






目录
一、简介
1、数据简介
本文数据来自kaggle网站时间序列分析数据集 (kaggle.com),该数据集并无太多说明,时间是从1991年7月到2008年6月,共204条数据。
2、相关理论
AR(p):自回归模型。
MA(q):移动平均。
ARMA(p,q):自回归移动平均模型。
ARIMA(p,d,q):在ARMA基础上进行差分后建立的ARMA模型。比如进行一阶差分:
𝑌𝑡再进行ARMA(p,q)模型构建:
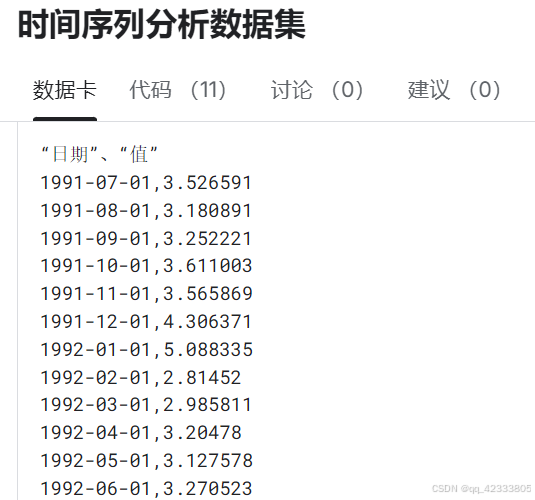
𝑆𝐴𝑅𝐼𝑀𝐴(𝑝, 𝑑, 𝑞) × (𝑃, 𝐷, 𝑄)𝑚:季节项的 ARIMA 模型。对于周期为 m 的时间序列𝑋𝑡,其时间间隔为 m 的观测值有相似之处,利用季节差分
![]()
消除周期性变化,其中 D 表示季节差分的次数, ℬ表示滞后算子。若𝑋𝑡是非平稳的时间序列,对其进行 D 次季节差分,可将其转化为平稳序列𝑌𝑡。此时可对𝑌𝑡构造𝐴𝑅𝑀𝐴(𝑃, 𝑄)模型,即满足
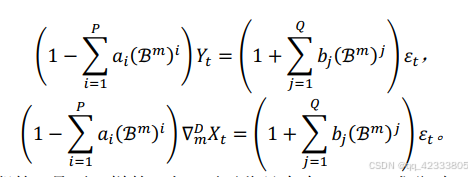
不同周期的𝜀𝑡是不一样的,当𝜀𝑡不平稳且存在 ARMA 成分时,可对𝜀𝑡进行差分后构建 ARMA 模型,即对∇𝑑𝜀𝑡构造𝐴𝑅𝑀𝐴(𝑝, 𝑞)模型
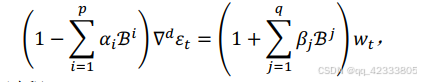
其中𝑤𝑡为白噪声过程。将上面式子进行整合,得到𝑆𝐴𝑅𝐼𝑀𝐴(𝑝, 𝑑, 𝑞) × (𝑃, 𝐷, 𝑄)𝑚模型的一般表达式
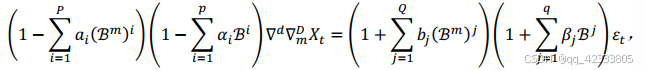
其中𝑝, 𝑞分别表示非季节性的自回归和移动平均算子最大阶数, 𝑃, 𝑄分别表示季节性的自回归和移动平均算子最大阶数, 𝑑, 𝐷分别表示非季节项和季节性差分次数, 𝑚为周期值。注意到𝑆𝐴𝑅𝐼𝑀𝐴(𝑝, 𝑑, 𝑞) × (𝑃, 𝐷, 𝑄)𝑚中(𝑝, 𝑑, 𝑞)部分表示非季节项, (𝑃, 𝐷, 𝑄)部分表示季节项, 季节项与非季节项的模型非常相近, 但是季节项中包含了季节周期性。
举一些例子:
AR(1):
𝑆𝐴𝑅𝐼𝑀𝐴(0, 0, 0) × (0, 0, 1)12(或写成MA(1)12):
𝑆𝐴𝑅𝐼𝑀𝐴(0, 0, 0) × (1, 0, 0)12(或写成AR(1)12):
𝑆𝐴𝑅𝐼𝑀𝐴(0, 0, 1) × (0, 0, 1)12:
𝑆𝐴𝑅𝐼𝑀𝐴(0, 0, 1) × (1, 0, 0)12:
本文对于该时间序列数据进行分析与预测,主要从数据探索、差分、定阶、模型构建、预测进行实战分析。其中涉及到SARIMA一些理论知识需要查漏补缺看b站的这个视频【时间序列】SARIMA模型理论_哔哩哔哩_bilibili
对于时间序列处理流程如下图所示,本文也是按照如下流程进行时间序列分析。如有不足欢迎指正,谢谢!
