







Sequence to Sequence
输入是一个序列,输出是一个序列。输出序列的长度取决你的模型。
对应的,其可以应用在语音识别、机器翻译和语音翻译等场景。
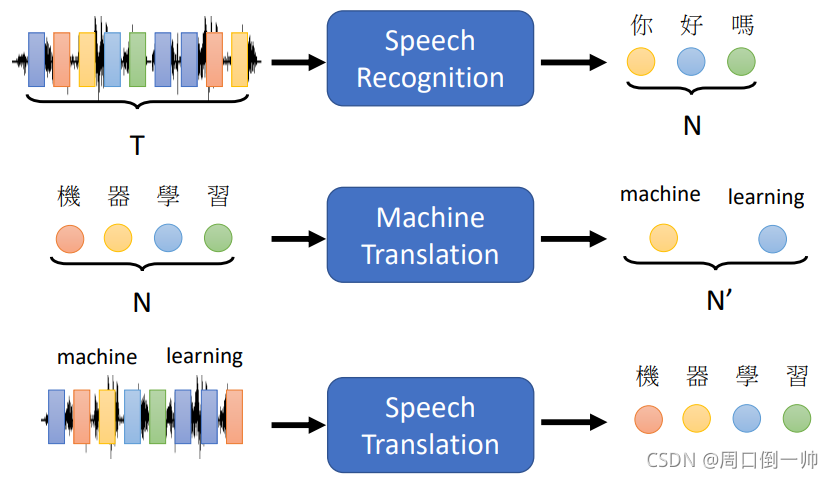
Is it a sequence?
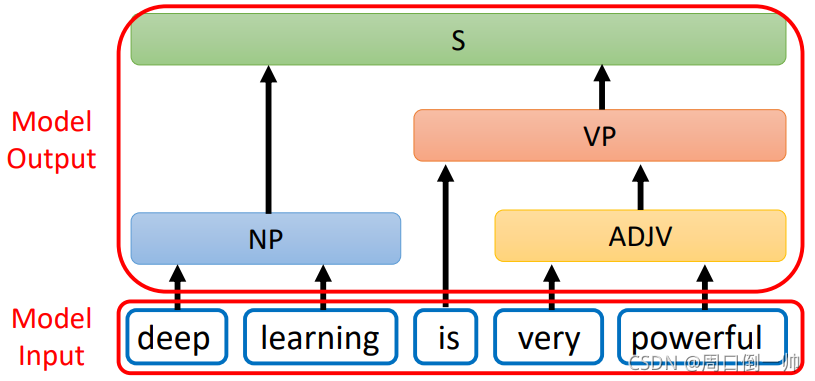
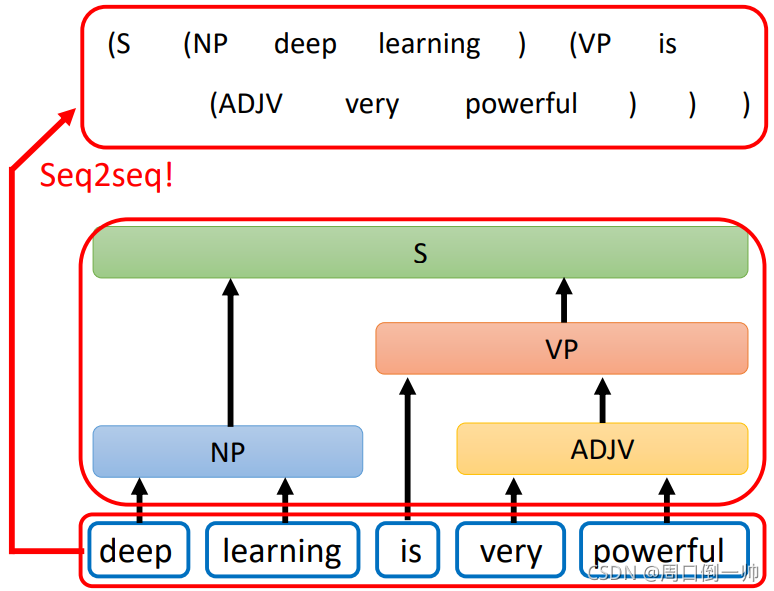
如上图可知,我们可以看到模型输入的是 deep learning is very powerful。
在处理时,deep 与 learning组合起来是一个名词,very 与 powerful组合起来是一个形容词,而 is 与 very powerful 组合起来是一个动词。