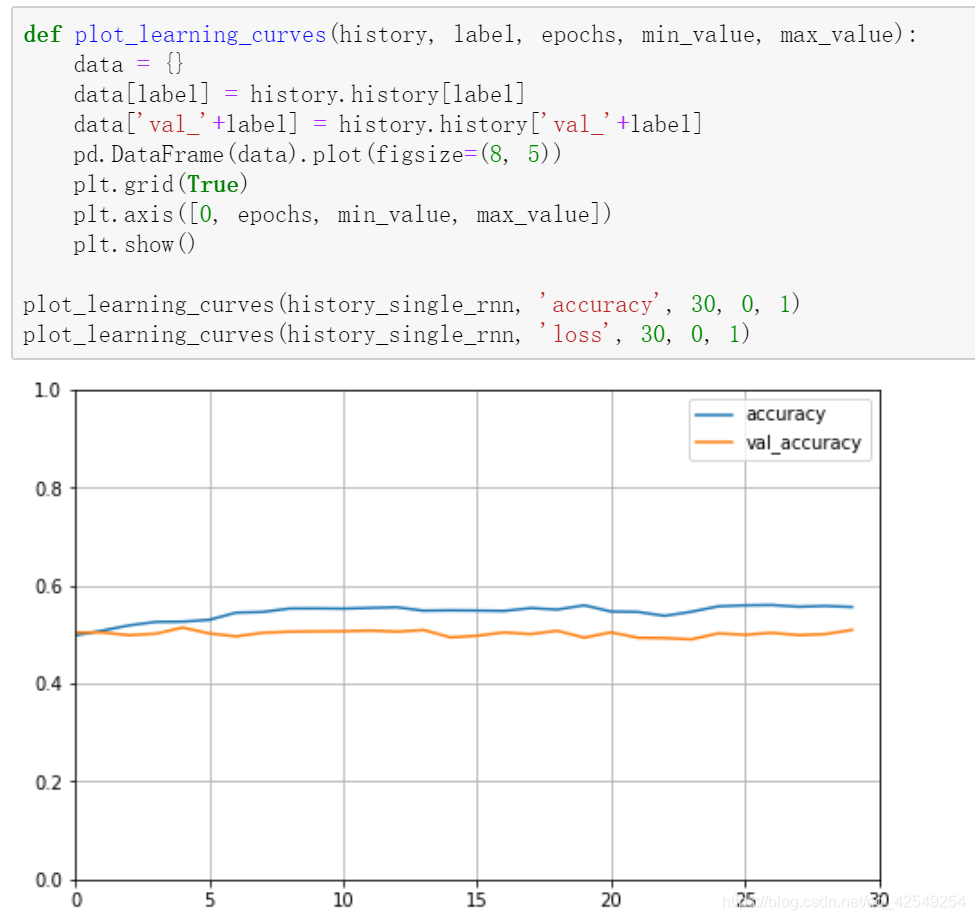
plot_learning_curves(history_single_rnn, 'acc', 30, 0, 1)
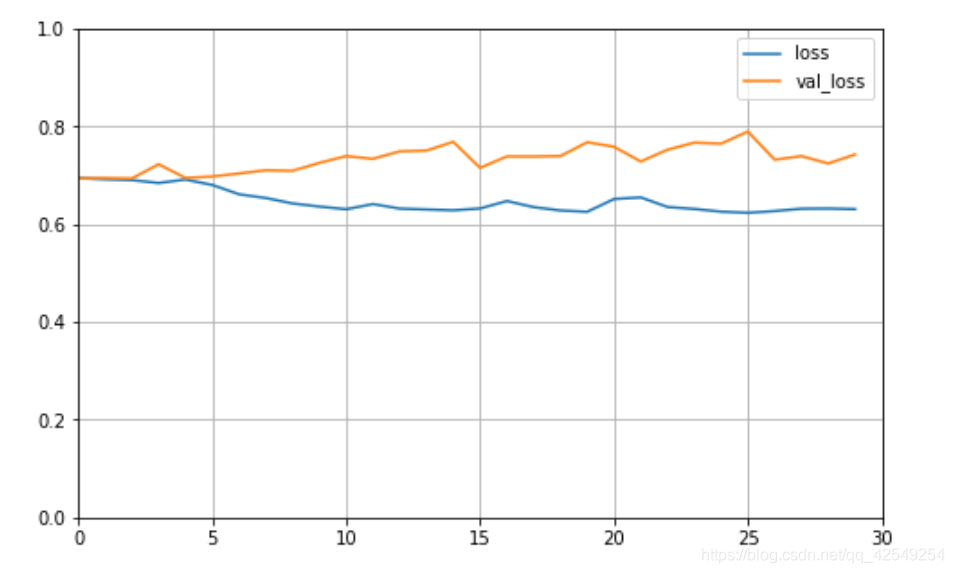
plot_learning_curves(history_single_rnn, 'loss', 30, 0, 1)
测试
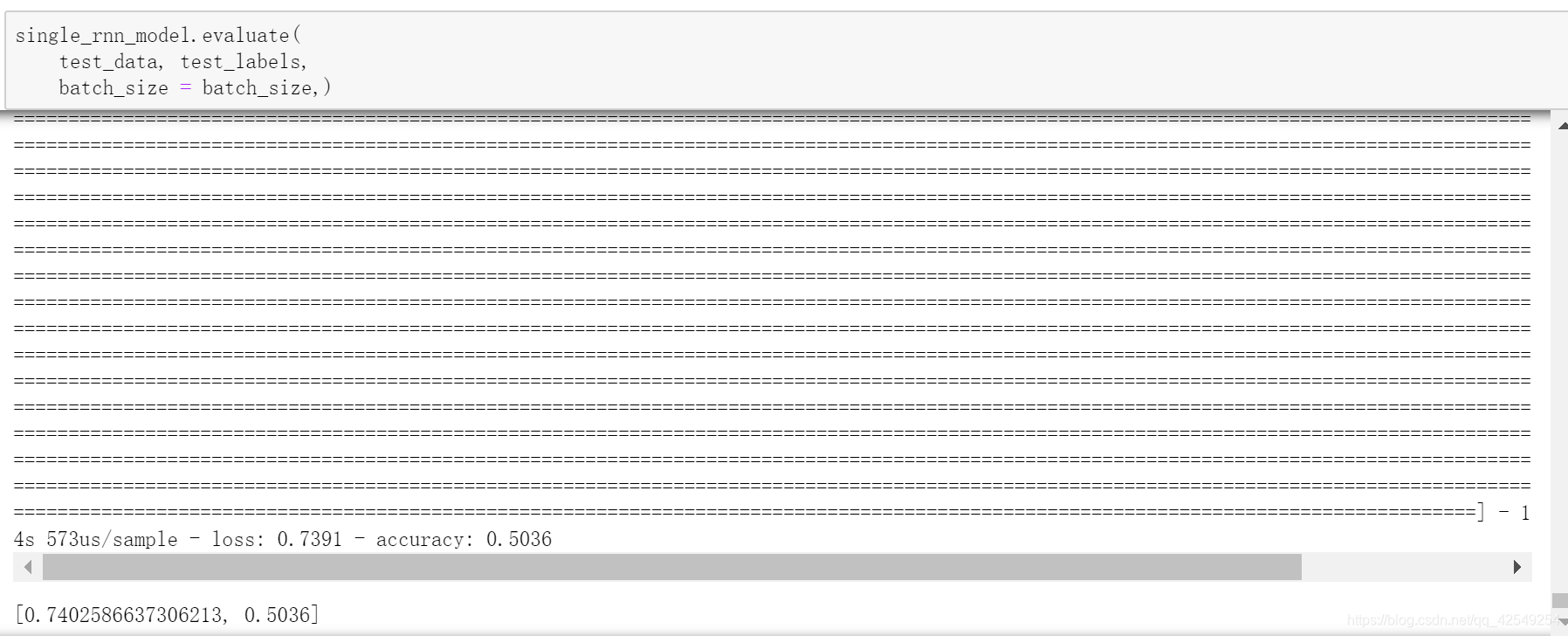
准确率0.5036,上面采用的是单向rnn,如果采用双向rnn是什么效果呢?
双向rnn模型
embedding_dim = 16
batch_size = 512
model = keras.models.Sequential([