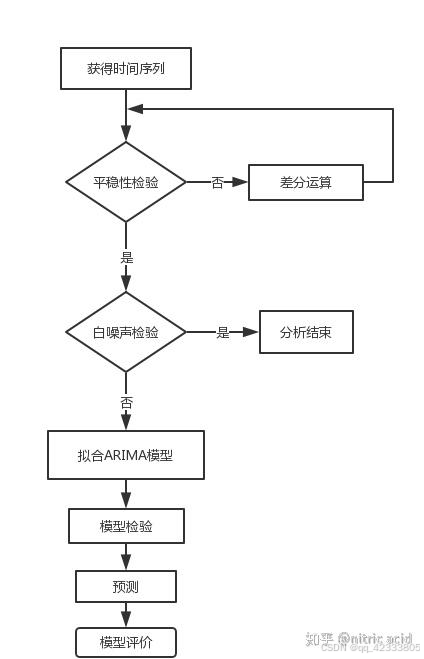
二、数据探索
1、数据导入
首先引入会用到的一些库:
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller
from numpy import log
from statsmodels.stats.diagnostic import acorr_ljungbox
import statsmodels.api as sm
import pmdarima as pm
from statsmodels.stats.diagnostic import acorr_ljungbox导入数据,共204条时间序列数据。
data=pd.read_csv('时间序列数据.txt')
print(data.shape)
print(data.head())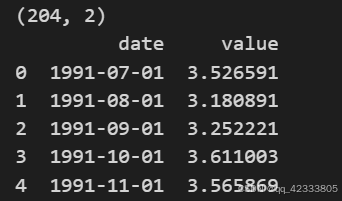
2、绘制时序图
查看时间序列数据走势,可以看出时序数据呈现周期性波动,且振幅越来越大,总体来说有上升的趋势。
plt.figure(figsize=(10,5))
plt.plot(data['value'])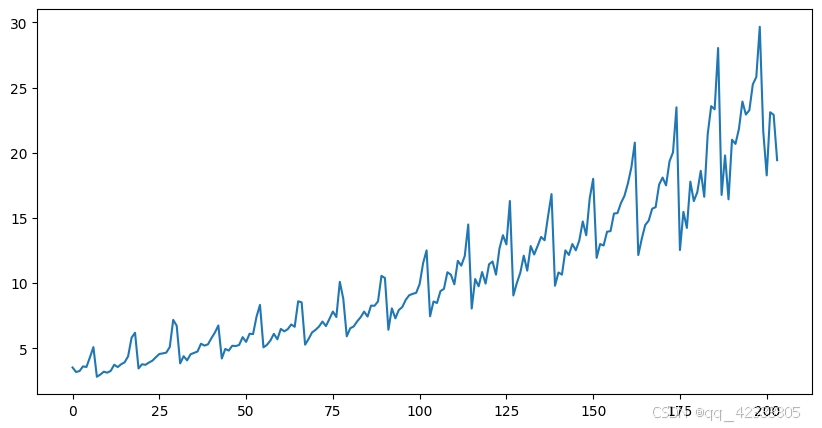
3、平稳性检验
对于平稳性检验,可以从ACF和PACF图进行肉眼观察分析,也可以直接进行ADF单位根检验。
首先从自相关图和偏相关图的角度看看,绘制ACF和PACF图。ACF 图呈现拖尾状态且没有快速收敛,自相关系数显著不为零, 即序列与之前的时刻有强烈的相关性, 偏相关系数也是拖尾的。 综上,该时序数据为非平稳序列。
fig,axes=plt.subplots(2,1, sharex=True)
plot_acf(data.value,ax=axes[0])
plot_pacf(data.value,ax=axes[1])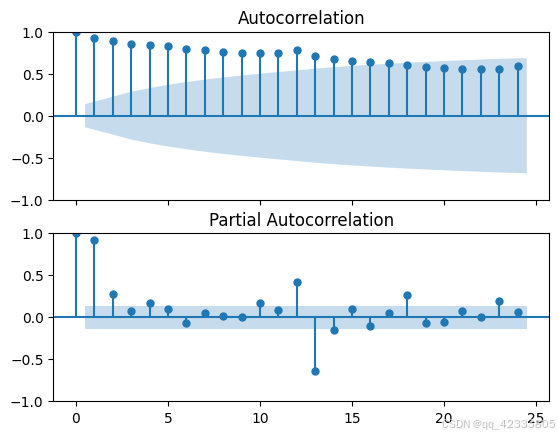
