







 本文档详述了实验室GPU服务器集群的使用方法,包括普通用户如何申请账号、连接互联网、管理文件、提交作业,以及管理员如何创建用户。介绍了镜像上传、封装,以及使用Jupyter和PyCharm连接服务的步骤。
本文档详述了实验室GPU服务器集群的使用方法,包括普通用户如何申请账号、连接互联网、管理文件、提交作业,以及管理员如何创建用户。介绍了镜像上传、封装,以及使用Jupyter和PyCharm连接服务的步骤。
文章主要介绍实验室GPU集群服务器的使用方法,具体可以参考官方手册SitonHoly Cluster Manager Platform(SCM)用户手册。如有雷同,请联系作者删除。
此教程仅适用于scm2.0以下版本,有可能系统已经进行了升级(2020年7月以后),针对新版本,请读者自行探索。
目录
目录
普通用户:
一 向管理员申请账号
包括网页端的账号、harbor账号、系统层面用于制作镜像的ssh远程账号。
二 服务器连接互联网
最近找到一个docker的无头浏览器镜像,操作很简单,在自己电脑的浏览器上打开 服务器ip:端口号(比如 219.216.99.4:6901),即可进入一个界面(密码 vncpassword),打开这个界面内置的浏览器Chrome,按正常上网的方式登录校园网的网关就行了。如果不会请咨询管理员。
一个人登录后服务器所有用户都可上网,请注意流量消耗。
三 文件管理
参考思腾合力 文件管理 文档。
登录服务器
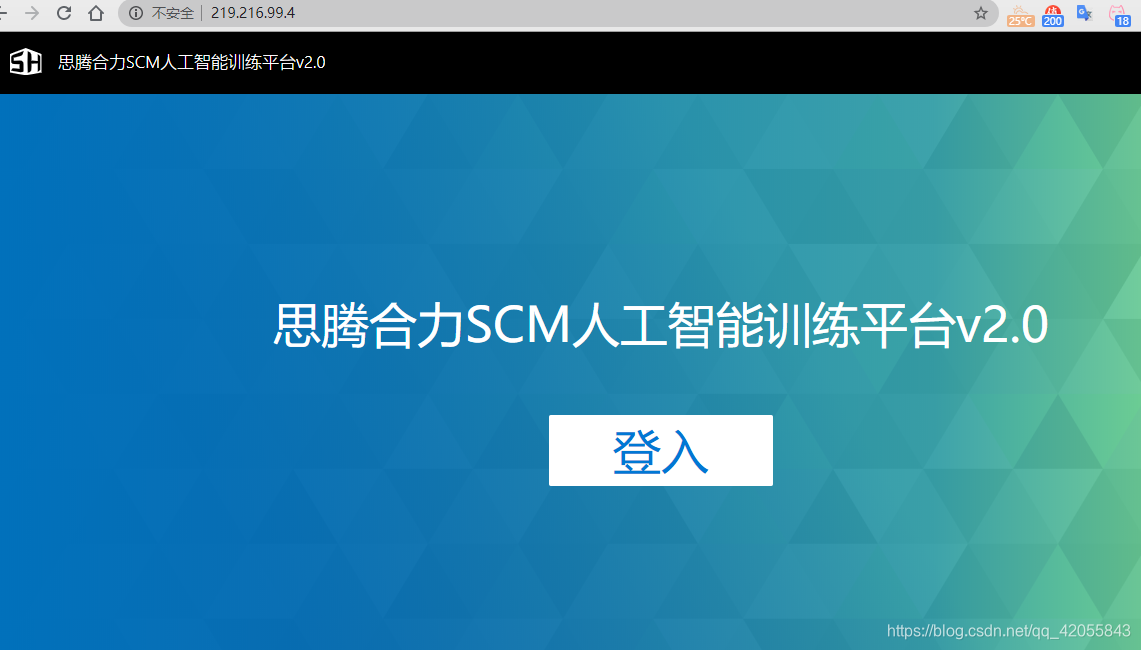
1 档案上传
