







 本文探讨了随机算法在解决复杂问题时的优势,如快速排序和最大割问题的随机化解决方案。介绍了蒙特卡洛和拉斯维加斯算法的差异,并详细阐述了随机快排的期望复杂度分析。此外,还深入讨论了散列法,包括通用散列函数的设计和完美散列的概念,以实现高效的内存管理和查找操作。
本文探讨了随机算法在解决复杂问题时的优势,如快速排序和最大割问题的随机化解决方案。介绍了蒙特卡洛和拉斯维加斯算法的差异,并详细阐述了随机快排的期望复杂度分析。此外,还深入讨论了散列法,包括通用散列函数的设计和完美散列的概念,以实现高效的内存管理和查找操作。
第十三章 随机算法1
1 introduction
1.1 What?(看后续例子更直观)
- 允许算法执行过程中有随机的选择
- 相同的输出可能有不同的输出
1.2 Why?
- 一些问题不能被确定性算法有效的解决。
- 更快 更少的内存
- 更简单 容易理解
- 根据量子力学,世界本质是概率的
用随机算法可以更简单的求解,求一个近似最优解即可。
1.3 蒙特卡洛算法(Monte Carlo)与拉斯维加斯算法(Las Vegas)
- 大致分为两类随机算法
- 蒙特卡洛 可以找到一个近似优的解 运行次数越多 解更优
- 拉斯维加斯 只有0和1 找到或者找不到解。
2 probability review
- 离散概率理论是基于事件以及它们的概率
- 两个事件是独立的iff P ( A ) ∗ P ( B ) = P ( A B ) P(A)*P(B)=P(AB) P(A)∗P(B)=P(AB)
- 定义随机变量 X
- 随机变量的期望
- 期望的 线性性质 E ( X + Y ) = E ( X ) + E ( Y ) E(X+Y)=E(X)+E(Y) E(X+Y)=E(X)+E(Y)
随机算法的重要部分就是求解该算法解的期望以及根据Chernoff Bounds 求bound。
3 example
3.1 最大割 max-cut
3.1.1定义
给定一张图G,将G分为两个sides,极大化两个sides之间的边数。
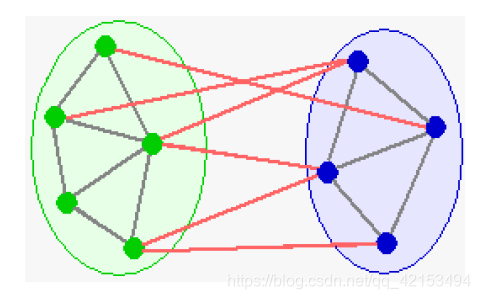
3.1.2 随机算法及分析
非常简单的随机蒙特卡洛 2-近似算法
将每个点随机地放入其中一个side。
- 共有 e e e条边,任意一条边在cut内的概率都是0.5,该算法produce a cut with expected size e 2 \frac{e}{2} 2e, 因此 E ( X ) = e 2 E(X)=\frac{e}{2} E(X)=2e
3.2 随机快排 randomed quicksort
3.2.1快速排序
- 选择一个pivot 元素s
- 将元素分为大于s的部分,以及小于s的部分。
- 递归调用,如下图所示:
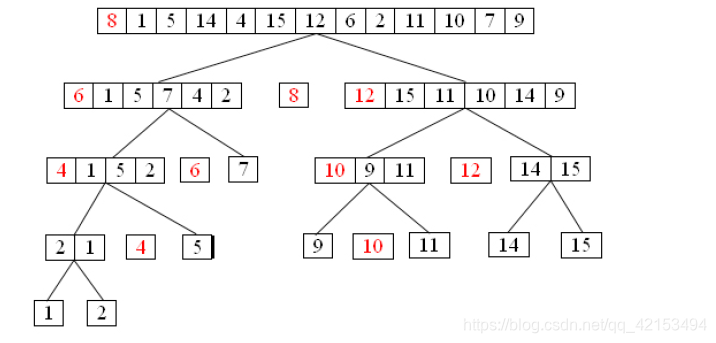
3.2.2 复杂度分析
- T(n)是长度为n的快速排序复杂度
- 最坏的情况每次选择的元素时最大或者最小的, T ( n ) = T ( 1 ) + T ( n − 1 ) + n − 1 T(n)=T(1)+T(n-1)+n-1 T(n)=T(1)+T(n−1)+n−1 ( n − 1 n-1 n−1是比较大小产生的复杂度),==> T ( n ) = O ( n 2 ) T(n)=O(n^2) T(n)=O(n2)
- 较好的情况,每次选择的元素接近中位数 T ( n ) = T ( n 4 ) + T ( 3 ∗ n 4 ) + n − 1 T(n)=T(\frac{n}{4})+T(3*\frac{n}{4})+n-1 T(n)=T(4n)+T(3∗4n)+n−1 ==> T ( n ) = O ( n l o g n ) T(n)=O(nlogn) T(n)=O(nlogn)
- 随机选择pivot元素即为随机排序,选择到任意rank元素的概率为 1 n \frac{1}{n} n1。