通过数据图判断是否平稳是一种最简单直接的方法,但是带有一定的主观性。下面通过 ADF 检验判断是否为平稳序列。
ADF检验的原假设是:时间序列具有单位根。如果拒绝原假设,则认为不具有单位根,是平稳序列;否则认为是非平稳序列。
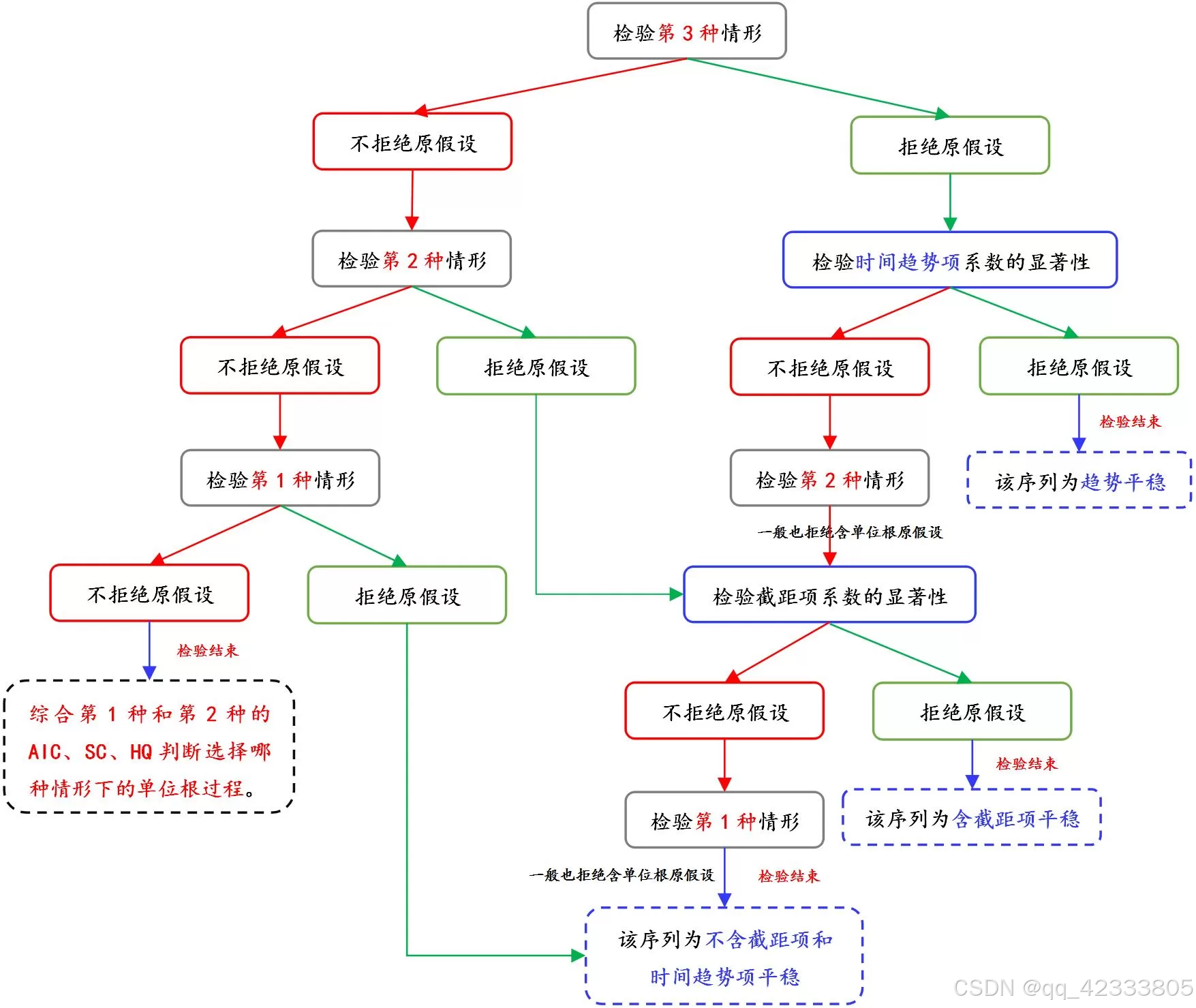
ADF 的检验有三类:(1)第一种情形:不含截距项和趋势项平稳;(2)第二种情形:仅含截距项平稳;(3)第三种情形:含截距项和趋势项平稳。先从第三种情形开始检验,如果不拒绝原假设,认为数据含截距项和趋势项是不平稳;进一步检验是否仅含截距项平稳,如果再次接受原假设;则再进行不含截距项和趋势项平稳性检验。如果上述三种三种情况都不拒绝,说明该序列是不平稳的,应该进行一些数据处理,使得序列变得平稳后在建立模型。
单位根检验判断准则或流程如下图所示(图片来源:实证分析中,大家是如何进行单位根(ADF)检验的?或者ADF检验流程是什么? - 计量经济学与统计软件 - 经管之家(原人大经济论坛) (pinggu.org))
使用adfuller函数进行ADF检验,对于adfuller函数的一些参数说明见这篇文章:如何查看adfuller()函数的模型拟合系数-优快云博客
print(adfuller(data.value.dropna(),regression='ct')) # 含截距项和趋势项平稳检验
print(adfuller(data.value.dropna(),regression='c')) # 含截距项平稳检验
print(adfuller(data.value.dropna(),regression='nc')) # 不含截距项和趋势项平稳检验
本文均假设显著性水平为0.05。按照上述顺序依次进行检验,可以发现三种情形的p值都非常大(1,1,0.99),均大于显著性水平0.05,因而不拒绝原假设,认为该序列是不平稳的。
三、差分与定阶
1、一阶差分
