




 本文介绍如何使用Scrapy爬取拉勾网的Java招聘岗位信息,通过Postman分析请求,发现并处理异步请求和反爬机制,最终成功获取到真实数据并保存为xlsx文件。
本文介绍如何使用Scrapy爬取拉勾网的Java招聘岗位信息,通过Postman分析请求,发现并处理异步请求和反爬机制,最终成功获取到真实数据并保存为xlsx文件。
又到了一年一度的招聘热季节,大量的工作机会在想我们招手,为了了解一下热门岗位的薪资情况,这里爬取拉钩网的Java招聘岗位,,这里使用Scrapy来完成。并保存为xlsx文件。这里不做条件筛选,只对关键词进行筛选。这节作为准备,只讲拉钩的爬取规则,以及如何反爬。
工具:浏览器,Postman,IDE,Python环境,Win10。
Python:Scrapy,Openpyxl,Json
首先访问一下拉钩搜索“java”关键字:
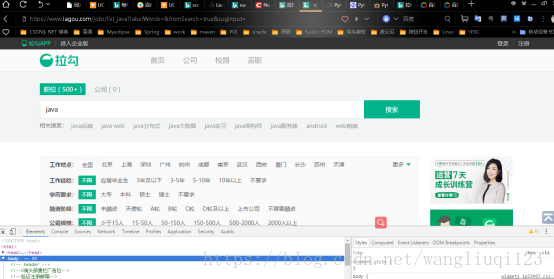
拿到url后,复制粘贴到Postman中访问一遍:
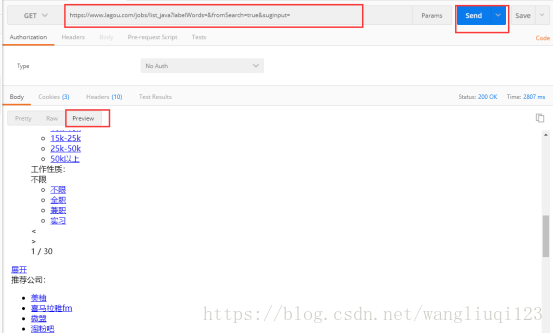
跟我们想的一样。数据都是异步刷新出来的。所以我们要找异步请求的地址,打开浏览器F2 控制台。切到Network 下,清空之前的网络请求后,点击第二页(查看浏览器发送的请求):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









