






目录
所用的方法和数据来自于b站:1-KLOOK旅游数据分析项目—背景介绍_哔哩哔哩_bilibili
本文只是一些自己学习的代码,对于一些分析,可以去看视频学习。前面部分太简单不做复盘,只对一些指标构建进行实战。指标部分可能由于不同业务场景导致定义会有差别,只做参考。
将从复购率、回购率、用户分类、用户生命周期、留存率来展开。
数据查看
import pandas as pd
from datetime import datetime
import numpy as np
data=pd.read_csv('kelu.csv')
data.head()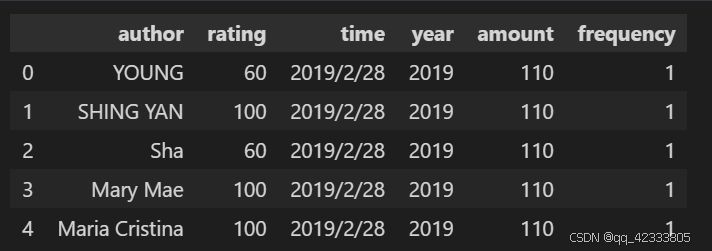
数据只有六列,分别是用户名、评分、消费时间、年份、金额、频率。
在判断消费行为时以月份为度量,故将时间作变换,提取月份数据。
data['time'] = pd.to_datetime(data['time'],format='%Y/%m/%d') # 将其转成日期的格式
data["month"]=data["time"].values.astype('datetime64[M]') #保留月份精度的日期
data.head()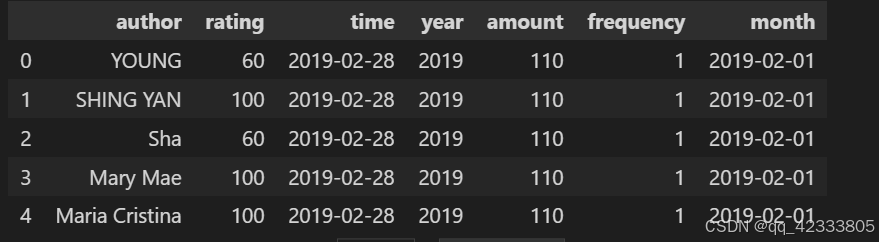
1、复购率
复购率:在一个月内消费次数在两次以上的用户在该月总消费用户的占比。
1.1 用分组的方法来做
# 每个用户在每个月购买了几次
groupby_1=data.groupby(["author","month"]).count().reset_index()
groupby_1
# 在每个月内消费两次以上的用户数量-- 复购人数
user_2_count=groupby_1[groupby_1["rating"]>1].groupby("month")["author"].count().reset_index(name="user_2_count")