最后将 deep learning is very powerful 进行组合,当作模型的输出。因此这就可以看作一个树的形状,根据得到单词间的关系,利用 Seq2Seq 模型对其进行输出。
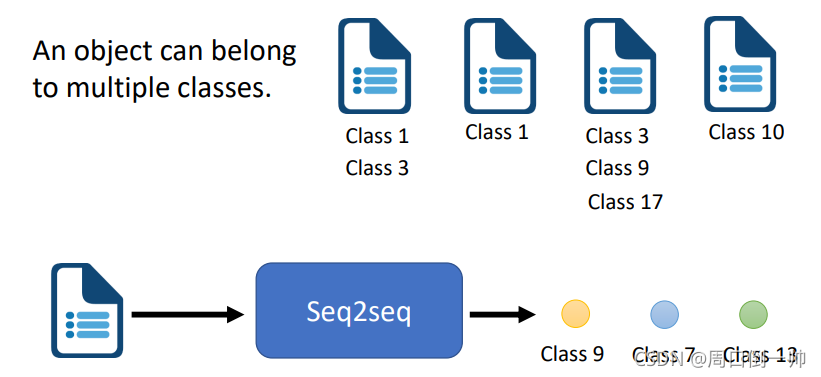
Multi-label Classification
对于一篇文章,他可能是属于多个类别的。这时我们利用 Seq2Seq 模型进行处理,输入为一篇文章,输出为所属种类。至于它是符合哪种类型的文章,这件事情让机器去做决定。
Transformer
流程图
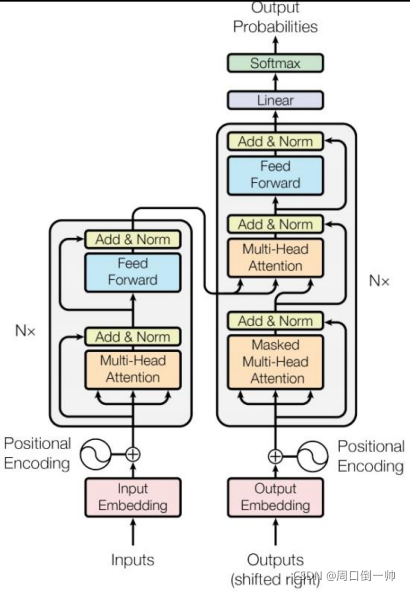
