






 本文围绕哈夫曼树展开,先介绍树的路径长度和带权路径长度概念,接着阐述哈夫曼树定义及哈夫曼算法步骤与实现,还说明了其存储结构。最后介绍哈夫曼树在最佳判定算法和哈夫曼编码方面的应用,包括编码和解码过程。
本文围绕哈夫曼树展开,先介绍树的路径长度和带权路径长度概念,接着阐述哈夫曼树定义及哈夫曼算法步骤与实现,还说明了其存储结构。最后介绍哈夫曼树在最佳判定算法和哈夫曼编码方面的应用,包括编码和解码过程。
哈夫曼树
1 树的路径长度和带权路径长度
结点间的路径长度:从树中一个结点到另一个结点之间的分支构成这两个结点的路径,路径上的分支数目(即结点到结点间的线段数)称为这两个结点之间的路径长度。
树的路径长度:是从树根到每个结点的路径长度之和。这种路径长度最短的树是前面定义的完全二叉树。
在许多应用中,常常将树中的结点赋予一个有某种意义的实数,称为该结点的权。
结点的带权路径长度:从该结点到树根之间的路径长度与结点上的权的乘积。
树的带权路径长度:为树中所有叶子结点的带权路径长度之和,通常记作
WPL = W1L1 + W2L2 + W3L3 + … + WiLi + … + Wn*Ln
其中,n为二叉树的叶子结点的个数,Wi为第i个叶子结点的权值,Li为从根节点到第i个叶子结点的路径长度。
例如,如图1所示的三颗二叉树,都有4个叶子结点,a,b,c,d分别带权7,5,2,4,他们的带权路径长度分别为
(1)WPL1 = 7x2 + 5x2 + 2x2 + 4x2 = 36.
(2)WPL2 = 7x3 + 5x3 + 2x3 + 4x2 = 46.
(3)WPL3 = 7x1 + 5x2 + 2x3 + 4x3 = 35.
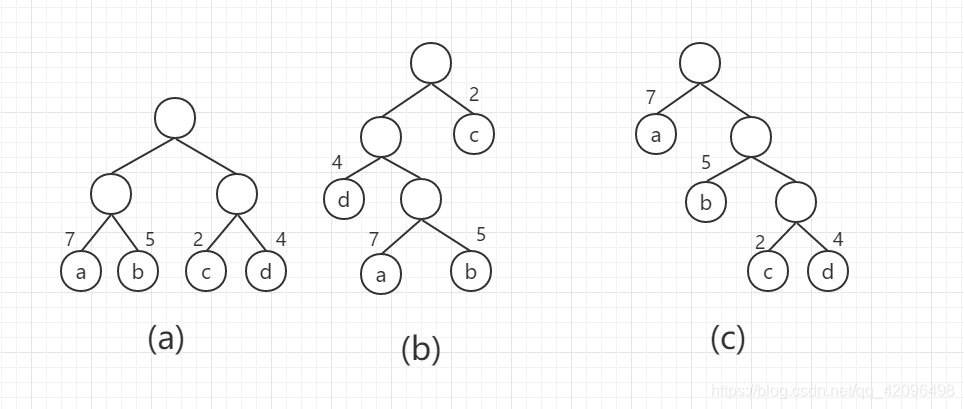
图1 具有不同带权路径的二叉树
哈夫曼树和哈夫曼算法
假设有n个权值为W1,W2,W3,……Wn的结点,试构成一颗有n个叶子结点的二叉树,每个叶子结点带权为Wi,则其中带权树路径长度WPL最小的二叉树称为哈夫曼树(最优二叉树)。
如图1(c)所示的WPL最小。可以验证,它恰为哈夫曼树,即其带权路径长度在所有带权为7,5,2,4的4个叶子结点的二叉树中最小。