- 期望的复杂度为: T ( n ) = 1 n ( T ( 1 ) + T ( n − 1 ) + n − 1 ) + 1 n ( T ( 2 ) + T ( n − 2 ) + n − 1 ) + … T(n)=\frac{1}{n}(T(1)+T(n-1)+n-1)+\frac{1}{n}(T(2)+T(n-2)+n-1)+\dots T(n)=n1(T(1)+T(n−1)+n−1)+n1(T(2)+T(n−2)+n−1)+…==> T ( n ) = O ( a n l o g n + b ) T(n)=O(anlogn+b) T(n)=O(anlogn+b)
3.3 散列法 hash
3.3.1 问题介绍
-
一个巨大的的可能元素的全域 U U U, ∣ U ∣ = n |U|=n ∣U∣=n,数据结构试图记录一个集合 S ⊂ U S\subset U S⊂U, ∣ S ∣ = m |S|=m ∣S∣=m, S S S是非常小的一部分 m ≪ n m\ll n m≪n。
-
设计数据结构(数组 T T T)使得能够快速插入和删除S的元素,并且能够快速判定给定元素是否属于 S S S。
-
全域 U U U中每个元素对应一个位置时严重浪费内存。
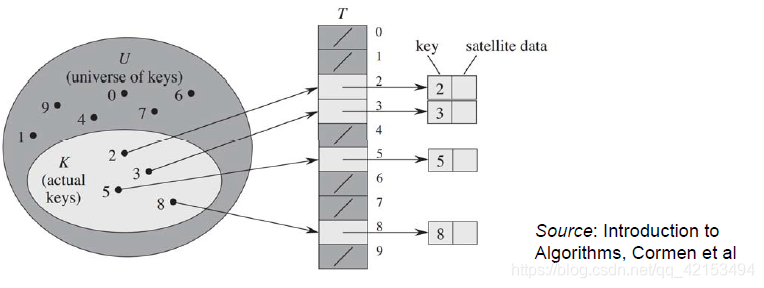
-
设计一个函数h。存储 k k k到 T [ h ( k ) ] T[h(k)] T[h(k)],造成冲突时,形成链表即可。
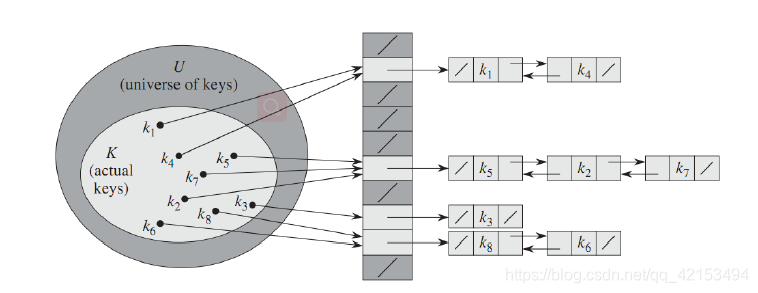
-
最坏的情况下,存在一个链表长度过长。我们采用随机函数类减少这种情况出现。
3.3.2 通用散列函数类 H \mathcal{H} H
- 对任意的 u , v ∈ U u,v\in U u,v∈U,随机选择 h ∈ H h\in \mathcal{H} h∈H 满足 h ( u ) = h ( v ) h(u)=h(v) h(u)=h(v)的概率不超过 1 ∣ T ∣ \frac{1}{|T|} ∣T∣1。
- 简洁的表示每一个 h ∈ H h \in \mathcal{H} h∈H,对于每一个给定 h ∈ H h\in \mathcal{H} h∈H和 u ∈ U u\in U u∈U,能有效地计算 h ( u ) h(u) h(u)。
设计一个通用函数类
- 素数 p p p 作为作为散列表 T T T的大小,把全域 U U U看成 x = ( x 1 , x 2 , … , x r ) x=(x_1,x_2,\dots,x_r) x=(x1,x2,…,xr)的向量集合
- a = ( a 1 , a 2 , … , a r ) ∈ A a=(a_1,a_2,\dots,a_r)\in\mathcal{A} a=(a1,a2,…,ar)∈A , a i ≤ p − 1 a_i\leq p-1 ai≤p−1, H = { h a : a ∈ A } \mathcal{H}=\{h_a:a\in {\mathcal{A}}\} H={ha:a∈A}
- h a ( x ) = ( ∑ i = 1 r a i x i ) m o d ( p ) h_a(x)=(\sum_{i=1}^{r}a_ix_i)mod(p) ha(x)=(∑i=1raixi)mod(p)
3.3.3 完美hash
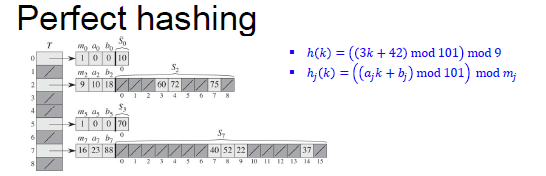
- 使用两层hash函数 通用hash函数。
- 如果有 n j n_j nj个keys都hash到位置 j j j,则 S j S_j Sj的长度为 m j = n j 2 m_j=n_j^2 mj=nj2
- 存储 n n n个元素,hash table 长度为 n 2 n^2 n2, 有 C n 2 C_n^2 Cn2个元素可能冲突,每一对冲突的概率为 1 n 2 \frac{1}{n^2} n21。 E ( ∑ n j 2 ) = E ( n j + 2 C n 2 ) = n + 2 C n 2 ≤ 2 n E(\sum n_j^2)=E(n_j+2C_n^2)=n+2C_n^2\leq 2n E(∑nj2)=E(nj+2Cn2)=n+2Cn2≤2n

















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









