







 该博客介绍了ACmix模块的设计,它结合了自注意力机制和卷积操作。首先,通过3个1x1卷积生成特征图,并将其按深度方向分为多个头。接着,使用自注意力计算注意力权重,同时应用卷积操作。最后,通过学习的权重融合两个分支的输出。在ResNet基础上构建的ACmix_ResNet模型展示了这种融合方法的应用。
该博客介绍了ACmix模块的设计,它结合了自注意力机制和卷积操作。首先,通过3个1x1卷积生成特征图,并将其按深度方向分为多个头。接着,使用自注意力计算注意力权重,同时应用卷积操作。最后,通过学习的权重融合两个分支的输出。在ResNet基础上构建的ACmix_ResNet模型展示了这种融合方法的应用。
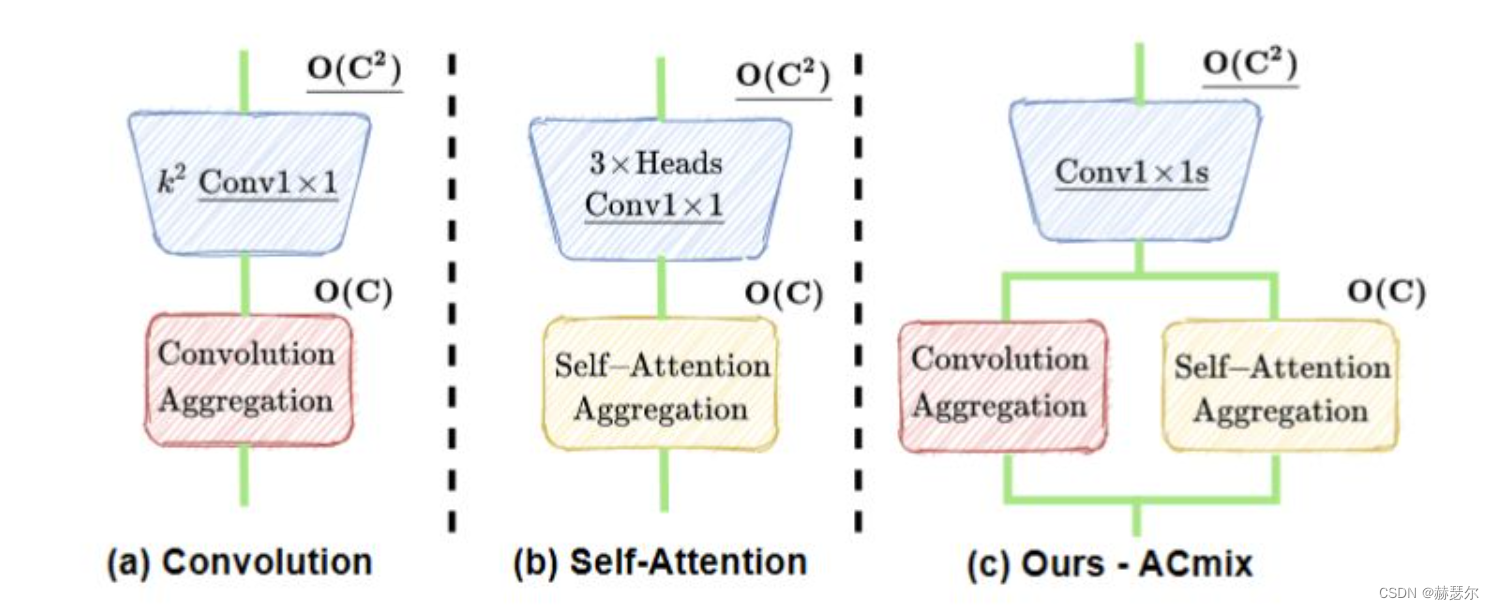
On the Integration of Self-Attention and Convolution
代码
很棒的解读
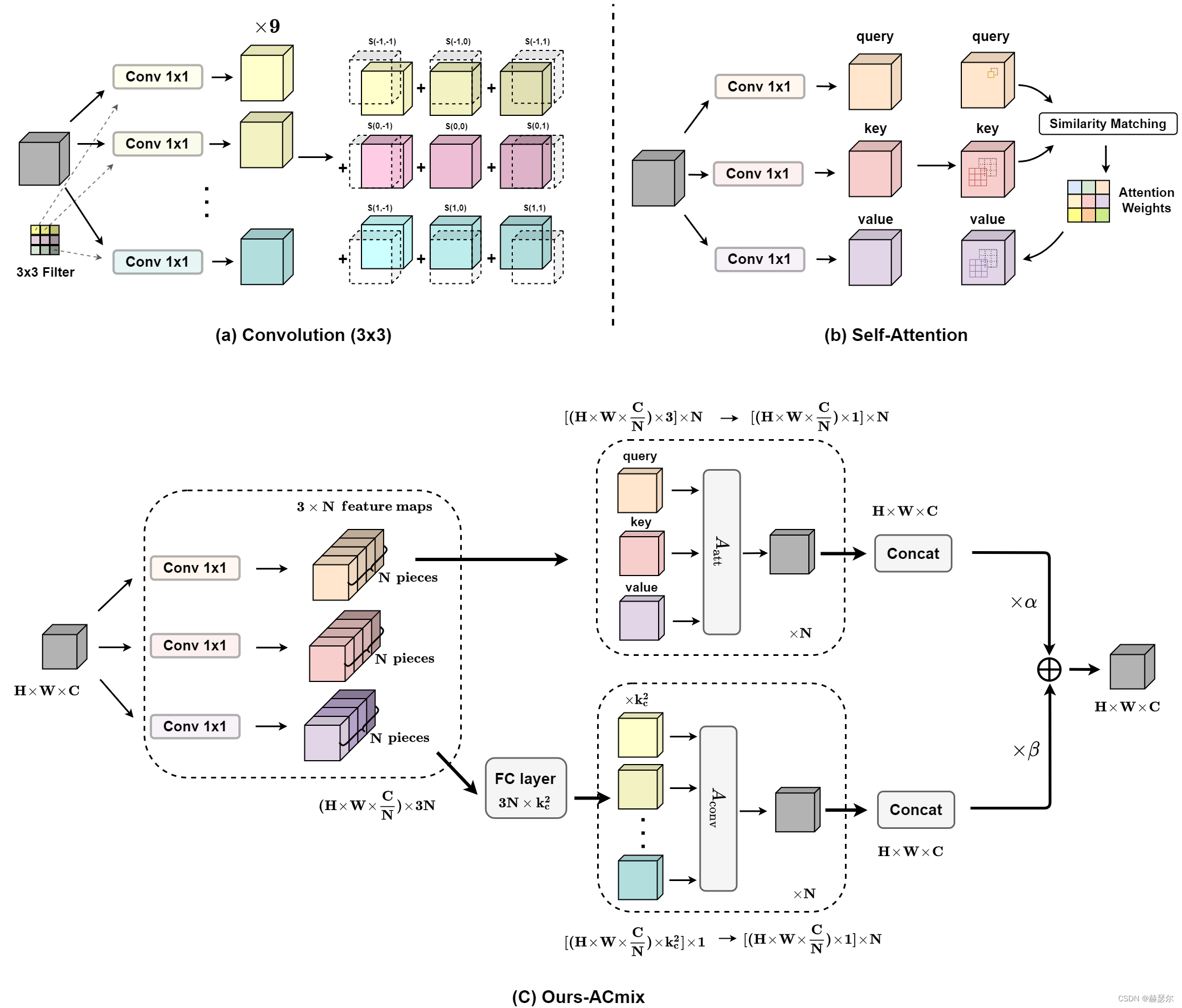
ATT分支: 通过3个1x1的卷积,生成3个feature map(主要是针对self attention的q、k和v),并将3个feature map分别在深度方向上分为N组(针对self attention的N 个 heads)。
卷积分支: 卷积,先通过通道层的全连接对通道扩张,后面处理和卷积第二步的处理相同,先对其偏移后,再去聚合成对应的维度。自注意力部分,按照上面的描述进行计算就可以。最后,将两个分支进行融合![[公式]](https://i-blog.csdnimg.cn/blog_migrate/8748681cc9701e06aa2239706f18e9bf.png) ,系数
,系数 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/5c6c51587e36d84a5632dc4b7cb37764.png) 和
和 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/611359f37d44ad707a5bf21a74e27df6.png) 为可以学习的参数。
为可以学习的参数。
acmix block
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2461
2461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