# 每个月的用户数量
user_sum_count=groupby_1.groupby("month")["author"].count().reset_index(name="user_sum_count")
df1=user_sum_count.merge(user_2_count,how="left",on="month").fillna(0)
df1["复购率"]=df1["user_2_count"]/df1["user_sum_count"]
df1.head()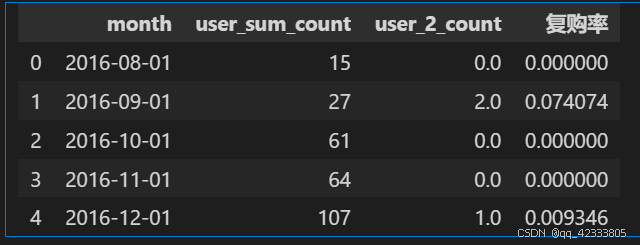
第二列user_sum_count是每月的消费人数,第三列user_2_count是每月消费两次及以上的人数,两者相除得到复购率。
1.2 用透视表的方法来做
# 建立数据透视表,展示每个用户每一个月的消费情况
pivot_count=data.pivot_table(index="author",columns="month",values="frequency",aggfunc="count").fillna(0)
pivot_count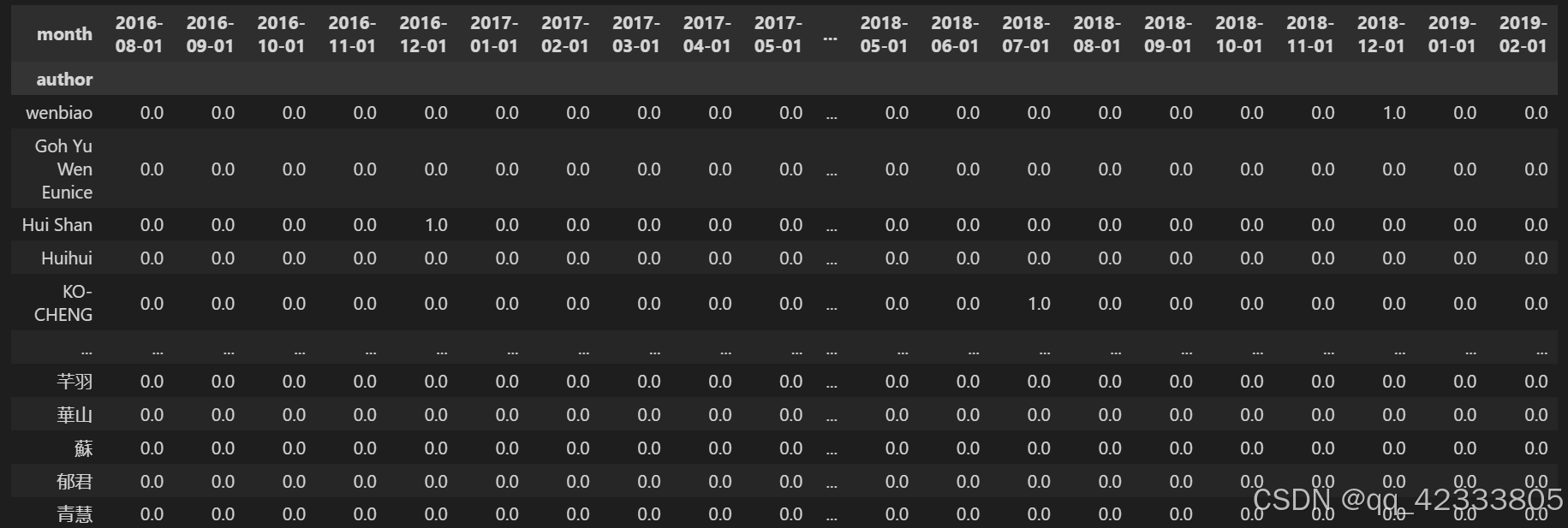
以上数据透视表,纵坐标是每一个用户,横坐标是每个月份,中间数据就是用户在该月份消费的次数。消费次数大于1则属于复购,等于1不是复购。
# 进行处理,消费次数大于1的记为复购用户,记为1;消费1次的是非复购用户;没有消费的是nan
pivot_count=pivot_count.applymap(lambda x :1 if x>1 else np.nan if x==0 else 0)
# 计算复购率
(pivot_count.sum()/pivot_count.count()).plot()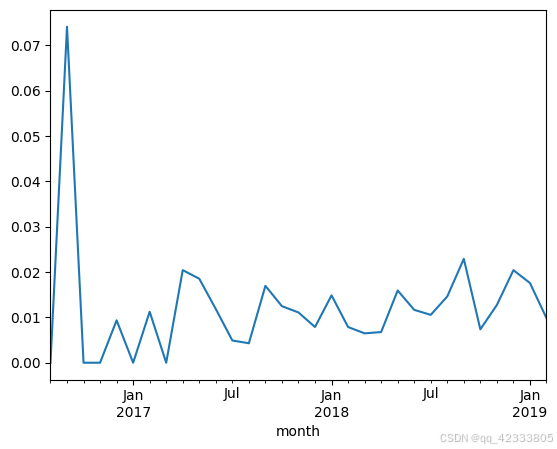
pivot_count.sum()/pivot_count.count()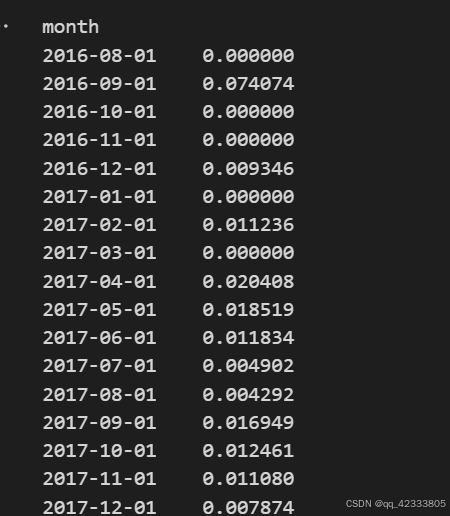
2、回购率
回购率:在当月进行消费,在下一个月仍然消费的占比。
