




 本文介绍了一种在分布式计算环境中优化数据关联的方法——Map-Side Join。通过在Map阶段而非Reduce阶段进行数据关联,可以显著减少网络IO和磁盘IO消耗,大幅提高处理速度。特别是当有一张小表和一张大表进行关联时,这种方法能实现几倍至数十倍的性能提升。文章详细解释了Map-Side Join的实现原理,并提供了具体的Spark代码示例。
本文介绍了一种在分布式计算环境中优化数据关联的方法——Map-Side Join。通过在Map阶段而非Reduce阶段进行数据关联,可以显著减少网络IO和磁盘IO消耗,大幅提高处理速度。特别是当有一张小表和一张大表进行关联时,这种方法能实现几倍至数十倍的性能提升。文章详细解释了Map-Side Join的实现原理,并提供了具体的Spark代码示例。
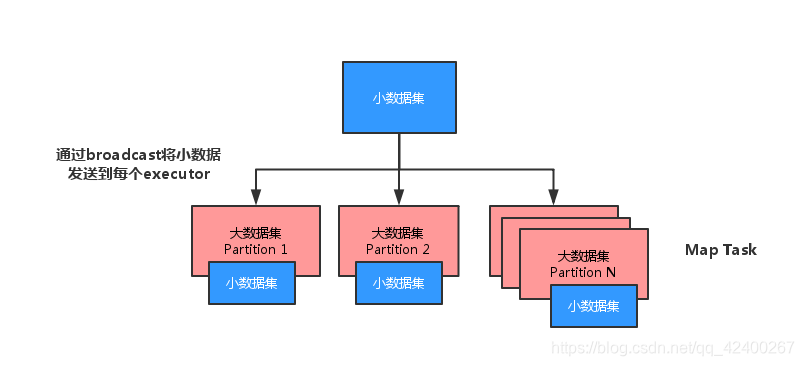
将多份数据进行关联是数据处理过程中非常普遍的用法,不过在分布式计算系统中,这个问题往往会变的非常麻烦,因为框架提供的 join 操作一般会将所有数据根据 key 发送到所有的 reduce 分区中去,也就是 shuffle 的过程。造成大量的网络以及磁盘IO消耗,运行效率极其低下,这个过程一般被称为 reduce-side-join。
如果其中有张表较小的话,我们则可以自己实现在 map 端实现数据关联,跳过大量数据进行 shuffle 的过程,运行时间得到大量缩短,根据不同数据可能会有几倍到数十倍的性能提升。
用于在海量数据中匹配少量特定数据
原理图
代码说明
将少量的数据转化为Map进行广播,广播会将此 Map 发送到每个节点中,如果不进行广播,每个task执行时都会去获取该Map数据,造成了性能浪费。
val people_info = sc.parallelize(Array(("110","lsw"),("222","yyy"))).collectAsMap()
val people_bc = sc.broadcast(people_info)
对大数据进行遍历,使用mapPartition而不是map,因为mapPartition是在每个partition中进行操作,因此可以减少遍历时新建broadCastMap.value对象的空间消耗,同时匹配不到的数据也不会返回()。
val res = student_all.mapPartitions(iter =>{
val stuMap = people_bc.value
val arrayBuffer = ArrayBuffer[(String,String,String)]()
iter.foreach{case (idCard,school,sno) =>{
if(stuMap.contains(idCard)){
arrayBuffer.+= ((idCard, stuMap.getOrElse(idCard,""),school))
}
}}
arrayBuffer.iterator
})
也可以使用 for 的守卫机制来实现上述代码
val res1 = student_all.mapPartitions(iter => {
val stuMap = people_bc.value
for{
(idCard, school, sno) <- iter
if(stuMap.contains(idCard))
} yield (idCard, stuMap.getOrElse(idCard,""),school)
})
完整代码
import org.apache.spark.{SparkContext, SparkConf}
import scala.collection.mutable.ArrayBuffer
object joinTest extends App{
val conf = new SparkConf().setMaster("local[2]").setAppName("test")
val sc = new SparkContext(conf)
/**
* map-side-join
* 取出小表中出现的用户与大表关联后取出所需要的信息
* */
//小表
val small = sc.parallelize(Array(("1","a"),("2","b"))).collectAsMap()
//大表
val big = sc.parallelize(Array(("1","s1","11"),("2","s2","22"), ("3","s3","33"),("4","s2","44")))
//将需要关联的小表进行关联
val smallbc = sc.broadcast(small)
/**
* 使用mapPartition而不是用map,减少创建broadCastMap.value的空间消耗
* 同时匹配不到的数据也不需要返回()
* */
val res = big.mapPartitions(iter =>{
val smallMap = smallbc.value
val arrayBuffer = ArrayBuffer[(String,String,String)]()
iter.foreach{case (id,belong,no) =>{
if(smallMap.contains(id)){
arrayBuffer.+= ((id, smallMap.getOrElse(id,""),belong))
}
}}
arrayBuffer.iterator
})
/**
* 使用另一种方式实现
* 使用for的守卫
* */
val res1 = big.mapPartitions(iter => {
val smallMap = smallbc.value
for{
(idCard, school, sno) <- iter
if(smallMap.contains(id))
} yield (id, smallMap.getOrElse(id,""),belong)
})
res.foreach(println)
结果:
1,a,s1

















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









