




 本文介绍pandas中层次化索引的功能及其在数据重塑中的应用,包括stack与unstack操作,展示如何通过这些功能处理高维度数据,并实现数据列与行之间的转换。
本文介绍pandas中层次化索引的功能及其在数据重塑中的应用,包括stack与unstack操作,展示如何通过这些功能处理高维度数据,并实现数据列与行之间的转换。
层次化索引与数据重塑
层次化索引是 pandas的一 项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。
层次化索引为Dataframe数据的重排任务提供了一种具有良好一致性的方式。主要功能有二
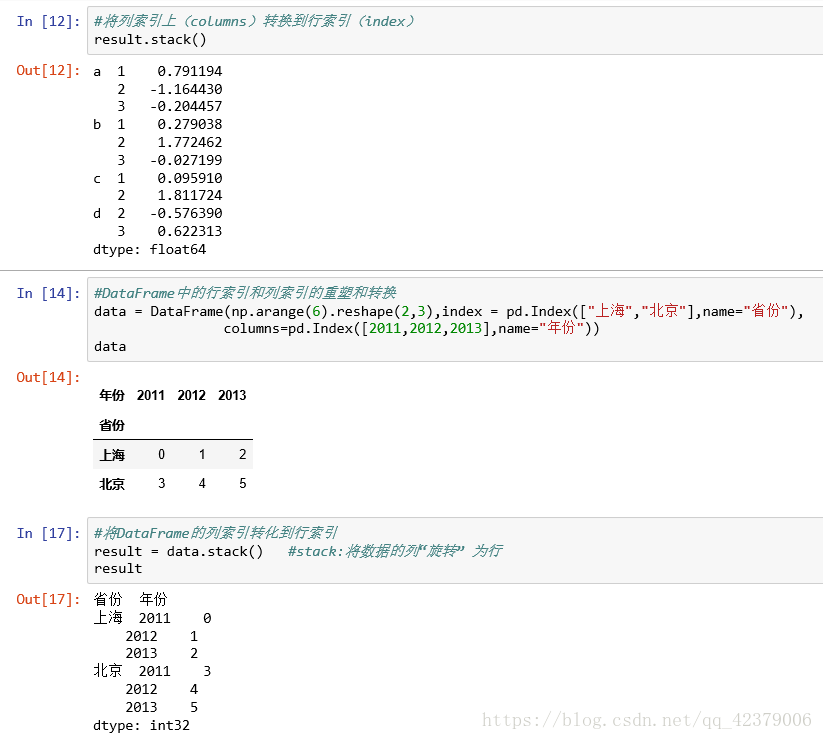
• stack:将数据的列“旋转”为行
• unstack:将数据的行“旋 转”为列
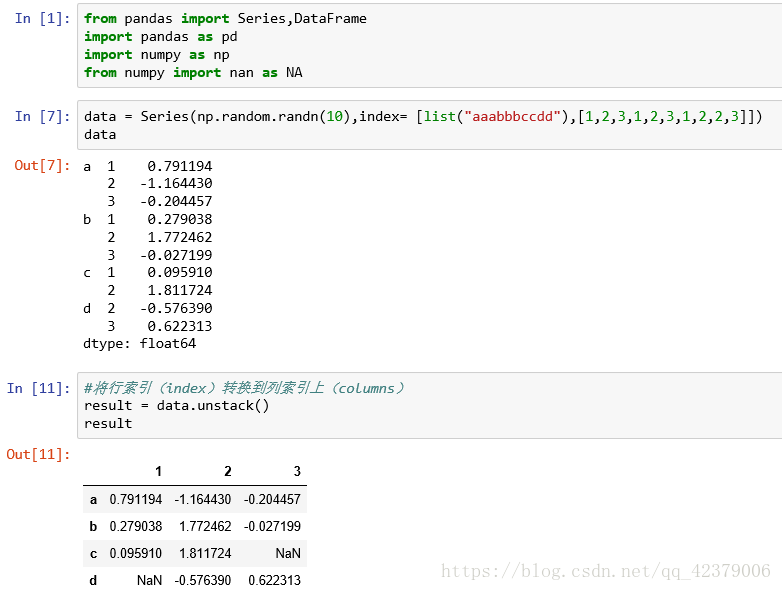