# 建立数据透视表,展示每个用户每一个月的消费情况
pivot_purchase=data.pivot_table(index="author",columns="month",values="frequency",aggfunc="count").fillna(0)
pivot_purchase# 写一个函数判断回购
def purchase_return(data): # data代表的是每一名游客的所有月份消费记录
status=[]
for i in range(30): # pivot_purchase.shape[1]
if data[i]>=1: # 本月有消费
if data[i+1]>=1: # 下月有消费
status.append(1)
else:
status.append(0)
else :# 本月无消费
status.append(np.nan)
status.append(np.nan) # 对于最后一个月,展示为nan
return pd.Series(status,pivot_purchase.columns)
# 用户每月回购状态
pivot_purchase_return=pivot_purchase.apply(purchase_return,axis=1)
pivot_purchase_return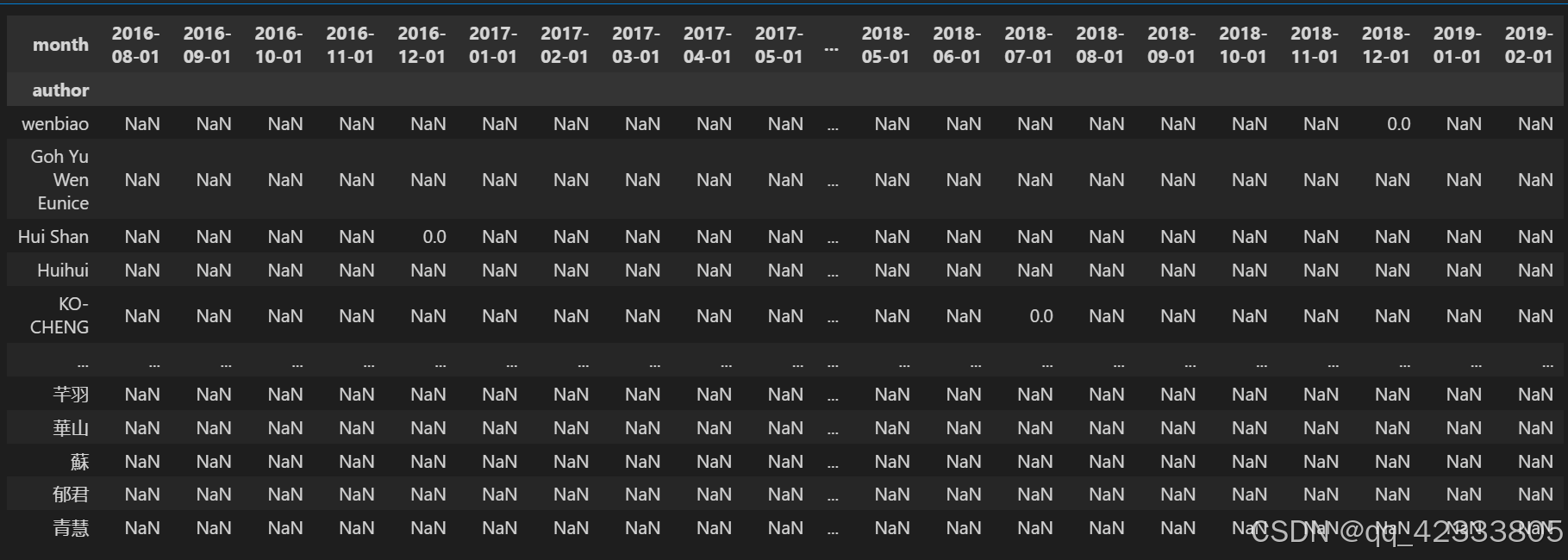
类似的,以上数据透视表,纵坐标是每一个用户,横坐标是每个月份,中间数据就是用户在该月份的回购状态。值为1说明该用户在该月有回购行为,值为0说明该用户在该月没有回购行为,值为nan说明该用户在该月没有消费。
对于每一列求和,则是每月回购的人数;对每一列进行计数,则是每月的总人数。
# 回购率计算
pivot_purchase_return.sum()/pivot_purchase_return.count()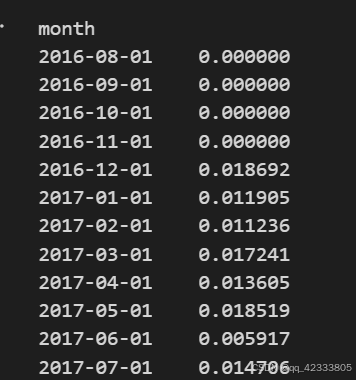
(pivot_purchase_return.sum()/pivot_purchase_return.count()).plot()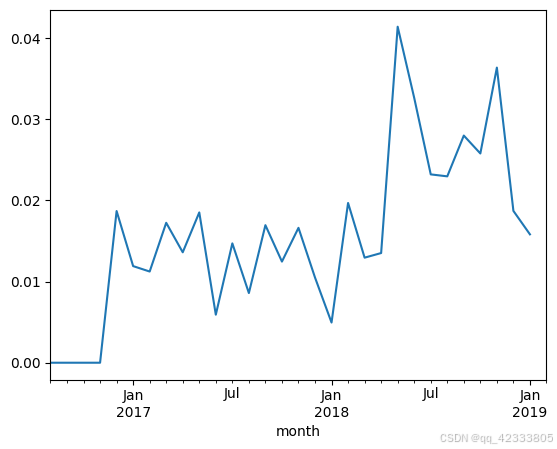