怎么根据n个权值构造哈夫曼树呢?哈夫曼在1952年提出来一种算法,很好的解决了这个问题。该算法称为哈夫曼算法,简述如下:
(1)根据给定的n个权值:W1,W2,W3……Wn,构成n颗二叉树的集合F=T1,T2…Tn,其中每个二叉树Ti中只有一个权为Wi的根节点,其左右子树均为空。
(2)在F中选出两个根结点权值最小和次小的树作为左右子树,构成一颗新的二叉树,且置新的二叉树的根节点的权值为其左右结点上根节点权值之和。
(3)从F中删除这两棵树,同时将新得到的二叉树放入到集合F中。
(4)重复(2)和(3)步,直到F中只含有一棵树为止。这棵树便是哈夫曼树。
例如有4个叶子结点a,b,c,d,分别带权为7,5,2,4,其哈夫曼树的构造过程如图2所示。
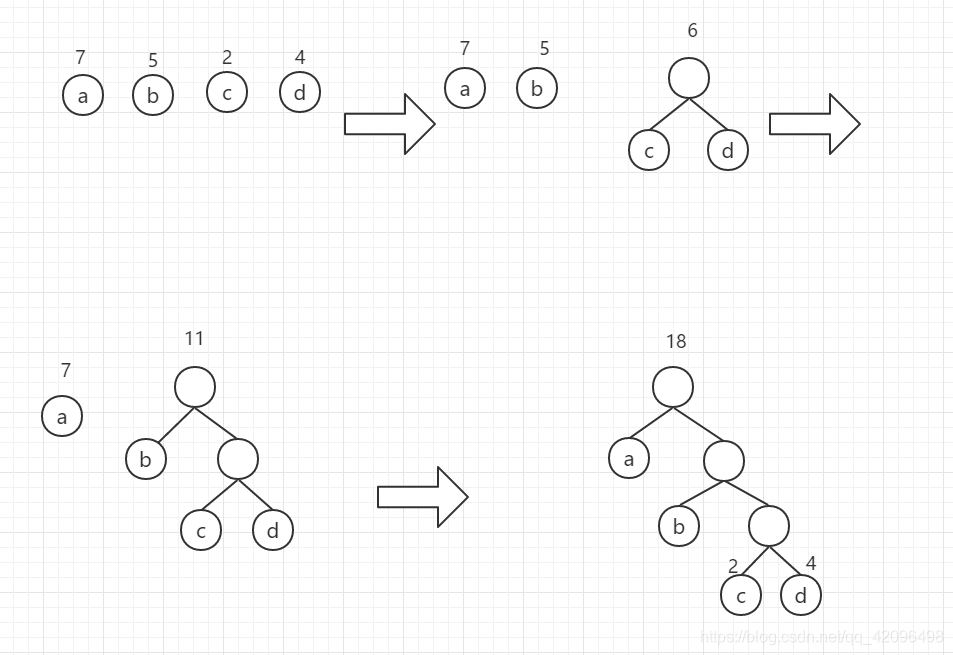
图2 哈夫曼树的构造过程
下面讨论哈夫曼树的存储结构及哈夫曼算法的实现。
有哈夫曼算法可知,初始森林中共有n棵二叉树,每棵树都仅有一个孤立的结点,他们既是根,又是叶子。算法的第二步是将当前森林中的两棵树结点权值最小和次小的二叉树,合并成一棵新的二叉树。每合并一次,就减少两棵二叉树,生成一棵新二叉树。所以,总共需要合并n-1次,最后森林中只有一棵二叉树、由此可知,最终哈夫曼树中共有2n-1个结点,其中n个叶子结点是初始森林中的n个孤立结点。存储结构可写为:
#define n 叶子数
#define m 2*n-1
typedef struct{
int weight;//权值,也即频率
int plink, llink, rlink;//双亲及左右孩子指针,静态指针
}node;
node tree[m];//存储树结点
在上述存储结构上实现的哈夫曼树算法可大致描述为:
(1)初始化:将tree[m]中的每个结点里的三个指针均值为空。
(2)输入:读入n个叶子的权值,分别保存于向量tree的前n个分量中,他们是初始森林中n个孤立根节点的权值。
(3)合并:对森林中的树共进行n-1次合并,所产生的新节点依次放入向量tree的第i个分量中(n<i<=m)。每次合并分为两步:
- 在当前森林tree[1…i-1]的所有结点中,选取权值最小和次小的两个根节点tree[x1]和tree[x2]作为合并对象,这里1<=x1, x2<=i-1.
