







前序
前面学了很多内容,这里进行一个融合使用,做一个根据私域数据,来进行检索回答的助手。需要用到LLM,用到Prompt,用到文档加载,文档分割,embedding,Milvus数据库保存,fastapi提供接口服务等等,这个后续如果有需要,也可以用vue或者其他画一个聊天界面等。
RetrievalQA简介
LangChain 的 RetrievalQA 是一种基于检索增强生成(RAG)的问答链,用于将外部知识库与大语言模型(LLM)结合,解决模型数据时效性和领域特定知识不足的问题。
RetrievalQA也是一种Chain,它的作用是“先检索,后生成”,即检索增强生成。
基于RetrievalQA 的AI助手
1.langsmith配置
langsmith或者其他可能需要用到的key,先配置在这,免得langsmith报警告啥的,也可以起到监控作用。
import os
os.environ['LANGSMITH_API_KEY'] = "lsv2_xx"
os.environ["TAVILY_API_KEY"] = "tvly-dev-8xxx"
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
2.准备大模型
这里依然用的deepseek,不过,为了迎合langsmith,做了处理
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="deepseek-chat", base_url="https://api.deepseek.com",
api_key="sk-e24xxxf")
3.准备文档一份文档,作为私域补充数据
这里随便网上找了点数据(当然也可以用自己的一些内部文档)保存到data.txt中
3月4日,全国人大代表、小米集团董事长兼CEO雷军在微信公众号发文公布其2025两会人大代表建议。
雷军本次带来了5份建议,包括关于加快推进自动驾驶量产的建议、关于发展智能网联新能源汽车产业生态的建议、关于加快推进人工智能终端产业高质量发展的建议、关于优化新能源汽车号牌设计的建议、关于加强“AI换脸拟声”违法侵权重灾区治理的建议。
其中,雷军表示,绿色的号牌与车体颜色的兼容性较差,不利于产品外观设计实现更高突破,建议有关部门能够启动新能源汽车号牌式样的调研论证,公开征求意见建议。