3、用户分类
根据以下规则将用户分成四类。
①活跃用户:这个月消费,下个月也消费
②不活跃用户:曾经有过消费,现在没有消费
③回流用户:曾经消费,又不消费,后面有消费了
④新用户:以前没有消费,现在有消费
# 建立函数判断用户类型
def active_status(data):
status=[]
for i in range(31):
if data[i]==0: # 本月没有消费
if len(status)==0: # 如果是第一个月
status.append("unreg")
else : # 如果不是第一个月
if status[i-1]=="unreg" :# 如果上一个月的状态是未注册状态,则之前一直没有消费过
status.append("unreg")
else: # 之前有过消费
status.append("unactive")
else : # 本月有消费
if len(status)==0: # 如果是第一个月
status.append("new") # 第一次消费
else:# 如果不是第一个月
if status[i-1]=="unactive" : # 上一个月是不活跃用户,本月有消费
status.append("return")
elif status[i-1]=="unreg" : # 上一个月是未注册用户,本月有消费
status.append("new")
else: # 上一个月是新用户或者活跃用户,这个越是活跃用户
status.append("active")
return pd.Series(status,pivot_purchase.columns)
pivot_purchase_status=pivot_purchase.apply(active_status,axis=1)# 计算每种用户状态每个月的数量,对于未注册类型不进行统计
pivot_purchase_count=pivot_purchase_status.replace("unreg",np.nan).apply(pd.value_counts)
