







 本文介绍了如何使用Python爬虫框架Scrapy从拉勾网抓取职位信息,并进行数据分析。首先分析了拉勾网职位列表页的Ajax请求,接着创建Scrapy项目,编写item和爬虫文件,利用pipeline处理数据。最后,通过jupyter notebook结合pandas、numpy和matplotlib对数据进行清洗、筛选和图表展示,包括城市分布、学历水平、工作经验及薪资水平的分析。
本文介绍了如何使用Python爬虫框架Scrapy从拉勾网抓取职位信息,并进行数据分析。首先分析了拉勾网职位列表页的Ajax请求,接着创建Scrapy项目,编写item和爬虫文件,利用pipeline处理数据。最后,通过jupyter notebook结合pandas、numpy和matplotlib对数据进行清洗、筛选和图表展示,包括城市分布、学历水平、工作经验及薪资水平的分析。
需求:1.使用python爬虫框架,爬取拉勾网职位信息,
2.将爬取的职位信息存储到json格式的文件中
3.将爬取的数据进行数据分析
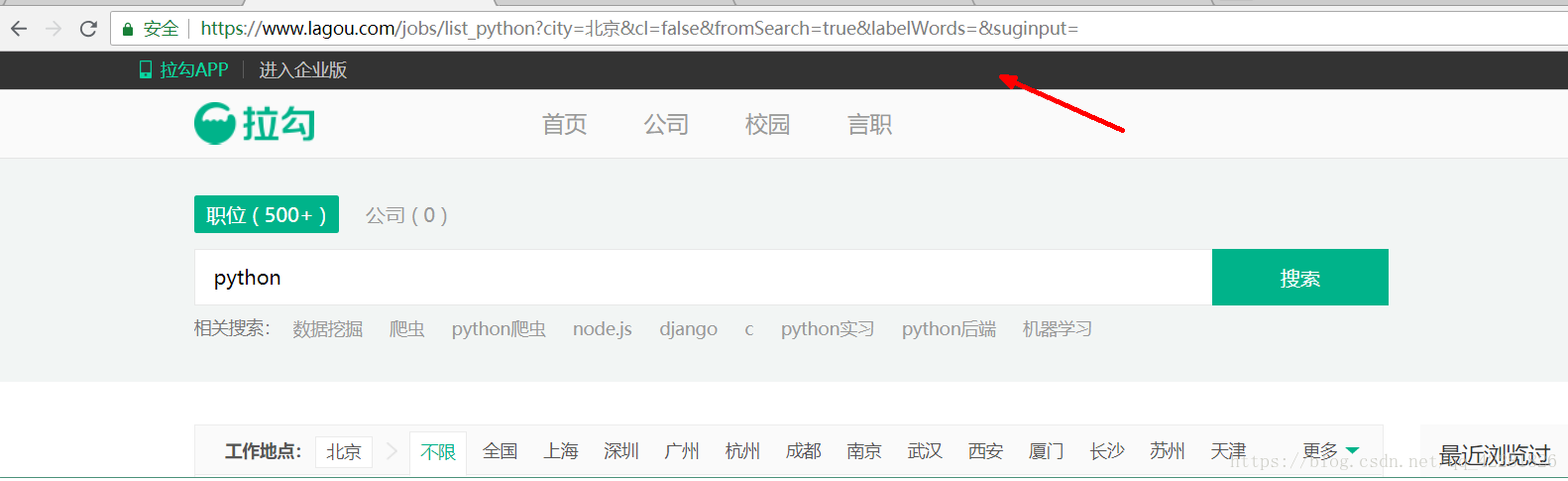
1.图片中的链接是职位列表页的链接,进行翻页,该链接没有变化,无法从该链接中爬取数据
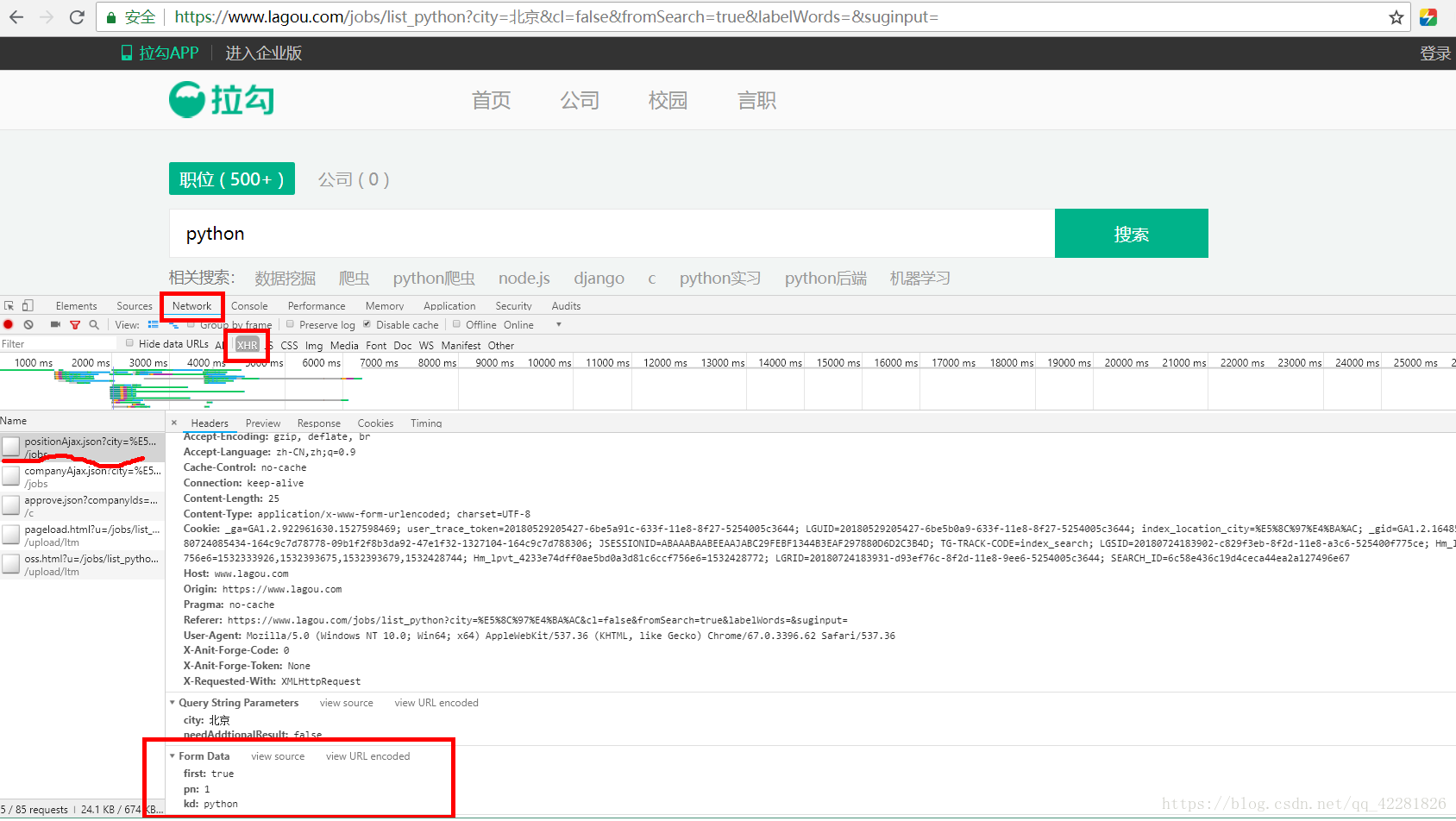