将上述流程图简化,我们会看到,输入一个sequence,经过 encoder 和 decoder,得到一个输出的 sequence。如下图所示。
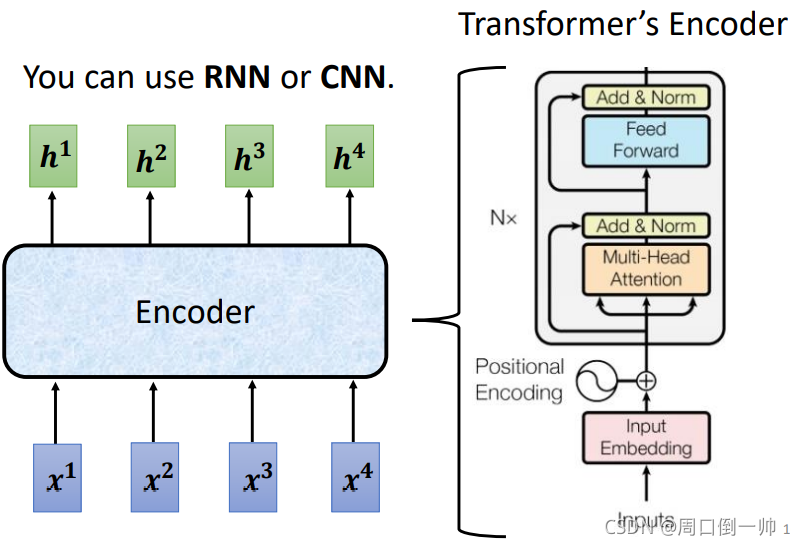
Encoder
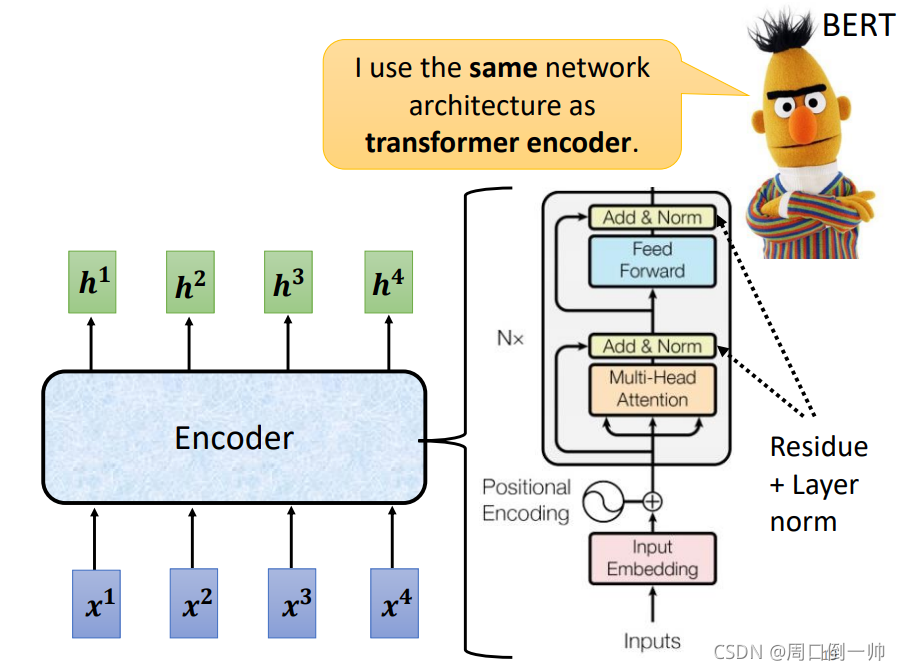
在 Encoder 阶段,你可以使用 RNN 或者CNN 对输入的序列进行处理,但更好的方式时使用 seq2seq 模型。
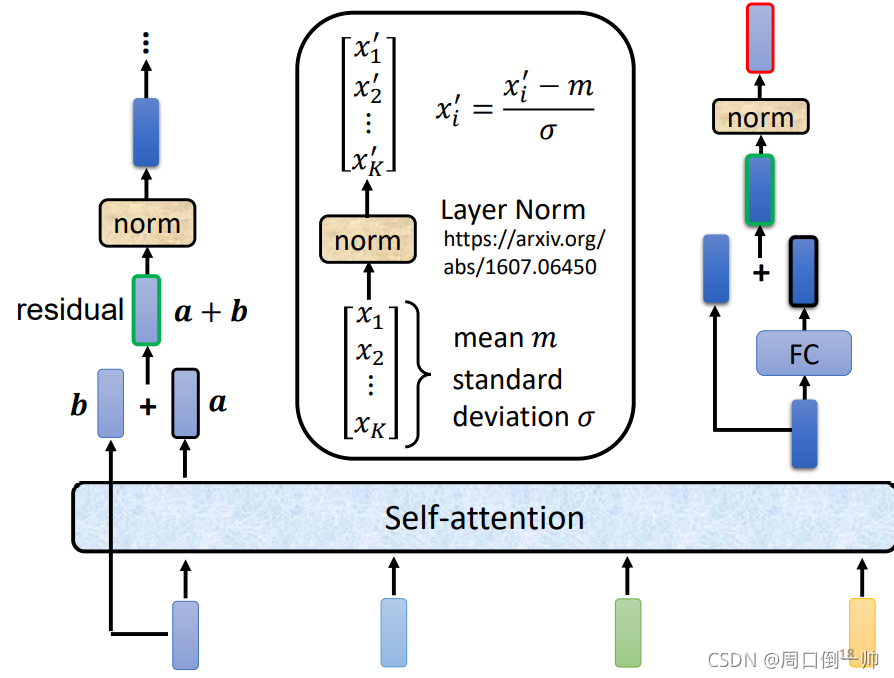
当使用 self-attention模型 进行处理时,在 Encoder 内,每一个block就相当于做了一次 self-attention 并将输出的结果通过全连接层进行输出。
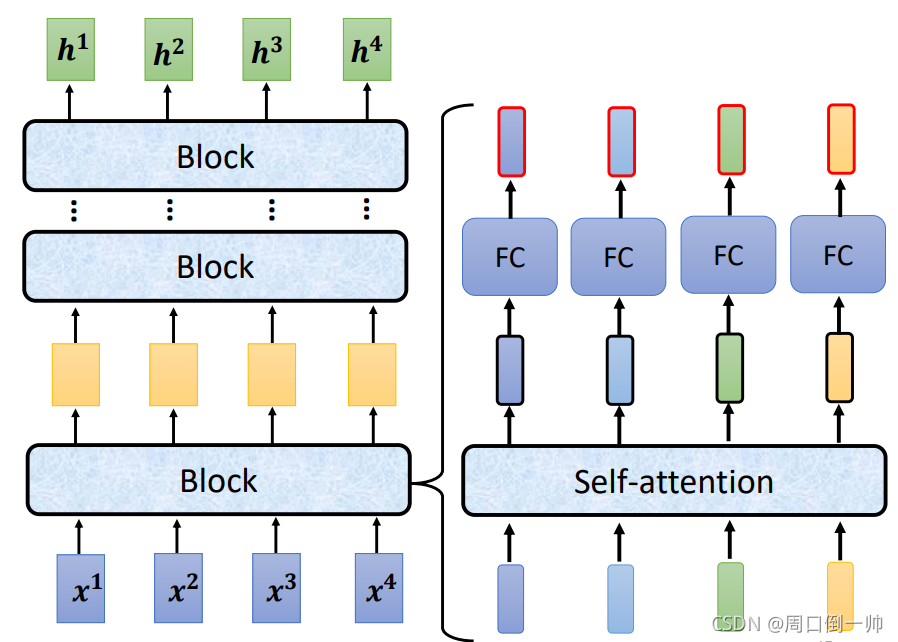