# 1. define matrix: [vocab_size, embedding_dim]
# 2. [1,2,3,4..], max_length * embedding_dim
# 3. batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim,
input_length = max_length),
# 双向rnn封装
keras.layers.Bidirectional(
keras.layers.SimpleRNN(
# 设置为true 因为要输入下一层,不是单个序列
units = 64, return_sequences = True)),
# 多层双向rnn
keras.layers.Bidirectional(
keras.layers.SimpleRNN(
units = 64, return_sequences = False)),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
model.summary()
model.compile(optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy'])
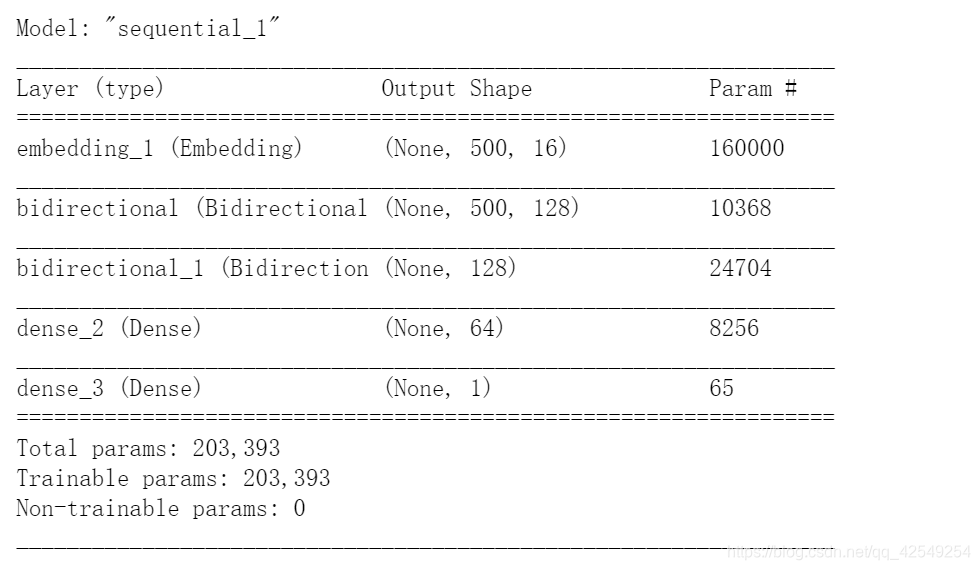
双向rnn训练
history = model.fit(
train_data, train_labels,
epochs = 30,
batch_size = batch_size,
validation_split = 0.2)

准确率要好一点
双向rnn学习曲线
plot_learning_curves(history, 'acc', 30, 0, 1)