雷军建议,加快推进自动驾驶汽车全国性测试验证,力争2025年建立跨区域、跨省份、一体化的便捷互认机制,建立自动驾驶汽车在全国上路的统一管理流程和机制。在确保安全的前提下,给予自动驾驶汽车全国性测试验证的绿色通道,推动自动驾驶技术快速成熟应用。
雷军还建议,尽快明确自动驾驶汽车的量产时间预期,进一步扩大准入和上路通行试点力度,支持更多企业和车型试点验证,力争2026年可支持高速快速路自动驾驶、城市自动驾驶等功能的量产应用,加快推动自动驾驶汽车量产上市,为用户提供更加优质的用车体验。
文档加载分割:
注意:分割和存储只需要操作一次就行了。
# 加载文档
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./data.txt', encoding='utf-8')
documents = loader.load()
# 分割文档
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# print(texts)
# print([(key, text) for key, text in enumerate(texts)])
4. 设置embedding模型
这里还是用之前的zhipuai
# 设置embeddings模型
os.environ["ZHIPUAI_API_KEY"] = "a225683xxO"
from langchain_community.embeddings import ZhipuAIEmbeddings
embeddings_model = ZhipuAIEmbeddings(
model="embedding-3",
dimensions=1024
)
5.配置Milvus数据库并将分割好的文档存储
注意:存储只需要存储一次就好了。不需要多次存储
# Milvus配置,连接使用Milvus
from langchain_milvus import Milvus
milvus_host = "127.0.0.1" # Milvus服务器的主机名或IP地址
milvus_port = "19530" # Milvus服务器的端口
vector_store = Milvus(
embedding_function=embeddings_model,