在 self-attention 之后,将原来输入对应的信息加到对应的输出上,这一步成为 residual,完成这一步之后,对输出进行layer norm处理,而不是bacth norm处理。将处理之后的输出通过Fully Connection层后,重复上述步骤再做一次。这一整个流程可以做N次。
Decoder
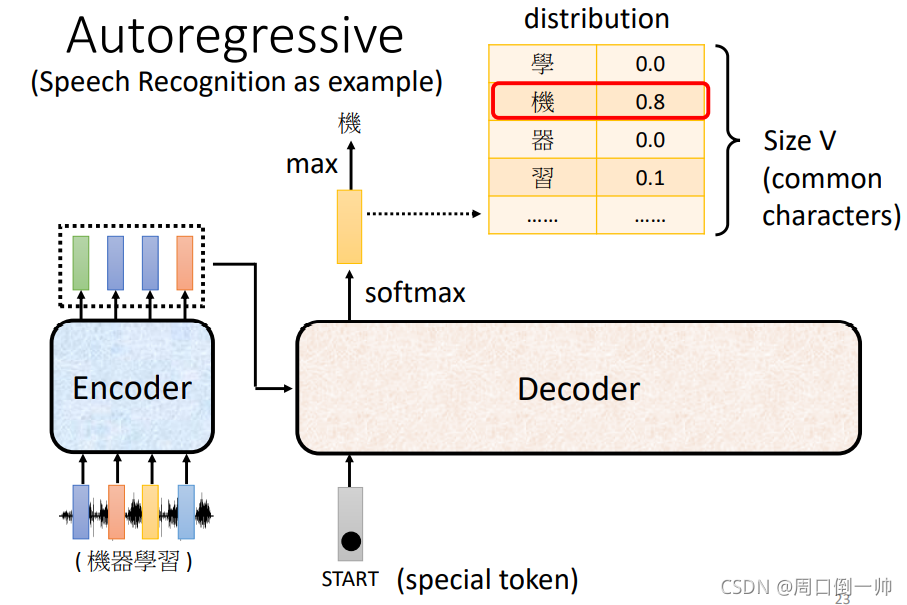
在 Encoder 完成之后,将得到的结果传输给 Decoder,传输过程后面在讨论。在 Decoder 之前,我们要先给其一个输入 start,表示从此刻开始将进行解码。将得到的 Encoder 的结果进行 Decoder 时,我们会得到第一个词的输出,如下图,此时对应的“机”字的概率最大,则首先将其输出。