plot_learning_curves(history, 'loss', 30, 0, 3.8)
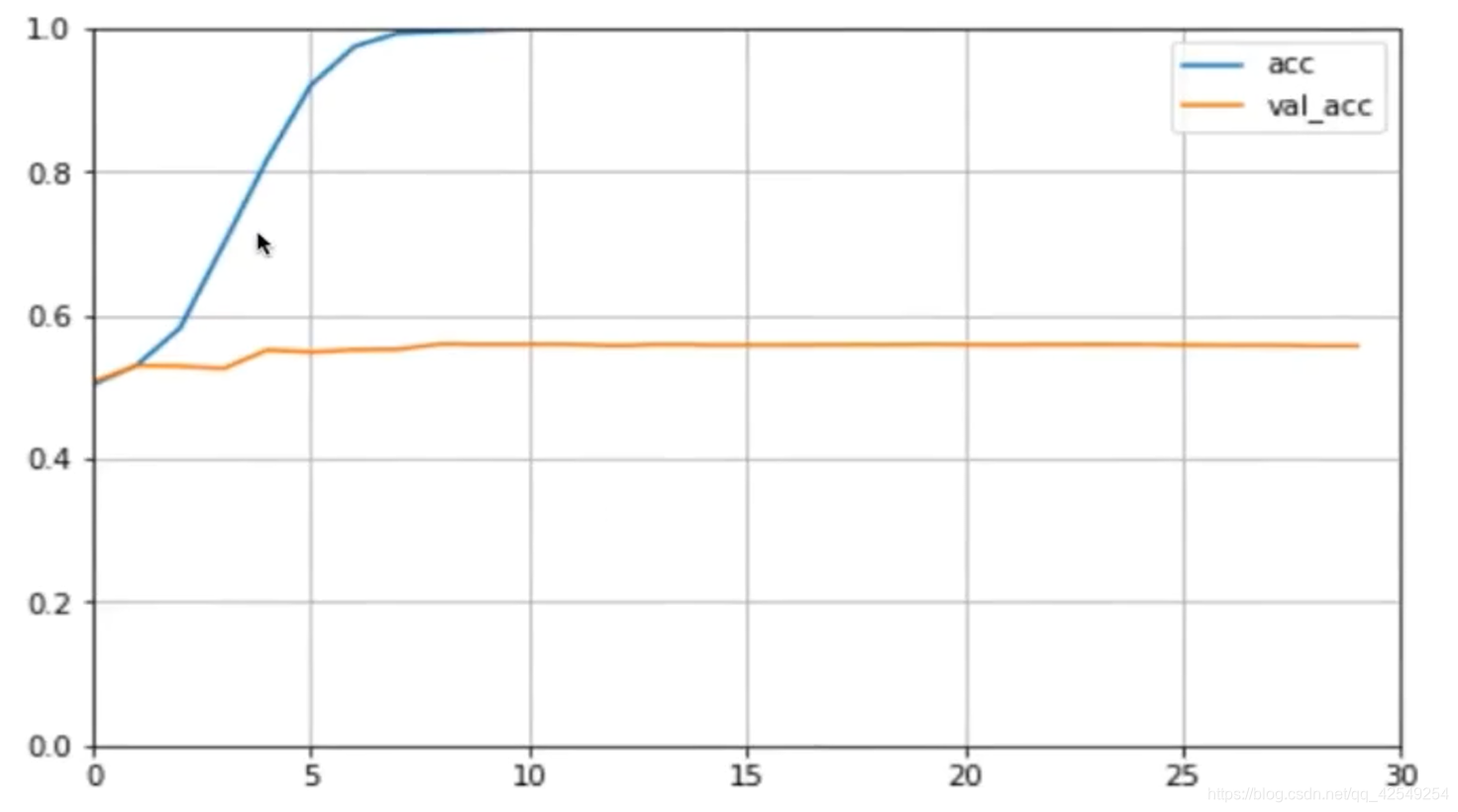
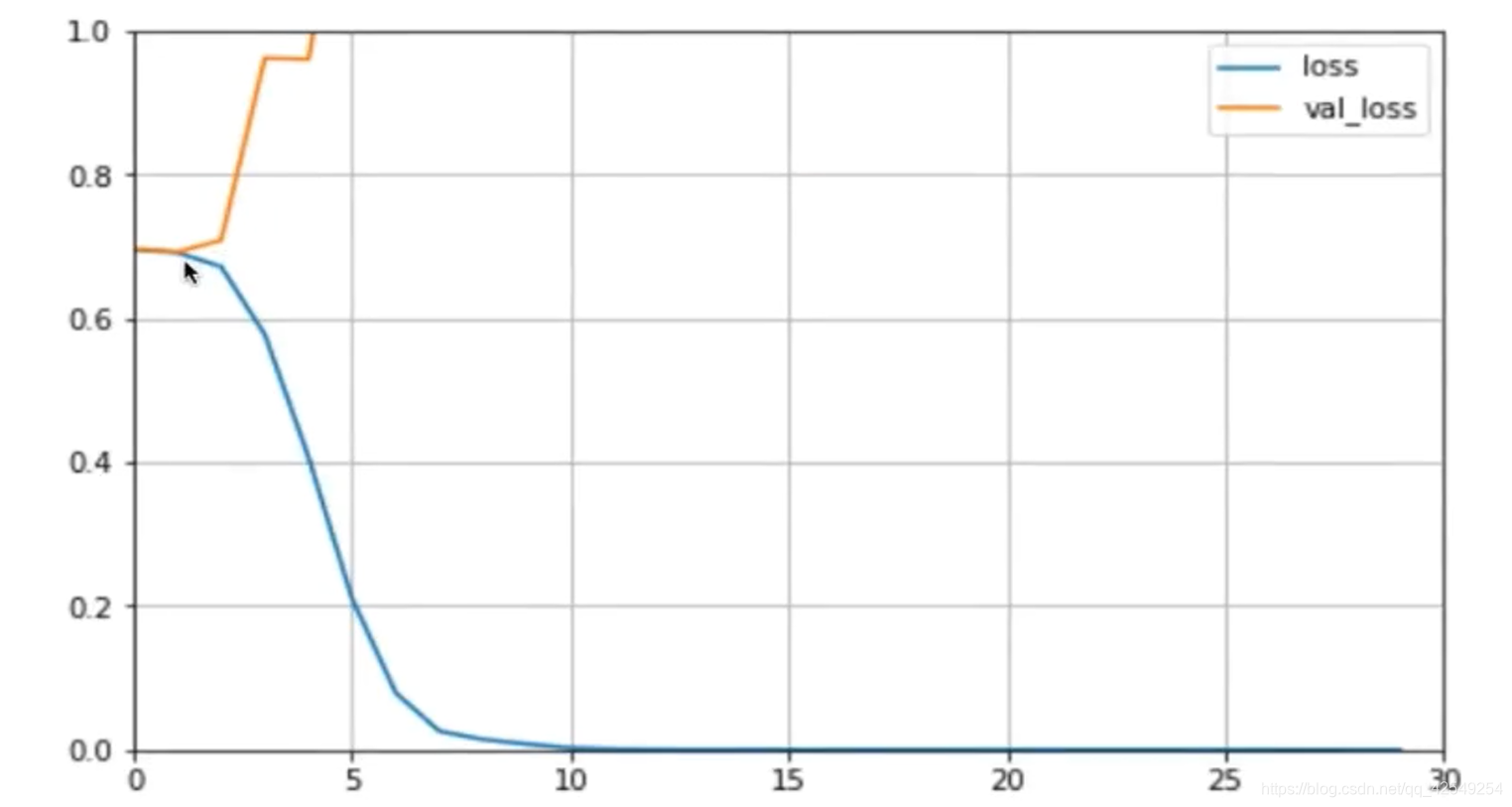
双层双向rnn太复杂,有过拟合的问题,所以可以改成单层试试。
单层双向rnn模型
embedding_dim = 16
batch_size = 512
bi_rnn_model = keras.models.Sequential([
# 1. define matrix: [vocab_size, embedding_dim]
# 2. [1,2,3,4..], max_length * embedding_dim
# 3. batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim,
input_length = max_length),
keras.layers.Bidirectional(
keras.layers.SimpleRNN(
# 改成32
units = 32, return_sequences = False)),
keras.layers.Dense(32, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
bi_rnn_model.summary()
bi_rnn_model.compile(optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy'])
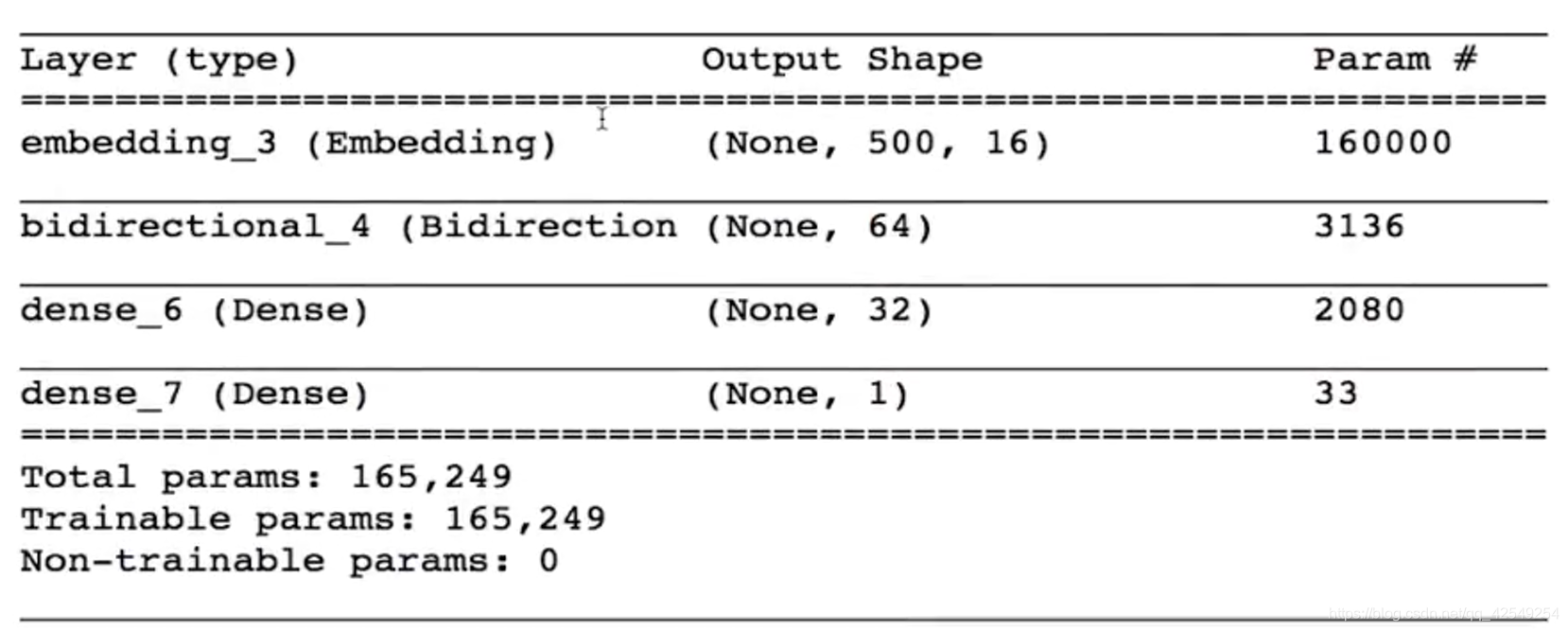
训练
history = bi_rnn_model.fit(
train_data, train_labels,
epochs = 30,
batch_size = batch_size,
validation_split = 0.2)

准确率好很多。
学习曲线
plot_learning_curves(history, 'acc', 30, 0, 1)
plot_learning_curves(history, 'loss', 30, 0, 1.5)
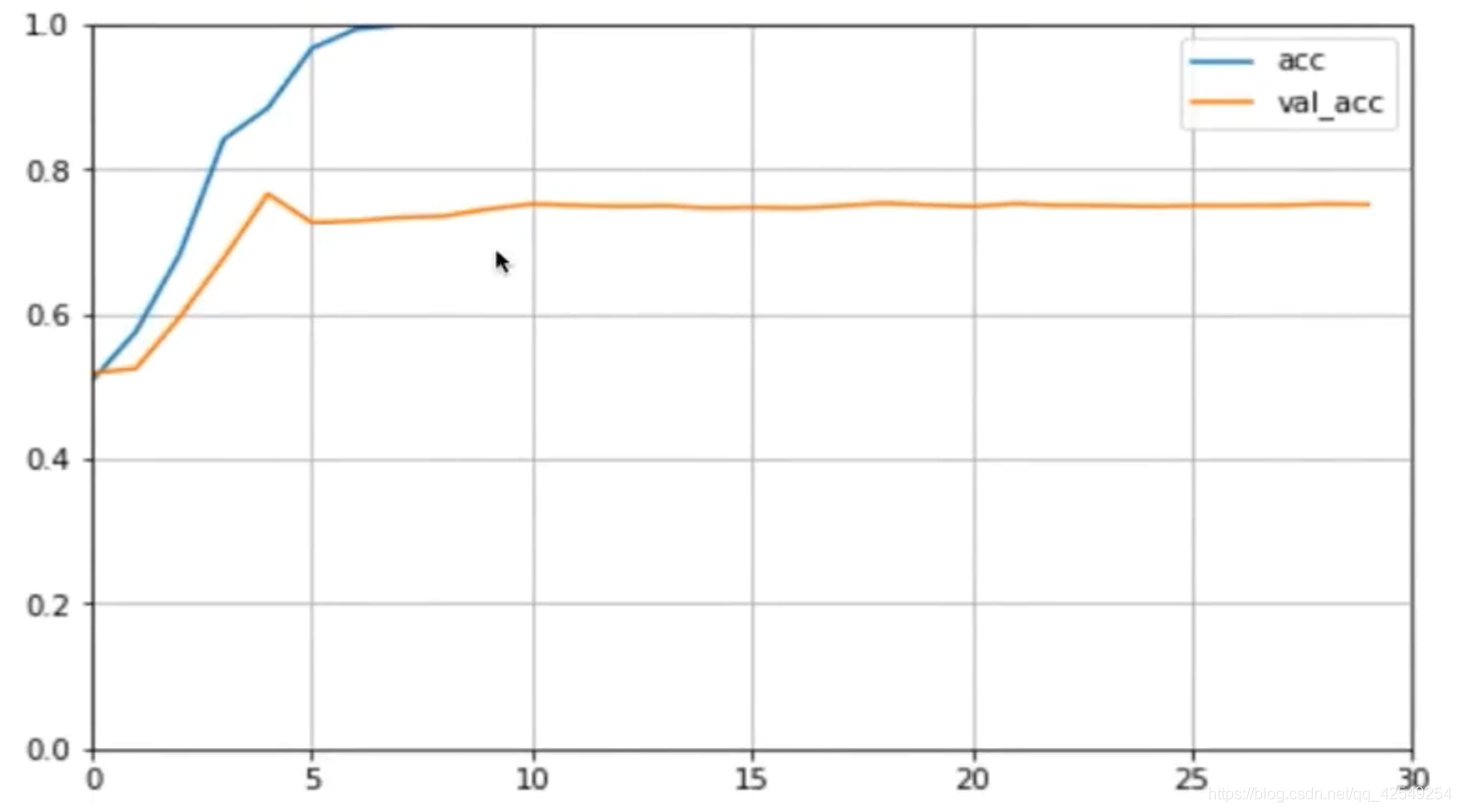
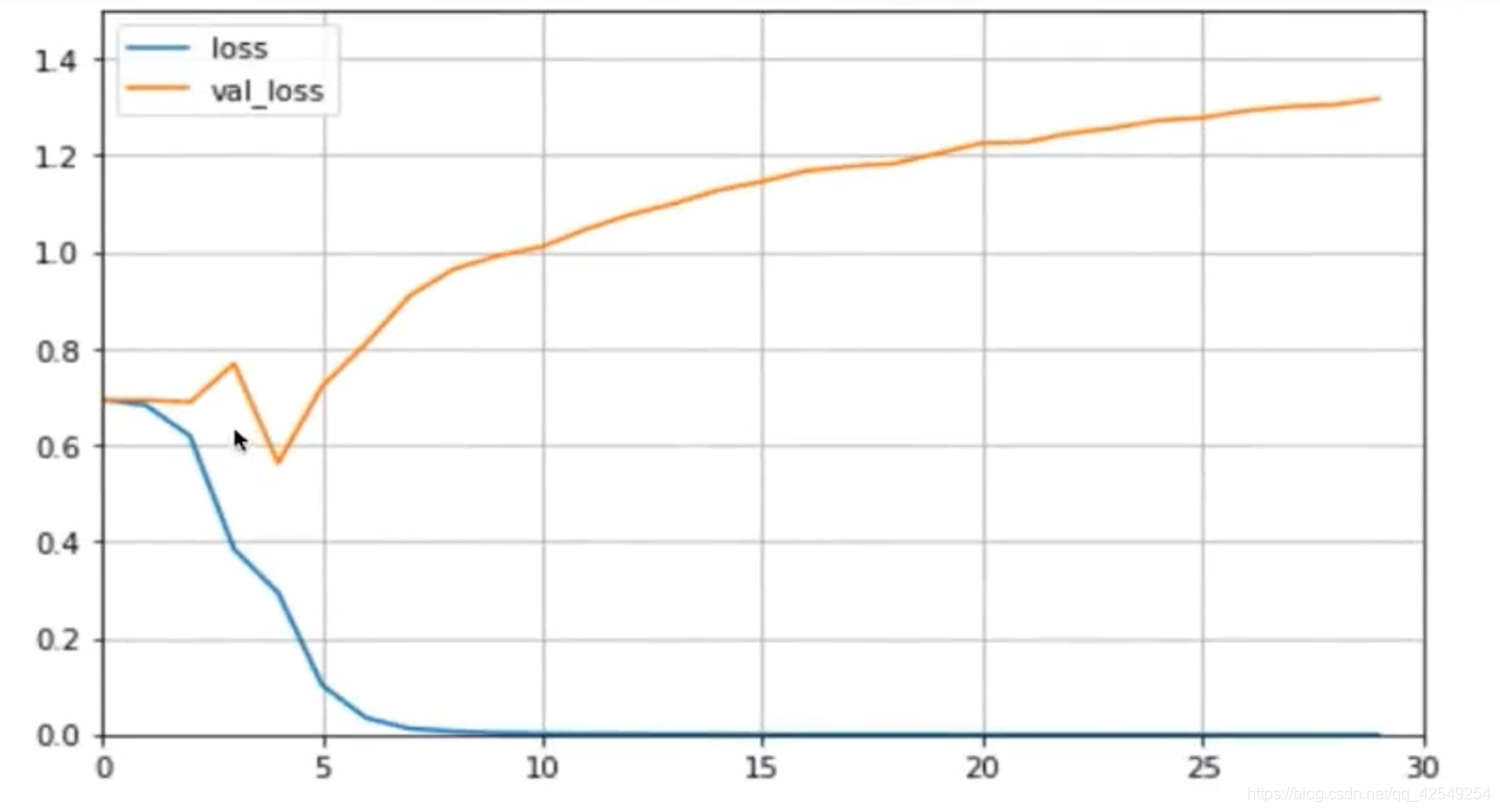
测试

准确率比普通神经网络要低,说明rnn比普通nn要弱吗?
