







 超级会员免费看
超级会员免费看
一、基本知识
1、模型的输入:
如果把输入看成一个向量,输出是数值或者类别。但是若输入是一系列的向量(序列),同时长度会改变,例如输入是一句英文,每个单词的长短不一,每个词汇对应一个向量,所以模型的输入是多个长短不一的向量集合,并且每个向量的大小都不一样。
另外有语音信号(其中一段语音为一个向量)、图论(每个节点是一个向量)也能描述为一串向量。
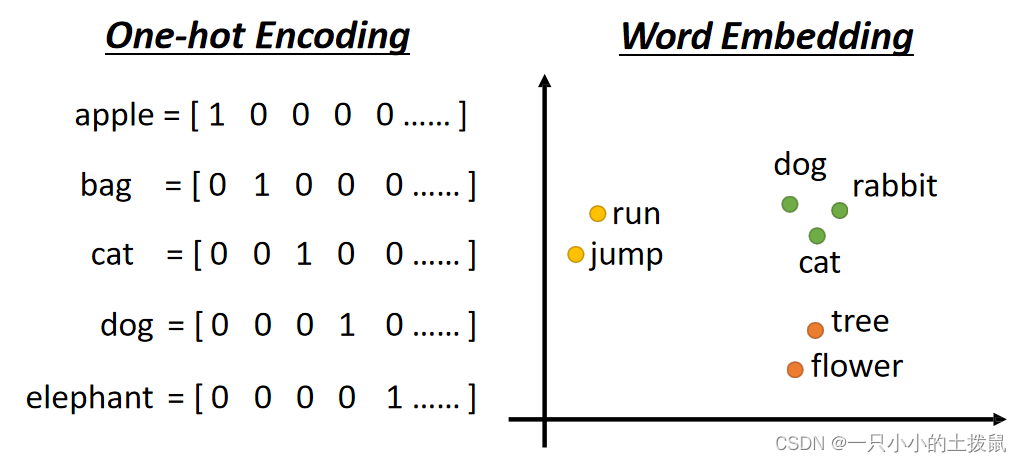
将单词表示为向量的方法,(1)可以利用one-hot encoding,向量的长度就是世界上所有词汇的数目,用不同位的1(其余位置为0)表示一个词汇,但是这种方式下每一个词之间没有关系,里面没有任何有意义的信息。(2)另一个方法是Word Embedding:给单词一个向量,这个向量有语义的信息,一个句子就是一排长度不一的向量。很显然这种方式下类别相同的词聚集在一起,因此它能区分出类别,将Word Embedding画出来:
自注意力机制要解决的问题是:当神经网络的输入是多个大小不一

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