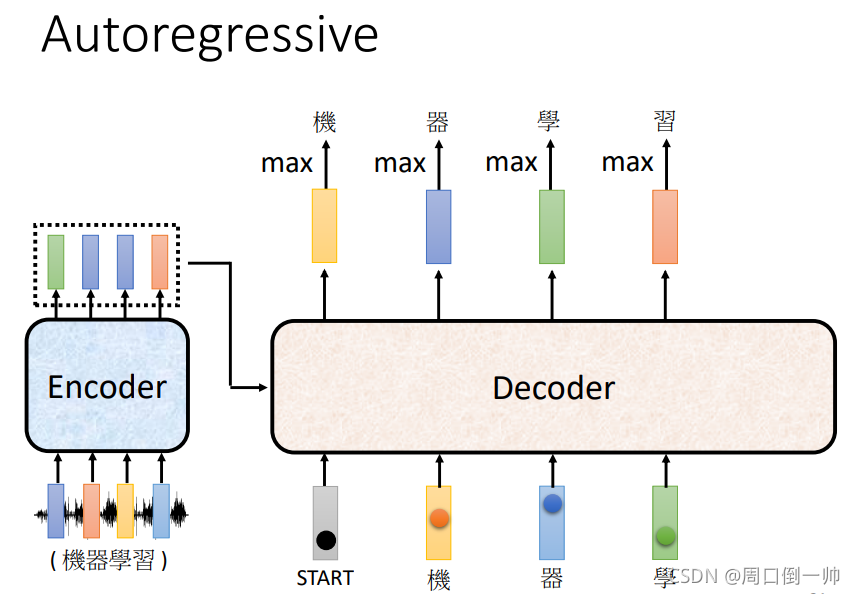
将得到“机”字作为 Decoder 的输入,得到后面字的输出。
Masked Self-attention
在 Decoder 中,Masked Self-attention 表示在 Decoder 时,你的每一字的输出只与你前面的那个字有关系,而与后面的字联系不大。举个例子,在得到开始解码的指令后,先输出“机”,在“机”没有输出出来时,不会输出“器”,依次往后类推。
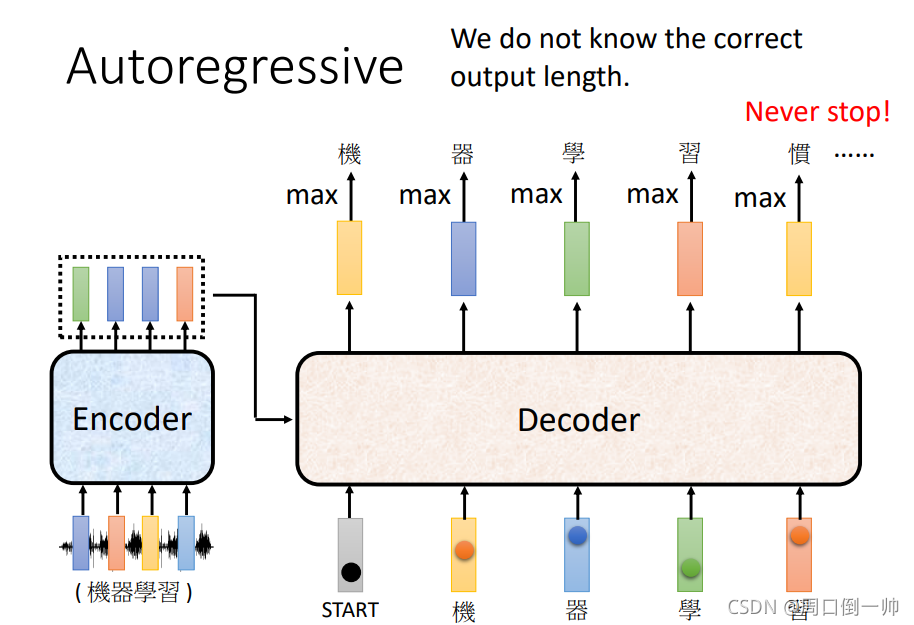
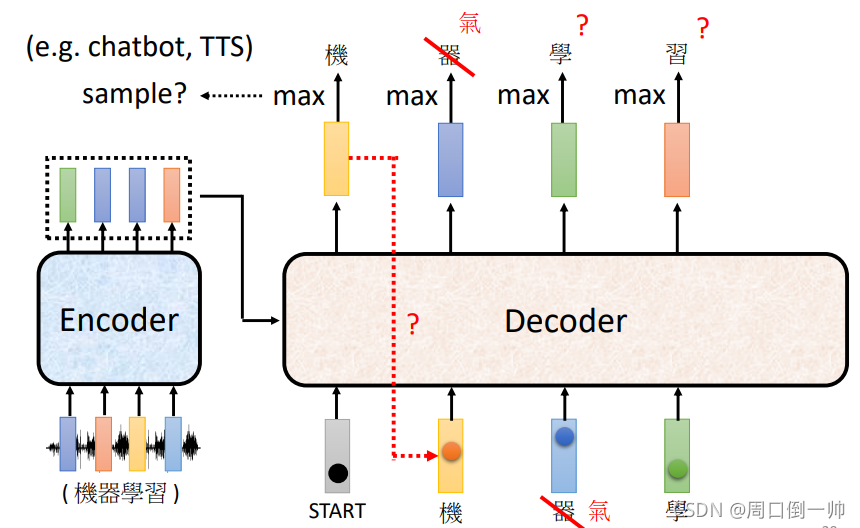
当然在输出时,我们有可能会看见其中的某个字可能会输出错误。这该怎么解决呢?