connection_args={"host": milvus_host, "port": milvus_port},
auto_id=True, # 设置集合中的数据为自动增长ID,默认是False
collection_name="ai_use",
)
# 获取检索器,选择 top-2 相关的检索结果
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# 将文档保存到Milvus中
vector_store.add_documents(texts)
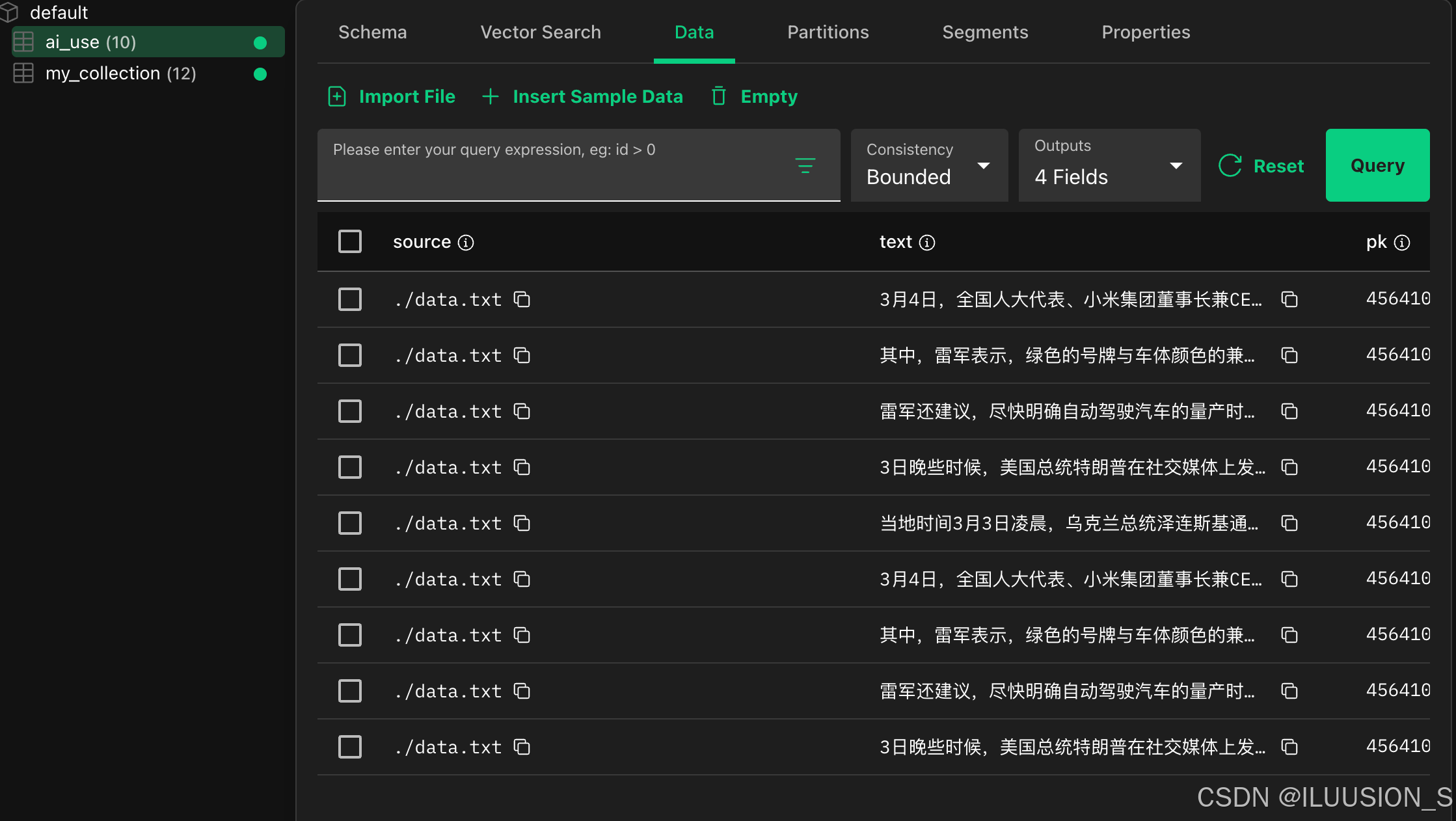
我这里就多次运行程序,所以生成了多分文档数据
6. 设置ChatPromptTemplate
from langchain.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个AI管家。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
请用中文回答用户问题。
已知信息:
{context} """),
("user", "{question}")
])
# 自定义的提示词参数
chain_type_kwargs = {"prompt": prompt}
7. 定义RetrievalQA链
# 定义RetrievalQA链
# from langchain.chains import RetrievalQA
from langchain.chains.retrieval_qa.base import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 使用stuff模式将上下文拼接到提示词中
chain_type_kwargs=chain_type_kwargs,
retriever=retriever,
)
8. 构建fastapi应用,提供网络请求接口服务
# 构建 FastAPI 应用,提供服务
app = FastAPI()
# 可选,跨域配置
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
# 定义请求模型
class QuestionRequest(BaseModel):
