PAT A1083 List Grades
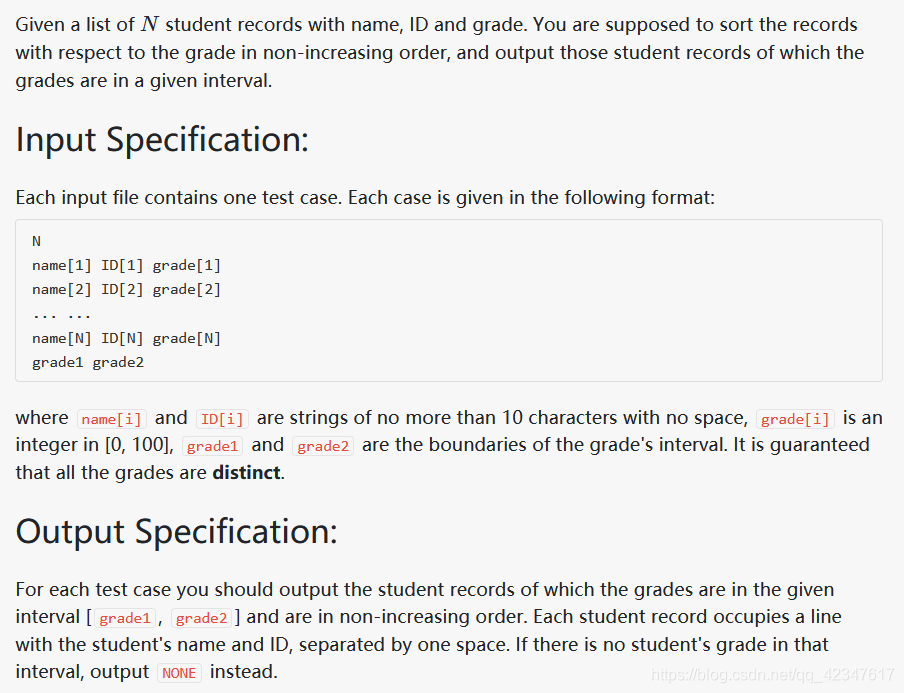
Sample Input 1:
4
Tom CS000001 59
Joe Math990112 89
Mike CS991301 100
Mary EE990830 95
60 100
Sample Output 1:
Mike CS991301
Mary EE990830
Joe Math990112
Sample Input 2:
2
Jean AA980920 60
Ann CS01 80
90 95
Sample Output 2:
NONE
| word | meaning |
|---|
| in a given interval | 在给定的区间内 |
| distinct | adj. 截然不同的 |
- 思路 1:
直接排序,遍历,输出区间内元素(A1055简化版) - code 1:
#include <string>
#include <iostream>
#include <algorithm>
#include <stdio.h>
using namespace std;
int n;
struct Stu{
string name, id;
int grade;
}stu[100010];
bool cmp(Stu a, Stu b){
return a.grade > b.grade;
}
int main(){
scanf("%d", &n);
for(int i = 0; i < n; ++i){
cin >> stu[i].name >> stu[i].id >> stu[i].grade;
}
sort(stu, stu+n, cmp);
int lower, upper;
scanf("%d %d", &lower, &upper);
bool flag = false;
for(int i = 0; i < n; ++i){
if(stu[i].grade < lower) break;
else if(stu[i].grade <= upper){
cout << stu[i].name << " " << stu[i].id<<endl;
flag = true;
}
}
if(flag == false) printf("NONE");
return 0;
}
- T4 code: 分数全是不同的直接has表就行了
#include <bits/stdc++.h>
using namespace std;
string name[110], id[110];
bool has[110];
int main()
{
int n;
scanf("%d", &n);
for(int i = 0; i < n; ++i)
{
string tname, tid;
int tscore;
cin >> tname >> tid >> tscore;
name[tscore] = tname;
id[tscore] = tid;
has[tscore] = true;
}
int lower, upper;
scanf("%d %d", &lower, &upper);
for(int i = upper; i >= lower; --i)
{
if(has[i] == true)
{
cout << name[i] << " " << id[i] << endl;
has[101] = true;
}
}
if(has[101] == false) printf("NONE");
return 0;
}








 本文介绍了一种基于排序和哈希表的数据结构算法,用于在给定的分数区间内快速筛选和输出学生名单。通过直接排序和遍历或使用哈希表的方式,实现了高效的数据检索,适用于处理大量学生数据的场景。
本文介绍了一种基于排序和哈希表的数据结构算法,用于在给定的分数区间内快速筛选和输出学生名单。通过直接排序和遍历或使用哈希表的方式,实现了高效的数据检索,适用于处理大量学生数据的场景。

















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