- 将根为tree[x1]和tree[x2]的两棵树作为左右子树合并成为一颗新的树,新树的根是新节点tree[i]。因此,应将tree[x1]和tree[x2]的双亲plink置为i,将tree[i]的llink和rlink分别置为x1和x2,而新节点tree[i]的权值应置为tree[x1]和tree[x2]的权值之和。注意:合并之和的结点在森林中不再是跟,因为他们有了双亲,所以在下一次合并中不会被选为合并对象。
哈夫曼算法实现如下:
void sethuftree(node tree[m]){
int i, x1, x1;
inithafumantree(tree); // 将tree初始化
inputweight(tree); //输入叶子权值
for(i=n; i<m; i++){
select(i-1, &x1, &x2);
//在tree[0,...,i-1]中选择两个权最小的根节点,其序号分别为x1和x2
tree[x1].plink = i;
tree[x2].plink = i;
tree[i].llink = x1; //权值最小的根节点是新节点的左孩子
tree[i].rlink = x2; //权值次小的根节点是新节点的右孩子
tree[i].weight = tree[x1].weight + tree[x2].weight;
}
}
哈夫曼树的应用
1 最佳判定算法
在解决某些判定问题时,利用哈夫曼树可以得到最佳判定算法。
2 哈夫曼编码
电报是进行快速远距离通信的手段之一。发送电报时需要将传送的文字转换成由二进制的字符组成的字符串。例如,传送的电文为ABACCDA,它只有4种字符,只需要两个字符的串就能进行传送并且正确识别。假设A、B、C、D的编码分别为00,01,10,11,则上述7个字符的电文编码为00010010101100,总长14位。
但是,在传送电文时,我们希望总长度尽可能的段。如果对每个字符设计长度不等的编码,且让电文中出现次数较多的字符采用尽可能短的编码,则传送的总长度便可减短。但是,对某字符集进行不等长编码,必须要求字符集中任意字符的编码都不是其他字符编码的前缀(即不是某个字符编码的前面部分),这种编码也称为前缀编码。显然,等长编码也是前缀编码的一种。
那么我们怎么设计前缀编码?怎么样的前缀编码才会使电文的总长度最短?回到上面所说的,出现次数较多的字符采用尽可能短的编码,也就是我们可以建立一颗哈夫曼树,出现次数多即权值大的靠近根节点,出现次数少即权值小的字符靠近叶子结点。
假设有一颗如图3所示的二叉树,其4个叶子结点分别表示a,b,c,d四种字符,且约定左分支表示字符0,右分支表示字符1,则可将从根节点到叶子结点的路径上由其分支字符组成的字符串作为叶子结点字符的编码。这样得到的必为二进制前缀编码,因为从根节点到叶子结点,没有经过任何一个含有字符的结点,即每个字符的二进制编码都是独一无二的。如图3所得的a,b,c,d,的二进制前缀编码分别为0,10,110,111。
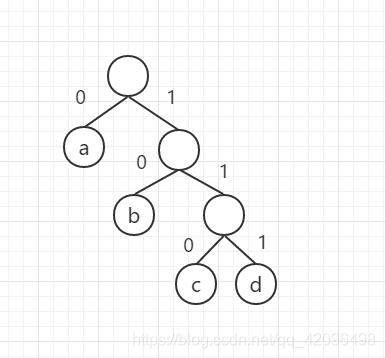
图3 前缀编码示例
要得到使总电文长度最短的二进制前缀编码,需要用到前面所讲的哈夫曼算法。字符集中的每个字符作为一个结点,字符出现的频度作为结点的权值。继而通过算法构造出一个完整的哈夫曼树。
在求出了给定的哈夫曼树后,我们还需要得到每个字符对应的二进制编码,即得到字符集的哈夫曼编码表。具体过程:可以从叶子结点出发,回溯至根节点,也可以从根节点出发,直到寻找到叶子结点。注意:父节点走左结点时生成编码0,走右结点时生成编码1(可以反过来)。
有了字符集的哈夫曼编码表之后,对数据文件的编码过程是,依次读入文件中的字符c,在哈夫曼编码表找到此字符、
对压缩后的数据文件进行解码则必须借助于哈夫曼树tree。其过程是,依次读入文件的二进制编码,从哈夫曼树的根节点出发,若当前读入为0,则走向左孩子,否则走向右孩子,一旦到达某一叶子tree[i]时便译出对应的字符。然后重新从跟出发继续译码,直至文件结束。
参考文献:陈媛,何波,卢玲,涂飞等.算法与数据结构(第二版)[M].北京:清华大学出版社,2011.8

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