question: str
# 定义响应模型
class AnswerResponse(BaseModel):
answer: dict
9.定义查询接口
import uvicorn
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from starlette.middleware.cors import CORSMiddleware
# 提供查询接口 http://127.0.0.1:8000/ask
@app.post("/ask", response_model=AnswerResponse)
async def ask_question(request: QuestionRequest):
try:
# 获取用户问题
user_question = request.question
print(user_question)
# 通过RAG链生成回答
answer = qa_chain.invoke({"query": user_question})
# 返回答案
answer = AnswerResponse(answer=answer)
print(answer)
return answer
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
10.启动服务
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
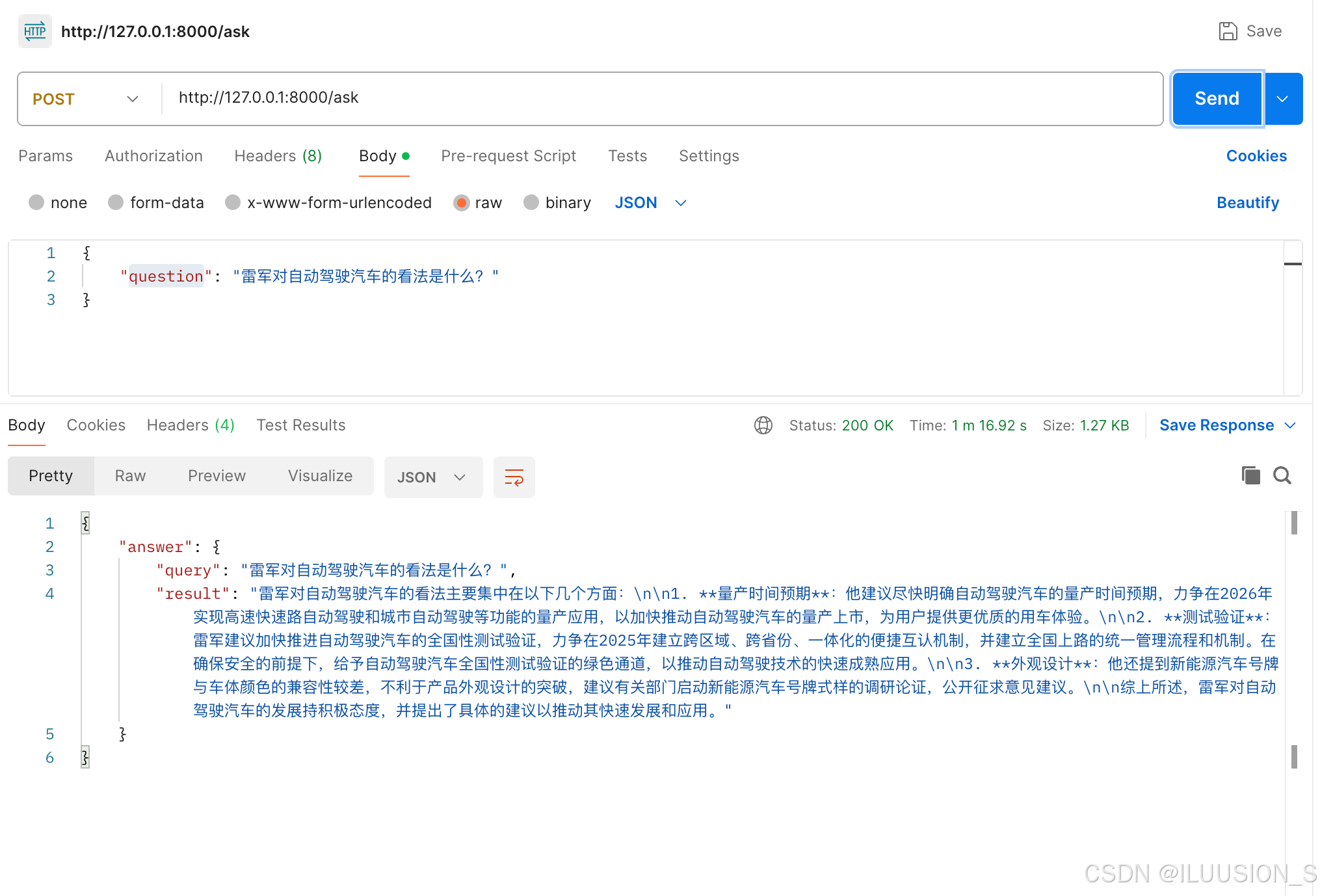
运行结果如下:

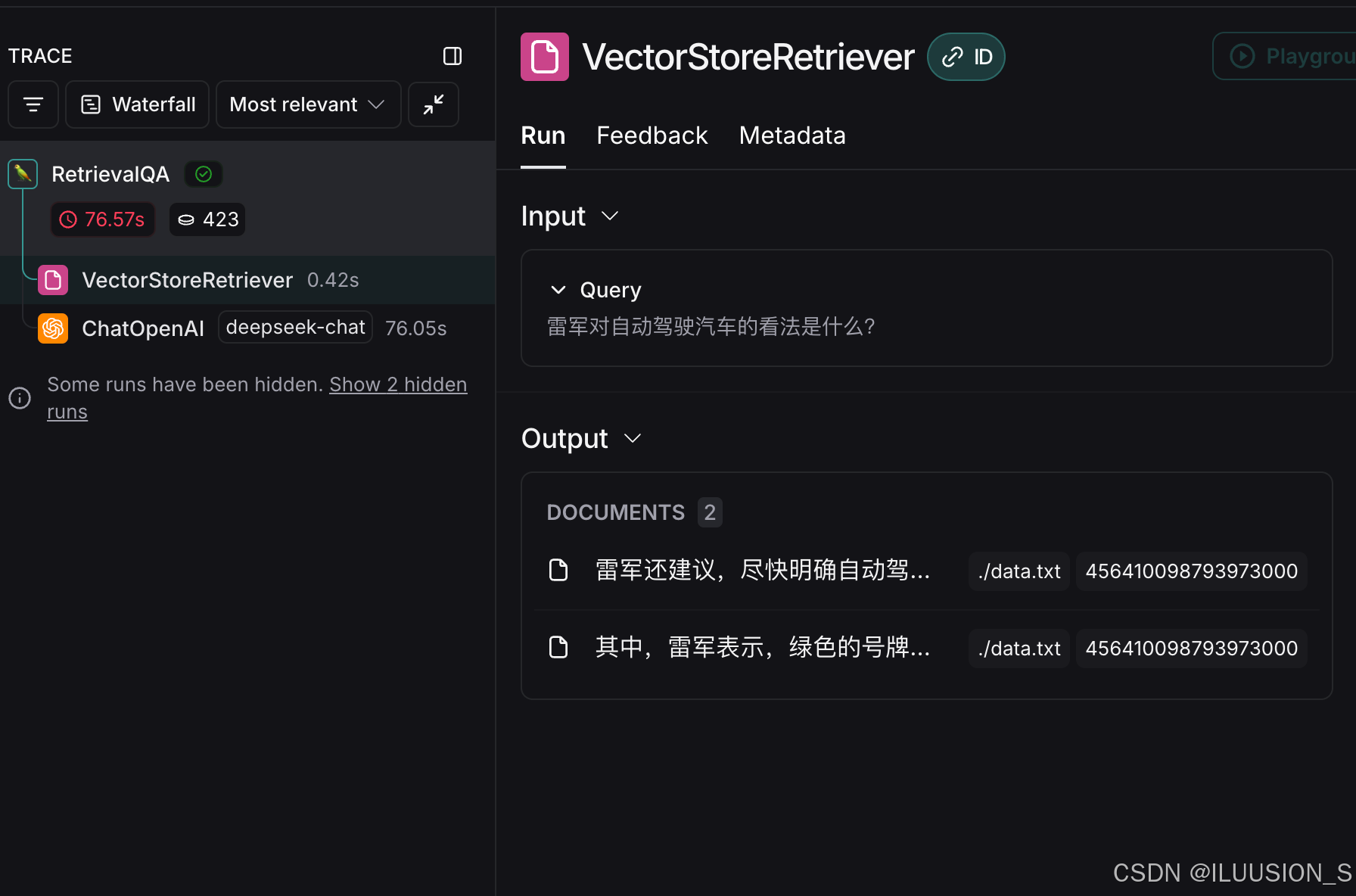
通过LangSmith也可以清晰看出每一步结果

思考优化点
- 把文档加载和存储单独拆开,避免多次加载重复存储。
- 可以结合vue或者其他,制作一个界面。用于交互
- 可以结合RunnableWithMessageHistor存储消息。
- 结合RedisCache,把输出缓存到Redis数据库中,减少推理时间和省💰



















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