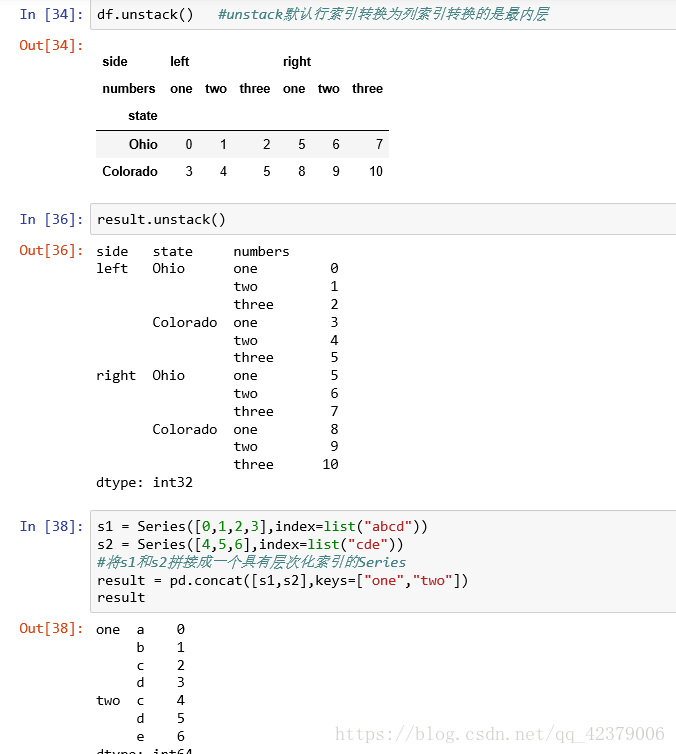
对于一个层次化索引的 Series. 你可以用unstack 将其重排一个DataFrame :
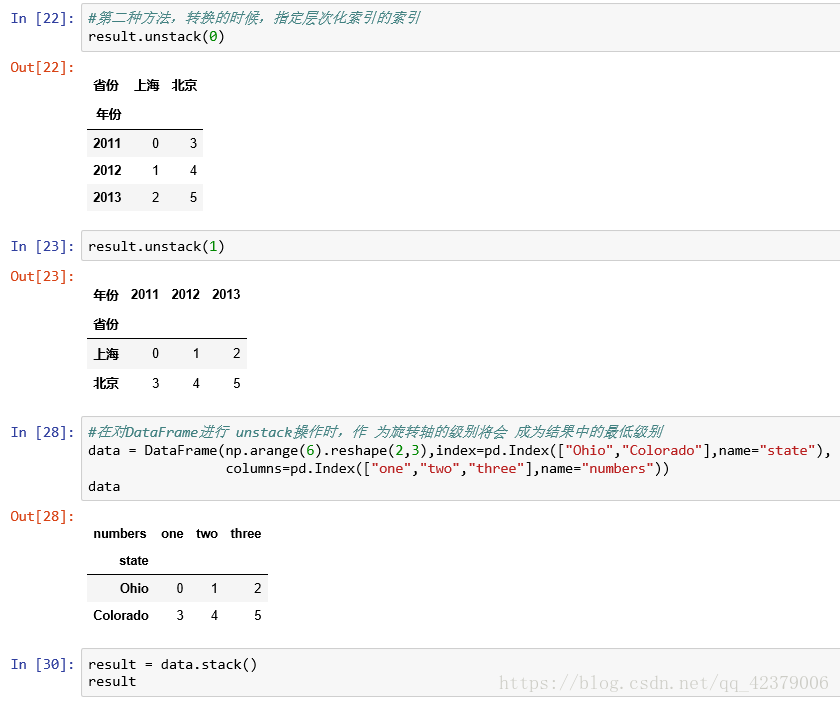
默认情况下, unstack操 作的是最内层( stack也是如此)。传入分层级别的编号或名称即可对其他级别进行unstack操作 :
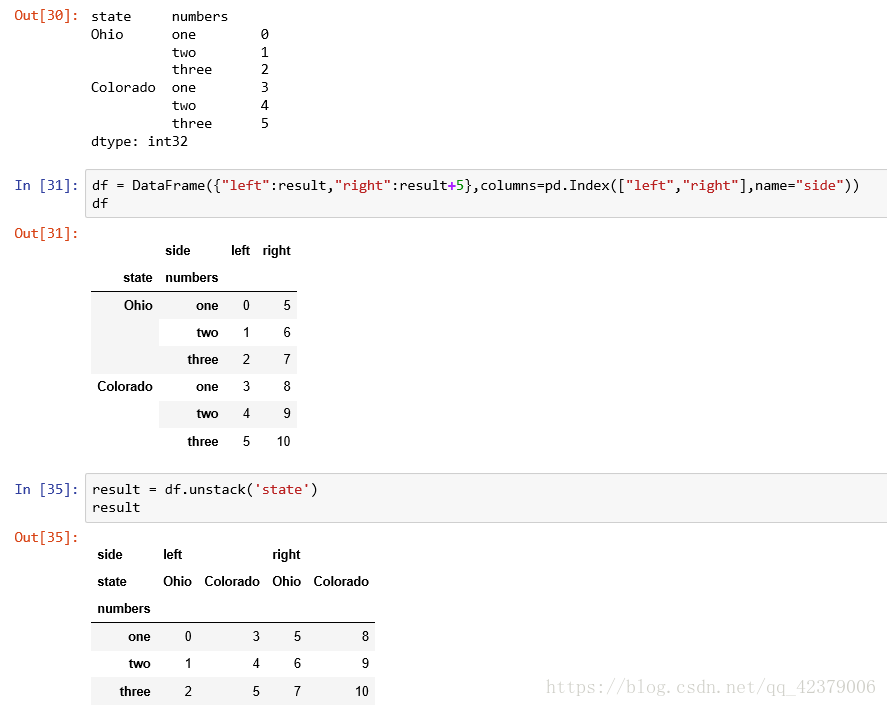
如果不是所有级别的数据都能在分组中找到的话,则unstack操作可能会引入缺失数据
• stack默认为滤除缺失 数据,因此该运算是可逆的
代码演示如下:



















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









