







Vector Set as Input
1、文字处理
在文字处理时,我们所输入的Input是一个长度不定的句子,我们将这个句子中的每一个出现的词汇描绘成一个vector,这样就将一个句子中出现的词汇转变为了一个vector set作为Input。
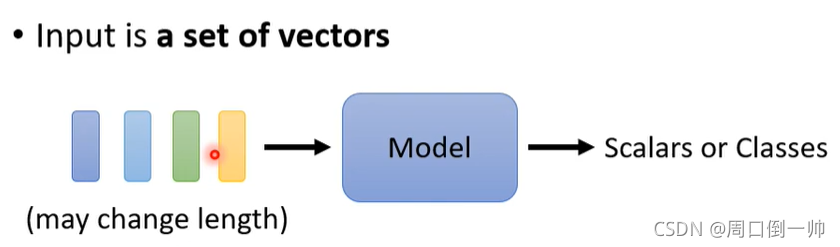
Self-Attention
Self-Attention的运作方式就是:
Self-Attention会利用一整个Sequence的资讯,然后你Input几个Vector,它就输出几个Vector,比如说你这边Input一个深蓝色的Vector,这边就给你一个另外一个Vector,这边给个浅蓝色,它就给你另外一个Vector,这边输入4个Vector,它就Output 4个Vector。
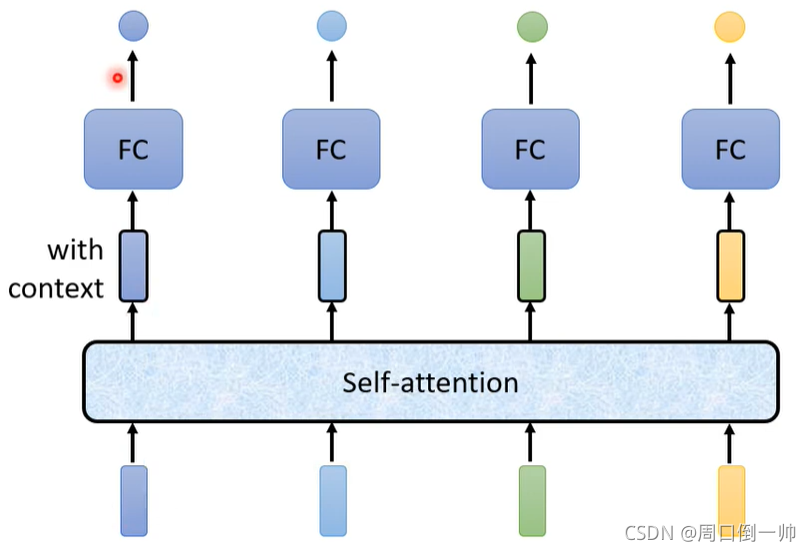
而这个过程,你可以持续很多次。
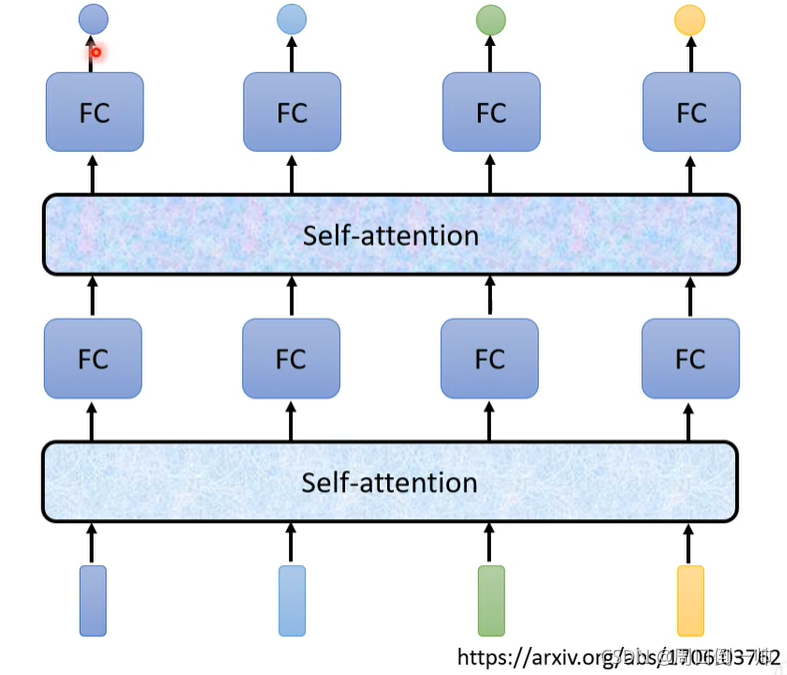
Self-Attention过程
详细过程请看这个视频。
https://www.bilibili.com/video/BV1Wv411h7kN?p=23&spm_id_from=pageDriver
Self-attention V.S. CNN
CNN 是一个简化版的 Self-attention,而 Self-attention 是复杂的 CNN 的版本。
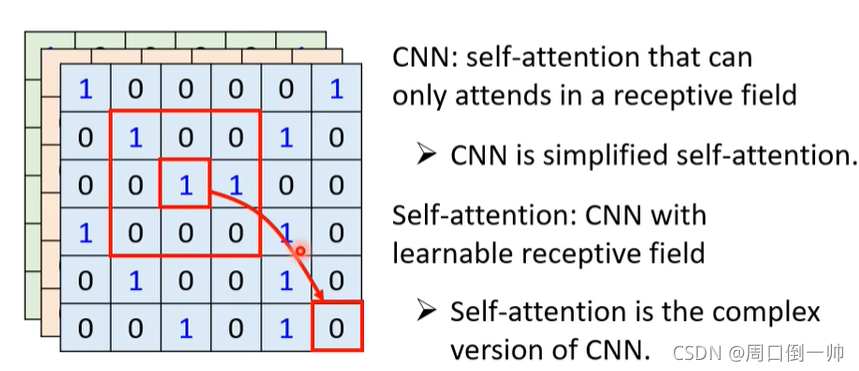