由于数据有较强的趋势性,随着时间推移,其值越来越大。先将其进行一阶差分,去除其趋势性。绘制一阶差分后的时序图:
plt.plot(data.value.diff(1))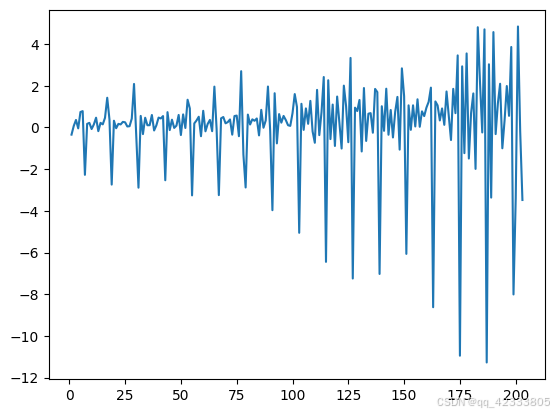
一阶差分后的数据在0附近波动且波动幅度越来越大,此时若对差分后的数据进行平稳性检验,可以发现是含截距项和趋势项的平稳序列。
data['value_d1']=data.value.diff()
print(adfuller(data.value_d1.dropna(),regression='ct')) # 含截距项和趋势项平稳检验
print(adfuller(data.value_d1.dropna(),regression='c')) # 含截距项平稳检验
print(adfuller(data.value_d1.dropna(),regression='nc')) # 不含截距项和趋势项平稳检验
在此时其实也可以直接构建ARMA模型(之前也构建了ARMA模型,但是预测效果不好,本文就没有写出来了),画出差分后的ACF和PACF图,发现存在周期性自相关系数和偏相关系数值显著不为0,仍具有很强的周期性,所以还是应对数据再进行一次季节差分。
fig,axes=plt.subplots(2,1, sharex=True)
plot_acf(data.value.diff(1).dropna(),ax=axes[0])
plot_pacf(data.value.diff(1).dropna(),ax=axes[1])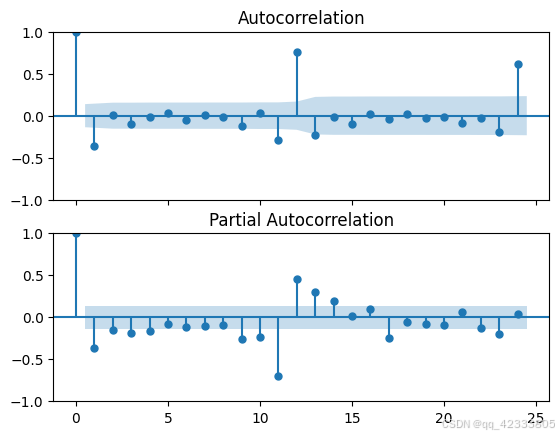
2、季节差分
因时间序列含有较为明显的季节性,再其进行一次季节性差分,可以看出周期是一年,也就是12个月,进行12步差分,消除季节性的影响。差分后的数据在0附近波动,看似平稳数据。相比原始数据图,数据的周期性没有那么明显。