# 绘制面积图去分析
pivot_purchase_count.T.plot.area()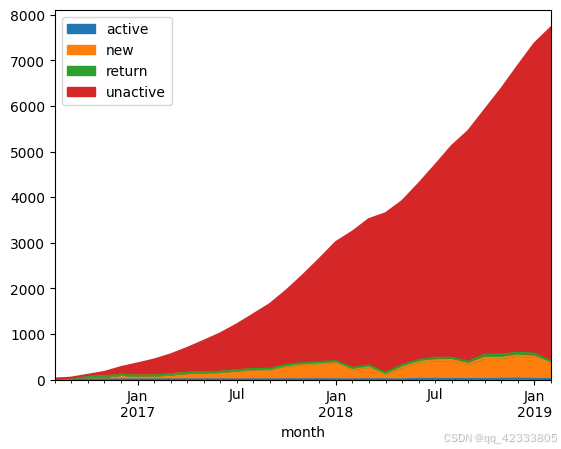
# 计算每月不同用户的占比
pivot_purchase_count.apply(lambda x:x/x.sum()).T.plot()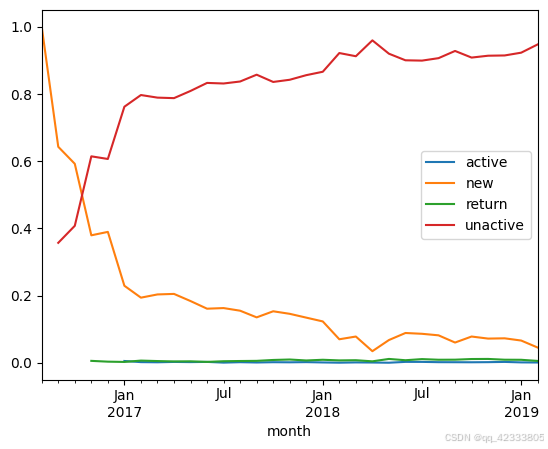
4、用户生命周期
用户生命周期:即最后购买时间与第一次购买时间的天数
# 计算每个用户最早和最后购买时间
time_min=data.groupby("author")["time"].min()
time_max=data.groupby("author")["time"].max()
left_time=(time_max-time_min).reset_index()
left_time.describe() # 平均生命周期23天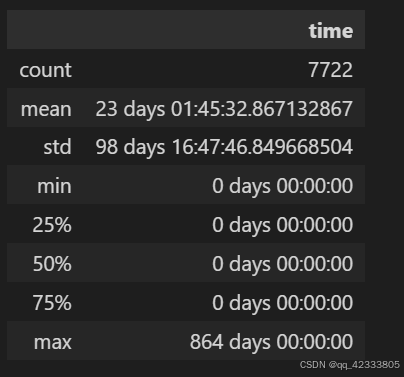
# 直方图绘制
left_time["left_time"]=left_time["time"]/np.timedelta64(1,"D") # 保留一位小数,格式化为天
left_time["left_time"].plot.hist()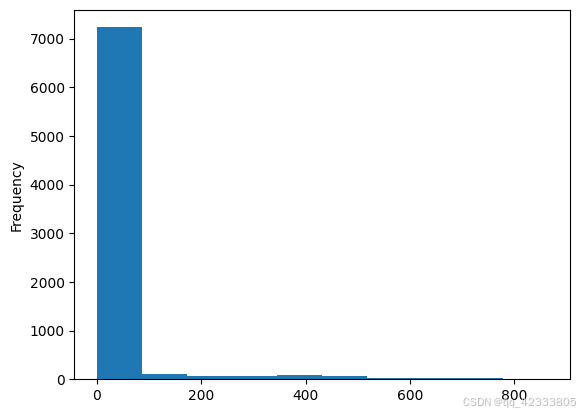
# 生命周期大于0的直方图
left_time[left_time["left_time"]>0]["left_time"].plot.hist(bins=100)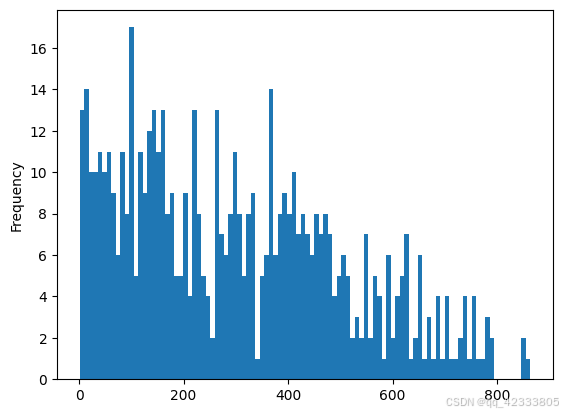
5、留存率
留存天数:每一次购买天数与第一次购买天数的差。
# 计算留存天数
data_purchase_retention=data.merge(time_min.reset_index(),how="left",on="author",suffixes=["","_min"])