由上图可知,在处理一张图片时,当我们使用 CNN 进行处理时,我们首先画出一个receptive field,对画出的 receptive field 进行卷积, max pooling 等处理,换句话说,其在这一步当中考虑的是这一个画出区域里面所包含的资讯;而我们使用 Self-attention 进行处理时,我们所要考虑的就不是所画出的一个 receptive field 里面所包含的资讯,而是要考虑整张图像里面所包含的资讯。
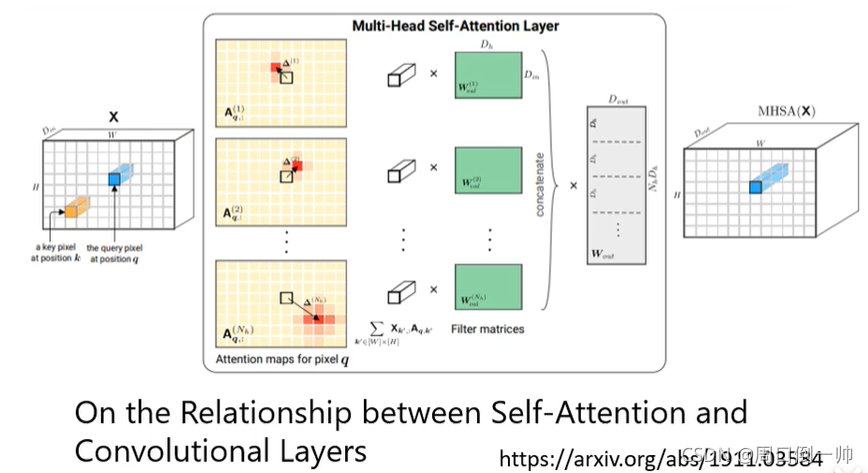
根据上图,由On the Relationship between Self-attention and Convolutional Layers这篇论文可知,Self-attention 只要设置合适的参数,就可以转化为 CNN。
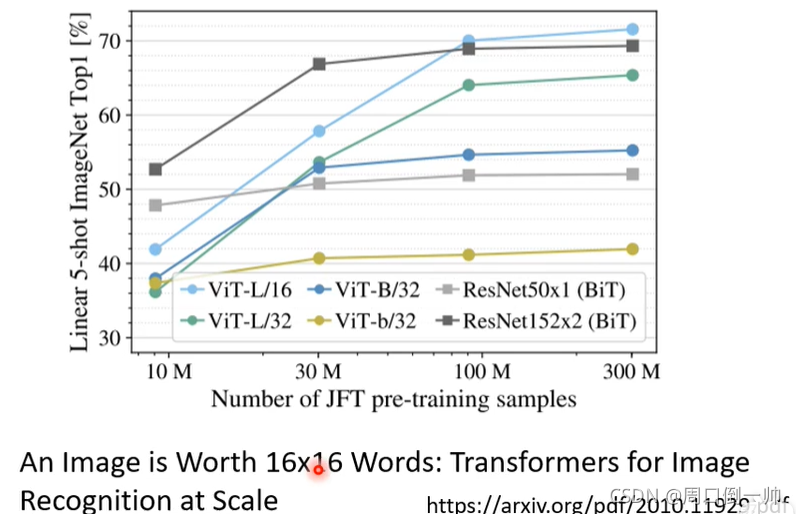
Self-attention 相较于 CNN 比较 flexible,对于 flexible 的模型来说,其需要更多的数据量,如果数据量不够,则得到的结果有可能overfitting。如下图所示,在这篇论文中,我们不难看出,当数据量足够大时,Self-attention模型 得到的结果优于 CNN模型 得到的结果。
Self-attention V.S. RNN
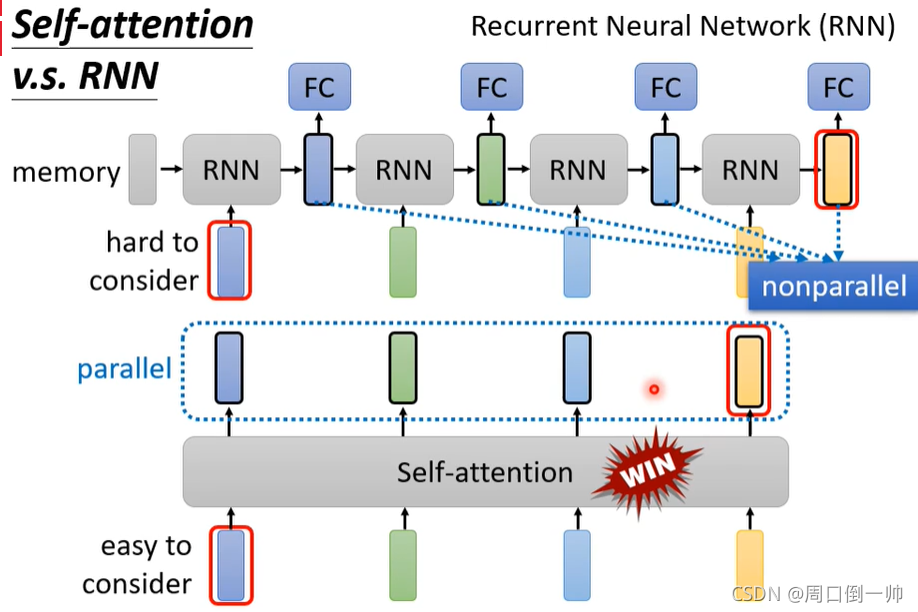
在 RNN 中,对于第一个 RNN 模块,输入 memory 的vector和 第一个input 的vector,得到的 output 是这个 hidden layer 的 output,也是下一个 hidden layer 的input。然后让这个 output 通过fully connectrd network。对于随后的 RNN 模块,重复上述步骤。
在 Self-attention 中,output 是另外一个 vector sequence,这里面的每一个 vector,都考虑了整个 input sequence 以后,再给 fully connected network 去做处理。
那 Self-attention 跟 RNN 有什么不同呢?
对于 Self-attention,它可以平行处理所有的输出,我们input 一排 vector,再 output 这四个 vector 的时候,这四个 vector 是平行产生的,并不需要等谁先运算完才把其他运算出来,output 的这个 vector,里面的 output 这个 vector sequence 里面,每一个 vector 都是同时产生出来的。
而对于 RNN 来说,它必须等前一个 RNN 模块处理完之后,得到的 output 与 本层的 input 进行输入,而后依次往下进行,这导致了 RNN 模型无法并行化处理。
因此,在相同数据量下,Self-attention 的运行效率优于 RNN 的运行效率。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