文件管理里面,新建一个文件夹,点击右上角的 “档案上传”,选择需要上传的文件然后点击上传即可。
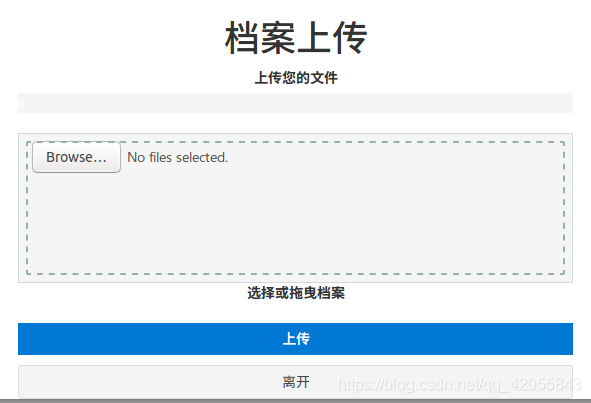
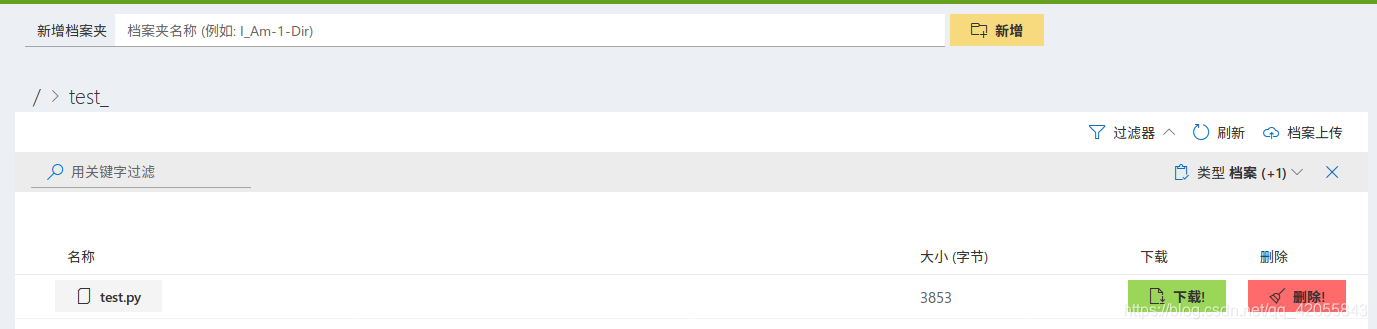
注意:这里只可以上传单个文件,不可以上传文件夹,可以上传压缩包后通过网页端进行解压。
2 文件下载
可以直接使用下载按钮下载单个文件
如果需要下载文件夹,启动一个作业(分配尽可能少的计算资源,1核CPU,0张显卡,2G内存),使作业处于空跑状态(执行命令 sleep infinity), 进入作业的详细界面,“网页ssh”,修改镜像密码 (passwd), -> 使用自己电脑远程登录镜像(ssh -p ssh端口号 root@服务器ip),文件在 /root/data/...,-> 使用scp命令即可远程下载。
四 镜像管理
参考思腾合力 镜像管理文档。
上传镜像:
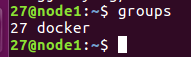
- 命令行远程登录系统,通过groups指令查看是否加入docker组
- 网页端镜像管理里面新建自己的项目
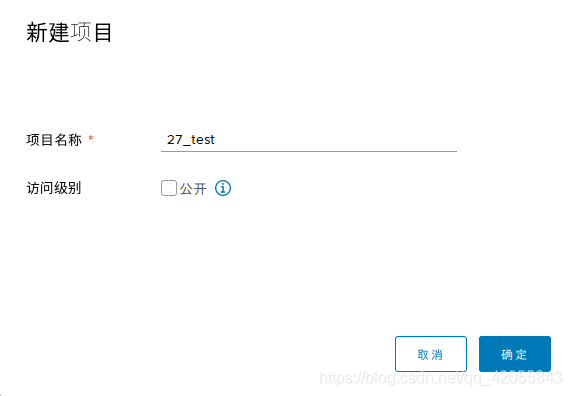
- 命令行登录自己的harbor 镜像仓库,输入对应的harbor用户名和密码。(192.168.137.10:8888是harbor仓库的地址,自己对应着修改。通常为服务器ip8888号端口(ip:8888))
docker login 192.168.137.10:8888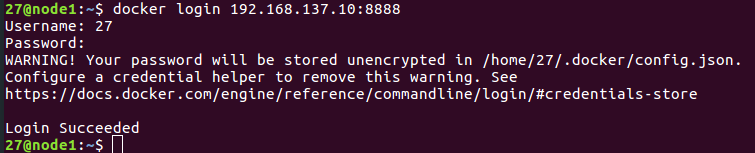