2.打开浏览器开发者模式,点击network的XHR,同时刷新页面,会出现ajax请求是post请求,红框中的Form Data是ajax请求需要携带的数据,kd是要搜索的职位
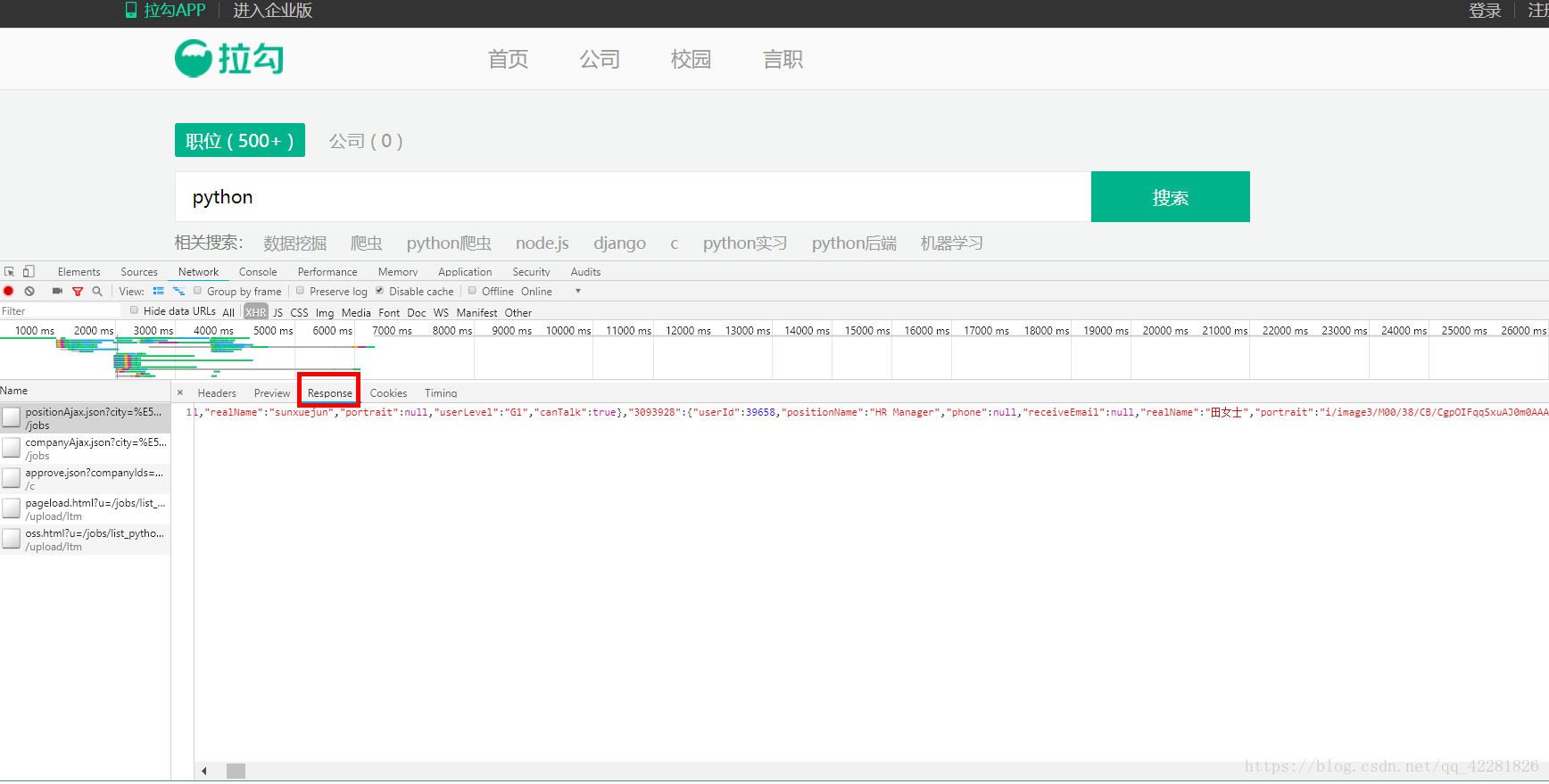
3.点击红框中的Response会看到ajax请求回的数据,
以上是拉勾网职位列表页分析,接下来进行网页信息爬取
步骤:
一.
创建scrapy项目:scrapy startproject lagouscrapy
进入项目目录中:cd lagouscrapy
创建爬虫文件:scrapy genspider worklagou lagou.com
二.使用pycharm编辑项目
1.编辑item.py文件,编辑要爬取的字段
import scrapy
class SelflagouItem(scrapy.Item):
# 爬取职位名称,学历要求,公司名称,工作经历,公司位置,工资水平几个字段
title=scrapy.Field()
education=scrapy.Field()
company=scrapy.Field()
experience=scrapy.Field()
location=scrapy.Field()
salary=scrapy.Field()
2.编写爬虫 worklagou.py文件
根据以上分析,拉勾网的职位信息是ajax的请求,所以
# -*- coding: utf-8 -*-
import json
import scrapy
from scrapy import FormRequest
from selflagou.items import SelflagouItem
class WorklagouSpider(scrapy.Spider):
name = 'worklagou'
allowed_domains = ['lagou.com']
# kd是要爬取的职位,拉勾网的职位信息是通过ajax,将kd设置为输入框,可以输入你想要爬取的职位
kd = input('输入职位:')
start_urls = ['https://www.lagou.com/jobs/list_'+str(kd)]
# 设置cookie和Referer
headers={
'Cookie':'_ga=GA1.2.922961630.1527598469; user_trace_token=20180529205427-6be5a91c-633f-11e8-8f27-5254005c3644; LGUID=20180529205427-6be5b0a9-633f-11e8-8f27-5254005c3644; index_location 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