从学习曲线图看出,在第五次迭代后,test loss开始上升,说明rnn过拟合非常明显,说明这个模型非常强大,太强大了所以过拟合,刚刚使用的减少过拟合方法是降低模型尺寸,还有一些正则化项,dropout,也可以防止过拟合。之后会介绍一种更强大的网络来防止过拟合——LSTM。
text generation
导入莎士比亚数据集

数据处理

词表65,一共有如上字符。

字符对应一个id,形成id到字符的一个映射。

把列表变成np.array

def split_input_target(id_text):
"""
每个输出都是输入的下一个字符
abcde -> abcd, bcde
"""
return id_text[0:-1], id_text[1:]
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
seq_length = 100
# 输入是5 输出是4 长度+1
seq_dataset = char_dataset.batch(seq_length + 1,
#最后一个batch不够,直接丢掉
drop_remainder = True)
for ch_id in char_dataset.take(2):
print(ch_id, idx2char[ch_id.numpy()])
for seq_id in seq_dataset.take(2):
print(seq_id)
print(repr(''.join(idx2char[seq_id.numpy()])))
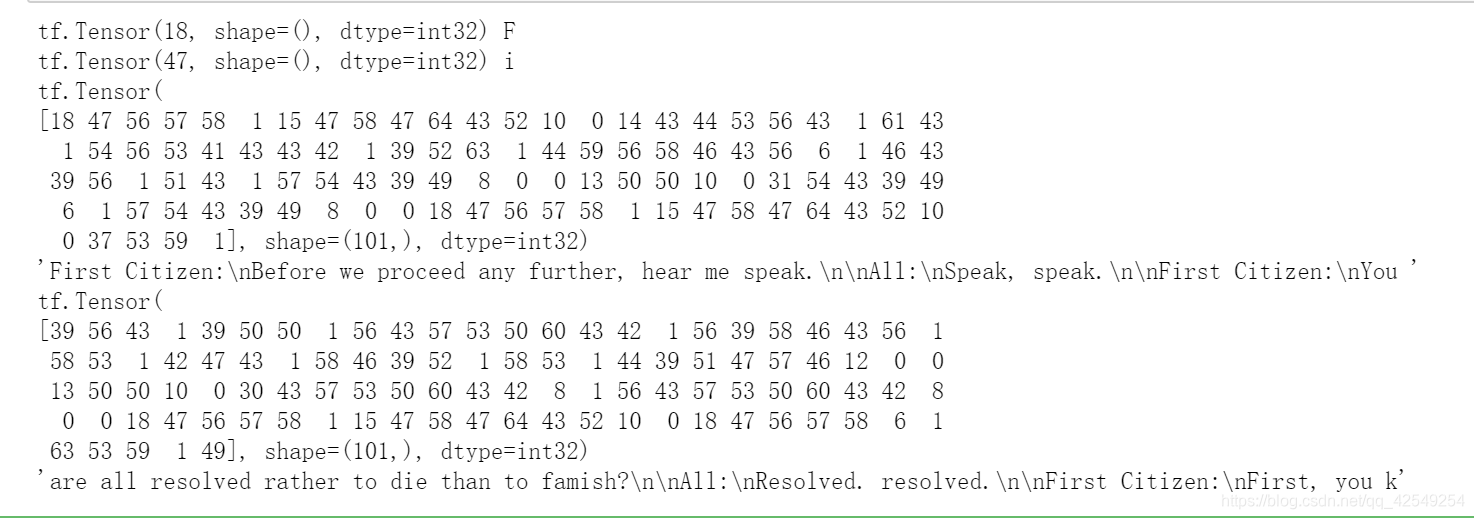
调用上面函数获得输入和输出。下面前两个是一组输入和输出,对于第二维来说,里面的第一个值等于第一维第一个的后面第二个值。

构建data set

定义模型
vocab_size = len(vocab)
embedding_dim = 256
rnn_units = 1024
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
model = keras.models.Sequential([
# embedding 层
keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape = [batch_size, None]),
keras.layers.SimpleRNN(units = rnn_units,
stateful = True,
recurrent_initializer = 'glorot_uniform',
return_sequences = True),
keras.layers.Dense(vocab_size),
])
return model
model = build_model(
vocab_size = vocab_size,
embedding_dim = embedding_dim,
rnn_units = rnn_units,
batch_size = batch_size)
model.summary()
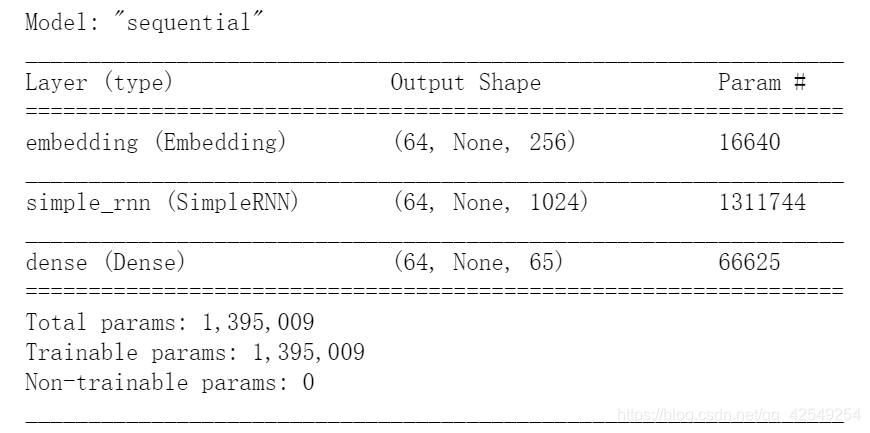

batch size * 长度 * 类别预测(预测一个概率分布)
