



 文章介绍了如何使用R语言中的DEseq2包进行多组样本的转录组差异分析。通过提供的通用函数DEseq_multi_group,可以简化两两比较的复杂性,特别是处理不同组间重复次数不一致的情况。文章提供了两组和多组样本的比较示例,强调了设置test和control的重要性,并展示了结果的输出形式。
文章介绍了如何使用R语言中的DEseq2包进行多组样本的转录组差异分析。通过提供的通用函数DEseq_multi_group,可以简化两两比较的复杂性,特别是处理不同组间重复次数不一致的情况。文章提供了两组和多组样本的比较示例,强调了设置test和control的重要性,并展示了结果的输出形式。
前面我们已经进行了Bulk转录组上游分析,拿到了count矩阵,那么下一步的重要工作就是进行差异分析。如果你的样本只有两组,那么用DEseg分析很简单,但是如果像我们这次的示例,有很多组,例如是4组,那么要进行差异分析两两比较的时候,跑起来或者数据整理就比较麻烦。尤其是有的时候,有些样本的重复数量并不一致。这里我们提供了一种通用的函数,用来简易、通用的进行差异分析。limma和edger的差异分析函数也可以参照我们的方法修改函数即可使用! 接下来我们看看具体的操作效果。
1、首先是两组样本的比较
#首先我们拿只有两组的样本试一下
setwd("D:/KS项目/公众号文章/DEseq2多组比较函数")
library(tidyverse)
library(DESeq2)
library(combinat)
Two_group <- read.csv("Two_group.csv", header = T,row.names = 1)
head(Two_group)
# Cancer1 Cancer2 Cancer3 Health1 Health2 Health3
# ENSG00000223972.4 1 8 3 6 0 1
# ENSG00000227232.4 313 189 370 121 181 222
# ENSG00000243485.2 1 1 3 1 3 1
# ENSG00000237613.2 0 0 0 1 1 0
# ENSG00000268020.2 0 0 0 0 0 0
# ENSG00000240361.1 0 0 0 0 0 0
#建立一个meta
meta1 <- data.frame(Cancer=c("Cancer1" ,"Cancer2" ,"Cancer3"),
Health=c("Health1", "Health2", "Health3"))
#假设我们不指定test和control
DEGs1 <- DEseq_multi_group(exprSet = Two_group,
meta = meta1,
repNum1 = 3,repNum2 = 3)#这里的repNum1是根据你的重复数设置的
#就会有报错提示,让你设置
# Error in DEseq_multi_group(exprSet = Two_group, meta = meta1, repNum1 = 3, :
# Please set comparise group (test & control)
DEGs1 <- DEseq_multi_group(exprSet = Two_group,
meta = meta1,
repNum1 = 3,repNum2 = 3,
test = 'Cancer', control = 'Health')
head(DEGs1)#运行成功
# baseMean log2FoldChange lfcSE stat pvalue padj
# ENSG00000223972.4 2.9415064 0.5406988 1.5442953 0.3501266 0.7262437 NA
# ENSG00000227232.4 229.1254453 0.4965302 0.4720161 1.0519347 0.2928295 0.9999158
# ENSG00000243485.2 1.7642563 -0.3448057 1.6746224 -0.2059006 0.8368686 NA
# ENSG00000237613.2 0.3998535 -2.2342808 3.9409585 -0.5669384 0.5707560 NA
# ENSG00000268020.2 0.0000000 NA NA NA NA NA
# ENSG00000240361.1 0.0000000 NA NA NA NA NA
没什么说的,很简单,只不过我们的函数解决了两人问题,第一样本数量不一致的情况。第二就是到底谁比谁,有时候很纠结,这只只要设置test和control之后,就明确了是test vscontrol。
2、多组样本的差异分析
#多个样本的比较,还是先设置meta
multi_group <- read.csv("count_gene.csv", header = T, row.names = 1)
head(multi_group)#而且每个组的样本重复不一样
# Fbrain1 Fbrain2 Fbrain3 Fbrain4 Fhom1 Fhom2 Fhom3 Mbrain1 Mbrain2...
# ENSG00000223972.4 0 1 3 0 1 2 0 0 0...
# ENSG00000227232.4 417 184 354 25 413 402 41 423 270...
# ENSG00000243485.2 2 0 3 3 1 1 1 3 0...
# ENSG00000237613.2 0 1 0 0 2 4 0 1 0...
# ENSG00000268020.2 0 0 0 0 0 0 0 0 0...
# ENSG00000240361.1 0 0 0 0 0 0 0 0 0...
#因为不一样长,组多了设置很麻烦,直接在excel种整理读入
meta2 <- read.csv('meta2.csv', header = T, row.names = 1)
head(meta2)
# Fbrain Fhom Mbrain Mhom
# 1 Fbrain1 Fhom1 Mbrain1 Mhom1
# 2 Fbrain2 Fhom2 Mbrain2 Mhom2
# 3 Fbrain3 Fhom3 Mbrain3 Mhom3
# 4 Fbrain4 Mbrain4 Mhom4
# 5 Mbrain5
#差异分析,结果储存在一个list种,是两两比较
DEG2 <- DEseq_multi_group(exprSet = multi_group,meta = meta2)
#从list的元素的名称就可以看出是 谁 vs 谁,然后导出结果即可
saveRDS(DEG2, file = "DEGs.rds")
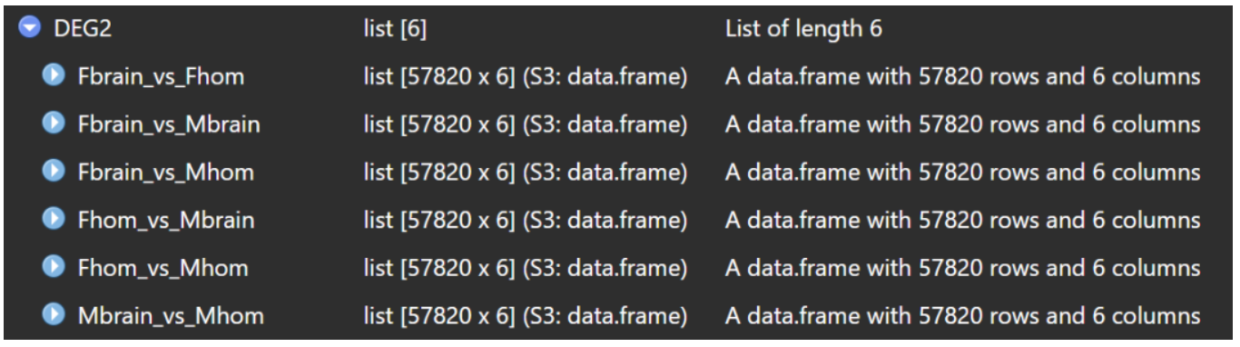
多组比较的分析代码更加简单了,只需要提供count矩阵和meta即可!
更所精彩内容请至我的公众号KS科研分享与服务

















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