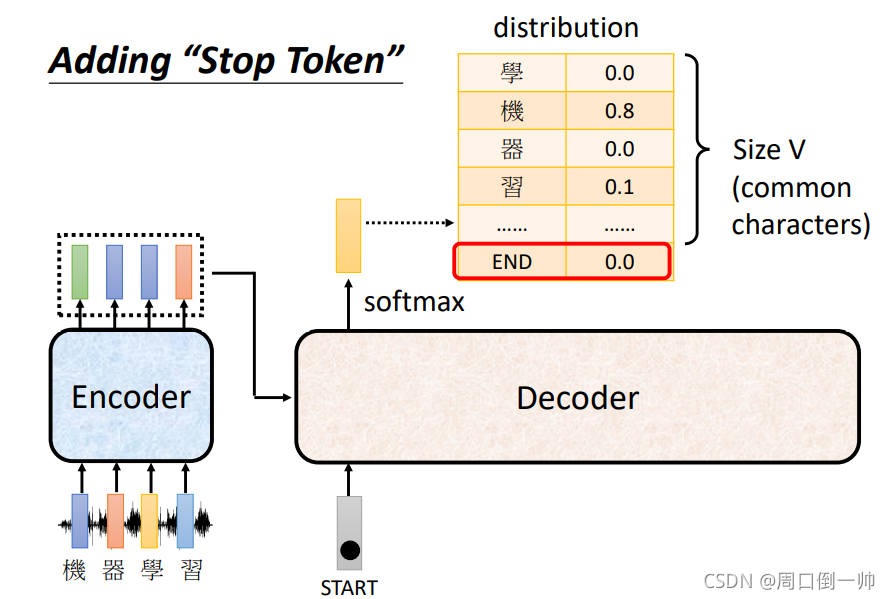
Adding “Stop Token”
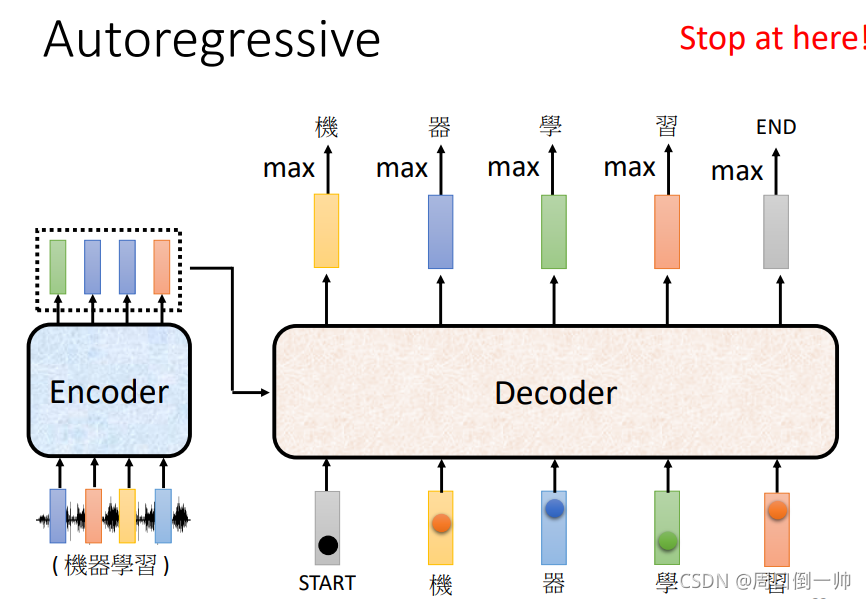
在解码完成后,我们希望有一个指令来让机器停止预测。此时就要在预测结束后输出一个 END 的输出,代表这一次的预测已经停止。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