随机采样
# random sampling.
# greedy, random.
sample_indices = tf.random.categorical(
logits = example_batch_predictions[0], num_samples = 1)
print(sample_indices)
# (100, 65) -> (100, 1)
sample_indices = tf.squeeze(sample_indices, axis = -1)
print(sample_indices)



output_dir = "./text_generation_checkpoints"
if not os.path.exists(output_dir):
os.mkdir(output_dir)
checkpoint_prefix = os.path.join(output_dir, 'ckpt_{epoch}')
checkpoint_callback = keras.callbacks.ModelCheckpoint(
filepath = checkpoint_prefix,
save_weights_only = True)
epochs = 100
history = model.fit(seq_dataset, epochs = epochs,
callbacks = [checkpoint_callback])

model2 = build_model(vocab_size,
embedding_dim,
rnn_units,
batch_size = 1)
model2.load_weights(tf.train.latest_checkpoint(output_dir))
model2.build(tf.TensorShape([1, None]))
# start ch sequence A,
# A -> model -> b
# A.append(b) -> B
# B(Ab) -> model -> c
# B.append(c) -> C
# C(Abc) -> model -> ...
model2.summary()
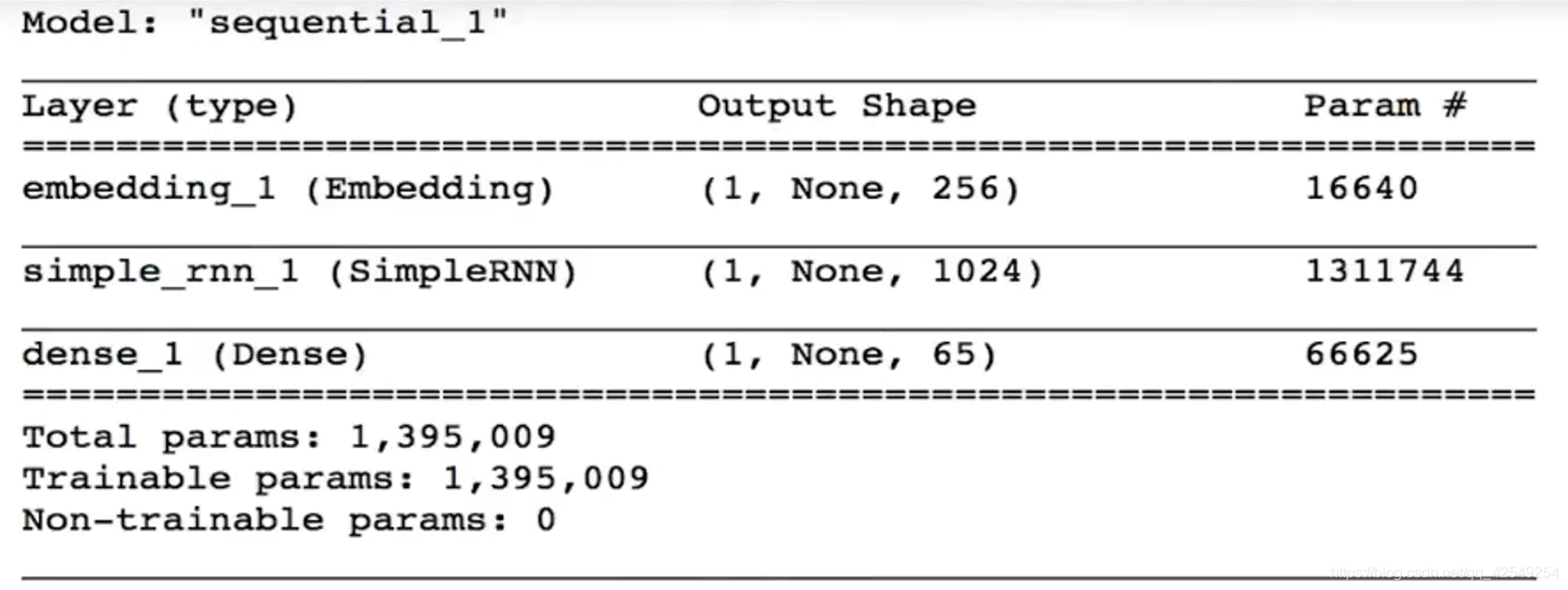
def generate_text(model, start_string, num_generate = 1000):
input_eval = [char2idx[ch] for ch in start_string]
input_eval = tf.expand_dims(input_eval, 0)
text_generated = []
model.reset_states()
for _ in range(num_generate):
# 1. model inference -> predictions
# 2. sample -> ch -> text_generated.
# 3. update input_eval
# predictions : [batch_size, input_eval_len, vocab_size]
predictions = model(input_eval)
# predictions : [input_eval_len, vocab_size]
predictions = tf.squeeze(predictions, 0)
# predicted_ids: [input_eval_len, 1]
# a b c -> b c d
predicted_id = tf.random.categorical(
predictions, num_samples = 1)[-1, 0].numpy()
text_generated.append(idx2char[predicted_id])
# s, x -> rnn -> s', y
input_eval = tf.expand_dims([predicted_id], 0)
return start_string + ''.join(text_generated)
new_text = generate_text(model2, "All: ")
print(new_text)
生成文本

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