data_purchase_retention["time_diff"]=(data_purchase_retention["time"]-data_purchase_retention["time_min"])/np.timedelta64(1,"D")
data_purchase_retention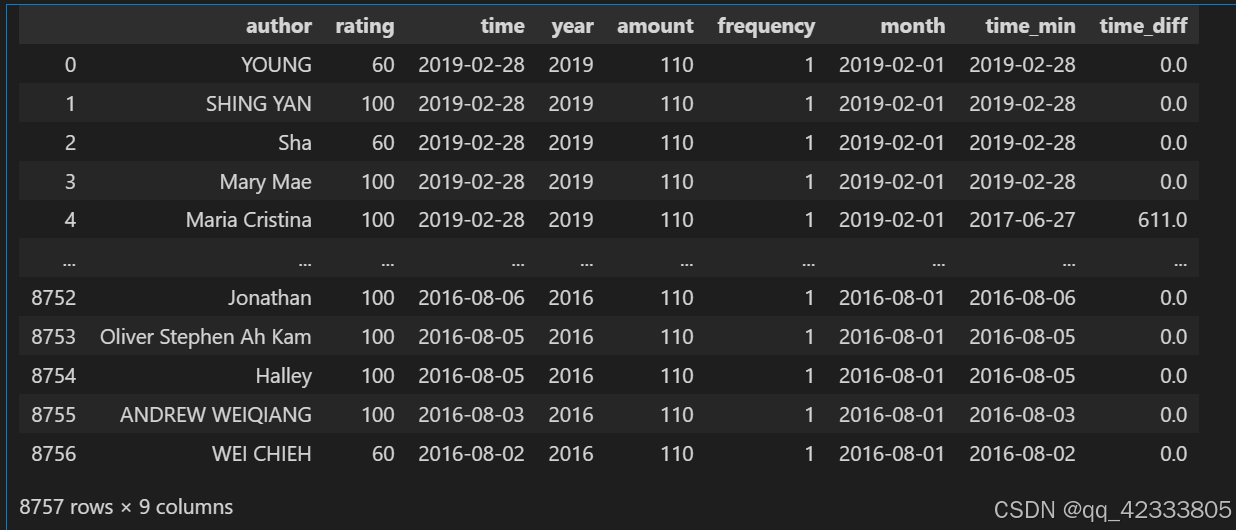
# 将留存天数分组,间隔90天分一次组
bin=list(range(0,990,90))
data_purchase_retention["time_diff_bin"]=pd.cut(data_purchase_retention["time_diff"],bins=bin)
data_purchase_retention
# 判断用户在某个留存天数内是不是留存用户,即计算每个用户在在不同区间的消费次数
pivot_retention=data_purchase_retention.groupby(["author","time_diff_bin"])["frequency"].sum().unstack()
# 判断是否是留存用户
pivot_retention_trans=pivot_retention.applymap(lambda x:1 if x>0 else 0)
pivot_retention_trans
# 留存率 计算在留存天数区间内有消费的人数/总人数
pivot_retention_trans.sum()/pivot_retention_trans.count()
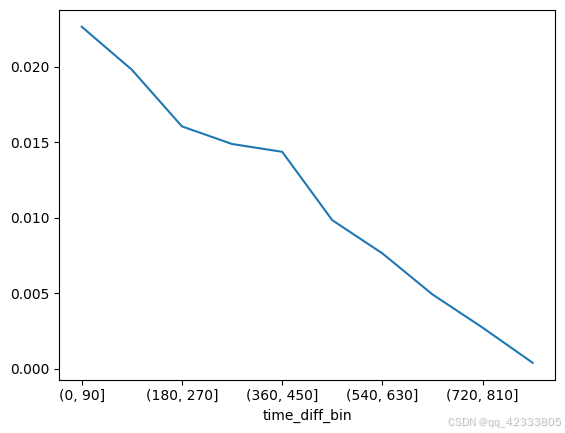
(pivot_retention_trans.sum()/pivot_retention_trans.count()).plot()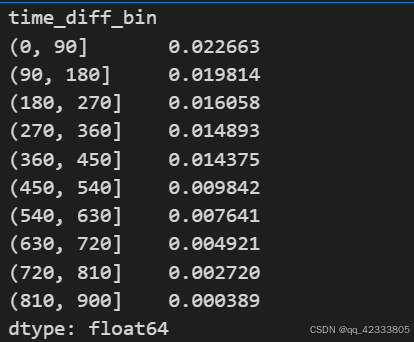
该计算结果表达在某个留存天数内留存率是多少,比如留存天数是在0-90天内,留存率是2.26%。
可视化结果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