plt.plot(data.value.diff(1).diff(12))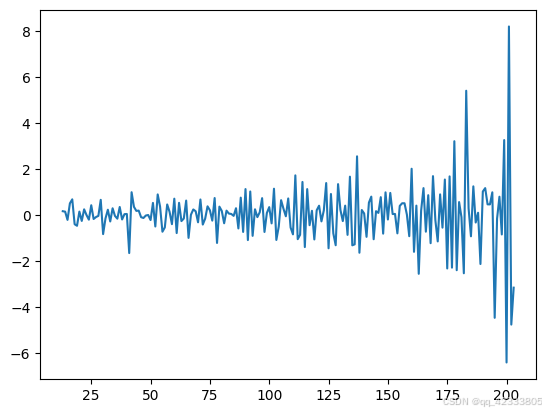
此时再进行平稳性检验,第三种情形检验的p值为0.00068,小于0.05,故拒绝原假设,此时数据是含截距项和趋势项的平稳序列。
data['value_d1_d12']=data.value.diff(1).diff(12)
print(adfuller(data.value_d1_d12.dropna(),regression='ct')) # 含截距项和趋势项平稳检验
print(adfuller(data.value_d1_d12.dropna(),regression='c')) # 含截距项平稳检验
print(adfuller(data.value_d1_d12.dropna(),regression='nc')) # 不含截距项和趋势项平稳检验
进一步输出相应的ADF检验的系数,对于常数项,p值为0.927大于0.05,不拒绝原假设,认为常数项显著为0;而时间趋势项部分变量p值小于0.05,显著不为0,故认为是带有趋势项的平稳序列。
r=adfuller(data.value_d1_d12.dropna(),regression='ct',regresults=True)
print(r[3].resols.summary())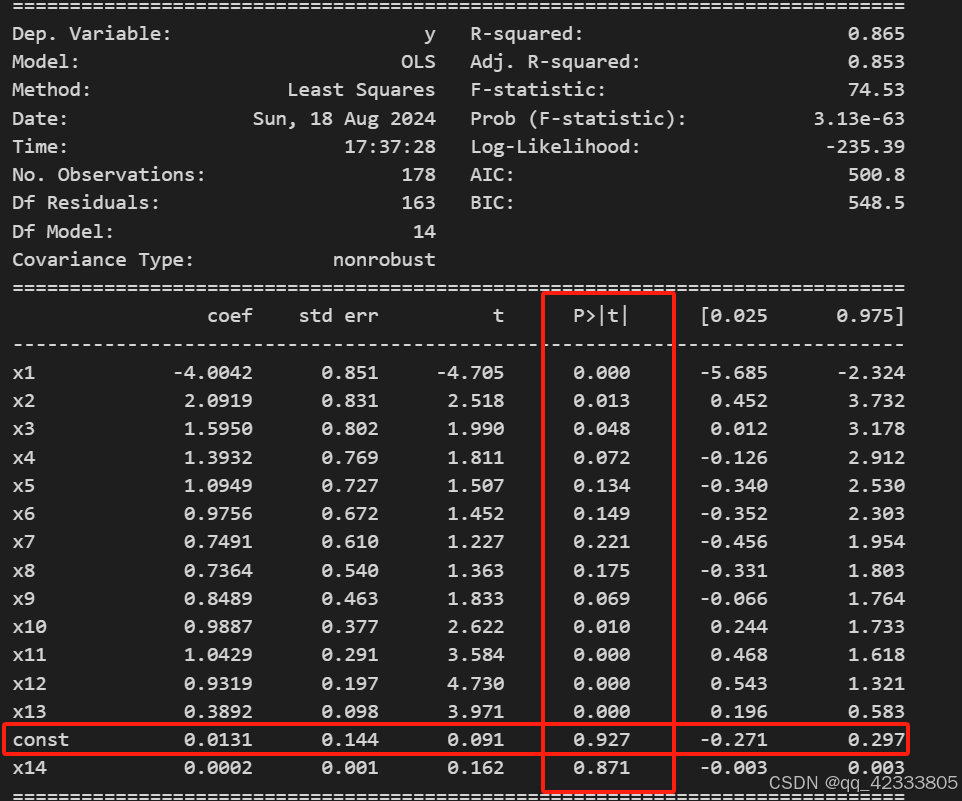
3、白噪声检验
进一步检验是否是白噪声序列,如果是白噪声,说明就是一些随机没有规律的数据,不能从中提取出其他信息,那么就没有建立模型去预测的必要。利用acorr_ljungbox函数进行检验,LB和BP统计量的P值都小于显著水平(α = 0.05),所以拒绝序列为纯随机序列的原假设,认为该序列为非白噪声序列。
acorr_ljungbox(data.value_d1_d12.dropna(),boxpierce=True)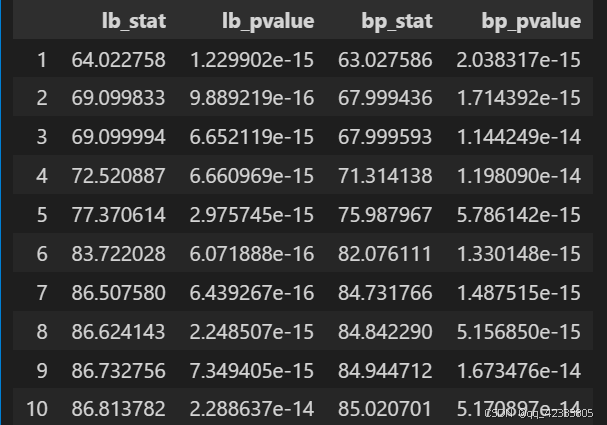