- 可以使用 docker search 搜索需要的镜像
docker search tensorflow-gpu #比如搜索gpu版的tensorflow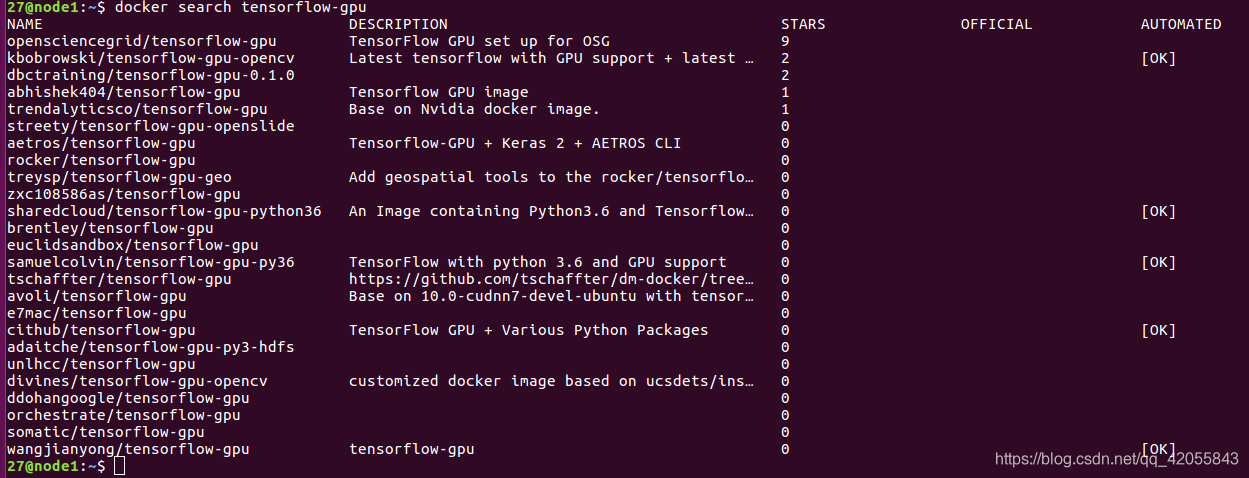
- 使用 docker pull 拉取镜像,如果本地没有,会从docker hub仓库中寻找(如果服务器没有连互联网,就需要通过其他方式拉取)
docker pull walker519/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0 - 使用 docker images 查看本地已经拉取过的镜像
docker images
- 将镜像推送到自己的harbor镜像仓库
在自己的项目里面有一个推送镜像: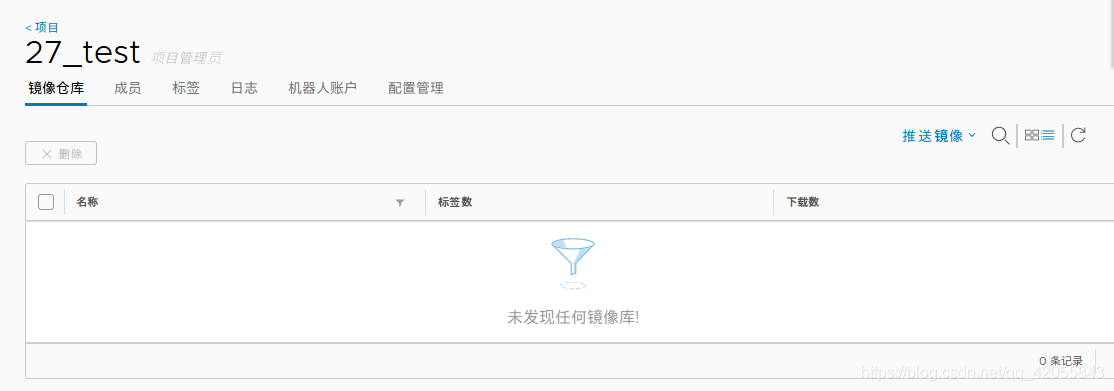
先给镜像打标签后推送到当前项目
docker tag walker519/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0 192.168.137.10:8888/27_test/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0 docker push 192.16
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2201
2201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