4、ACF和PACF定阶
前面对于序列进行差分后,经检验是平稳序列且不是白噪声,接下来利用ACF和PACF图进行定阶。如果ACF图拖尾,PACF图在q阶后截尾,那么可以认为是AR(q)模型;如果PACF图拖尾,ACF图在p阶后截尾,那么可以认为是MA(p)模型;如果在ACF和PACF图都是拖尾的,但分别在p阶和q阶后快速收敛,那么可以认为是ARMA(p,q)模型。像这种定阶会带有一定的主观性,一般通过ACF和PACF图确定p和q的最大值,再用利用信息准则采用逐步向下的方法选择最优模型。另外,对于p和q的选择,尽量选择较小的,否则会有过多的待估参数。如利用AIC准则选择合适的模型,应选取AIC最小的模型,如果有多个模型,应选择p+q最小的,其次再选择q最小的。
| AR | MA | ARMA | |
| ACF 图 | 拖尾 | 截尾 | 拖尾 |
| PACF 图 | 截尾 | 拖尾 | 拖尾 |
因为数据带有季节性,因此定阶需要从季节性和非季节性分别进行。对于非季节项定阶, 考虑季节差分后的序列𝑚阶以内自相关系数和偏自相关系数的特征;对于季节项定阶观察周期倍阶数(如𝑚阶、 2𝑚阶等等) 的自相关系数和偏自相关系数的特征,并根据上表建立合适的𝐴𝑅𝑀𝐴模型。
fig,axes=plt.subplots(2,1, sharex=True)
plot_acf(data.value_d1_d12.dropna(),ax=axes[0],lags=36)
plot_pacf(data.value_d1_d12.dropna(),ax=axes[1],lags=36)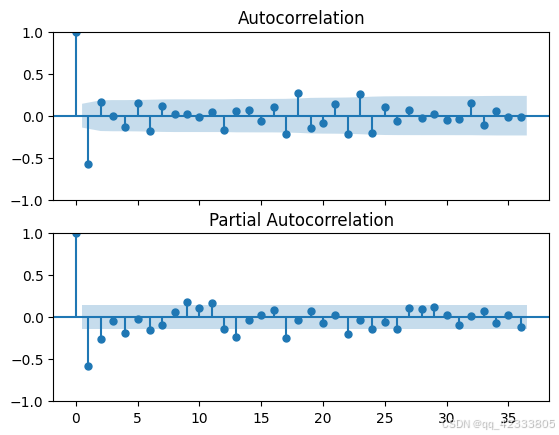
根据上图进行分析,得到以下结论:
对于季节项定阶:ACF和PACF周期倍(滞后12阶、24阶)的值都存在拖尾,但后续阶数均在快速收敛。从PACF图来看:从滞后阶数12阶、24阶来看,滞后24阶后较为收敛,故P最大值为2。从ACF图来看:考虑从滞后阶数12阶、24阶、36阶来看,滞后12阶后截尾,可以考虑MA模型,Q最大值为1。综合来看,可以考虑ARMA和MA模型,故根据PACF图定P的最大阶数为2阶;根据ACF图定Q的最大阶数为1阶。
对于非季节项定阶:ACF和PACF都存在拖尾,但后续阶数均在快速收敛。从PACF图来看p阶数:2阶后收敛,p最大值为2。从ACF图来看q阶数:1阶后收敛,q最大值为1。可以考虑ARMA模型,根据PACF图定p的最大阶数为2阶;根据ACF图定q的最大阶数为1阶。
四、SARIMA模型构建
1、模型构建
train = data.value[:180]
test = data.value[180:] # 最后两年作为测试集由于进行一次差分,故d=1;进行了一次季节差分D=1;周期性是12,故m=12;季节性的P=2,Q=1,非季节性p=2,q=1。auto_arima参数的说明可以看这篇博客时间序列分析|auto_arima调参_autoarima-优快云博客
smodel = pm.auto_arima(train.dropna()
,start_p=0, start_q=0,
start_P=0,start_Q=0,
test='adf',
max_P=2, max_Q=1,
max_p=2, max_q=1
, m=12,d=1, D=1,
seasonal=True,
trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
smodel.summary()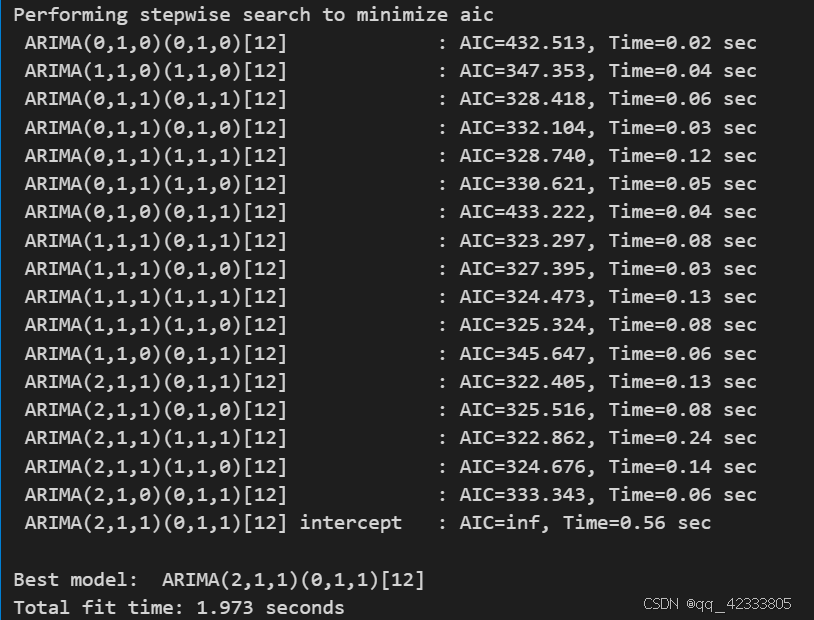
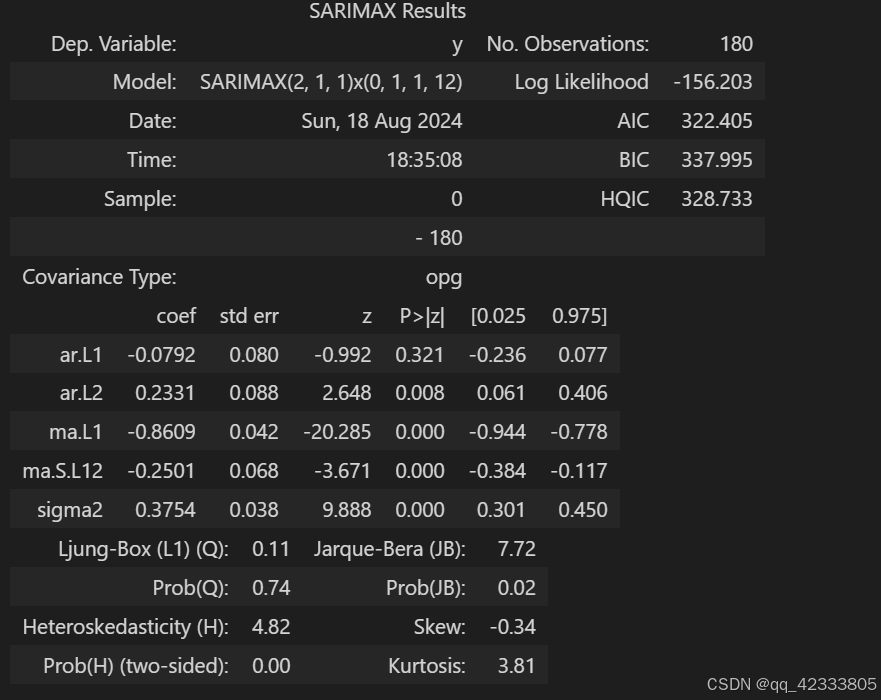
最后选择的SARIMA(2,1,1)(0,1,1)[12] 模型,其AIC值最小为322.405。
2、残差图
绘制残差图,残差在0附近波动,其密度曲线服从正态分布。自相关图在滞后阶数都在置信区间内,说明数据为白噪声。
smodel.plot_diagnostics(figsize=(10,8))
plt.show()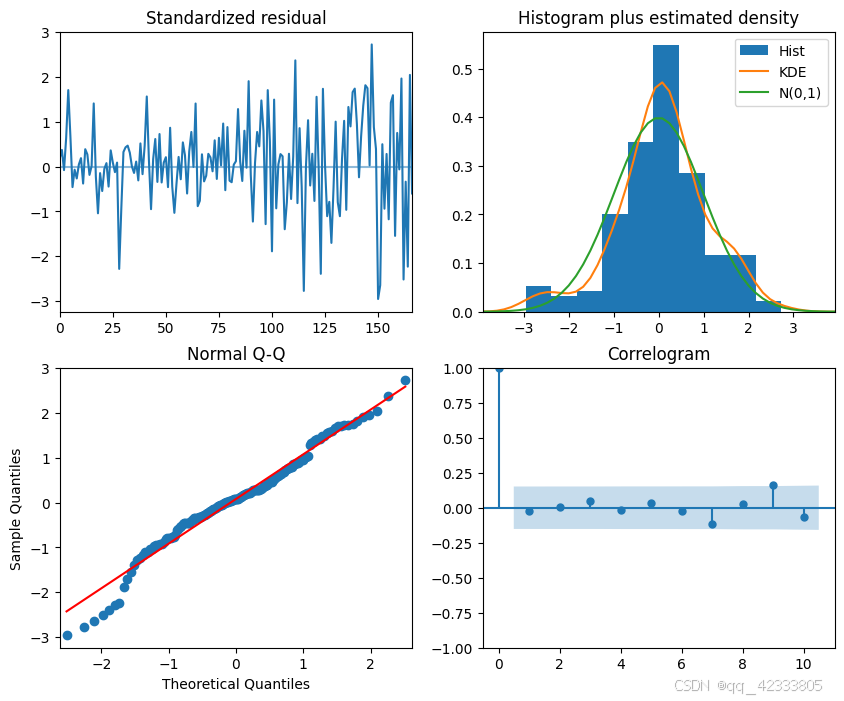
接下来进行假设检验判断残差是否为白噪声。
residuals = pd.Series(smodel.resid())
acorr_ljungbox(residuals,boxpierce=True)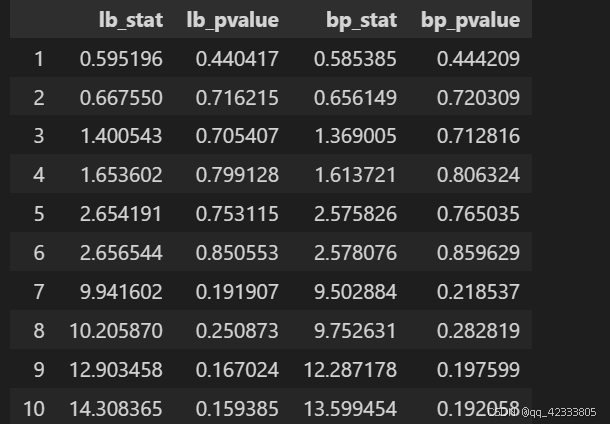
LB和BP统计量的P值都大于显著水平(α = 0.05),所以不拒绝序列为纯随机序列的原假设,认为该序列为白噪声序列。
3、模型预测
# 预测后两年的数据 n_periods = 24 fitted, confint = smodel.predict(n_periods=n_periods, return_conf_int=True) fitted_series = pd.Series(fitted) lower_series = pd.Series(confint[:, 0]) upper_series = pd.Series(confint[:, 1]) # 画图 plt.plot(data.value,label='real') plt.plot(smodel.predict_in_sample(),label='train_predict') plt.plot(fitted_series,label='test_predict') plt.title("SARIMA -predict_result")plt.legend(loc='upper left', fontsize=8) plt.show()
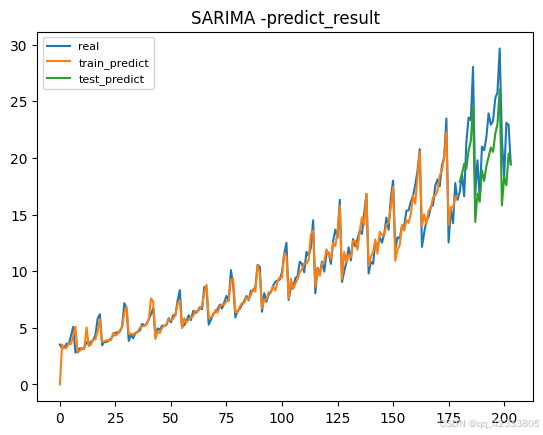
可见模型预测效果也较好。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









