







 本文深入解析BERT模型,从整体概要到预训练的MLM和NSP任务,再到训练过程和微调应用。BERT的双向性体现在MLM任务中,其word embedding能捕捉一词多义。相较于Transformer,BERT的位置编码更为直接。
本文深入解析BERT模型,从整体概要到预训练的MLM和NSP任务,再到训练过程和微调应用。BERT的双向性体现在MLM任务中,其word embedding能捕捉一词多义。相较于Transformer,BERT的位置编码更为直接。
一、BERT整体概要
Bert由两部分组成:
- 预训练(Pre-training):通过两个联合训练任务得到Bert模型
- 微调(Fine-tune):在预训练得到bert模型的基础上进行各种各样的NLP
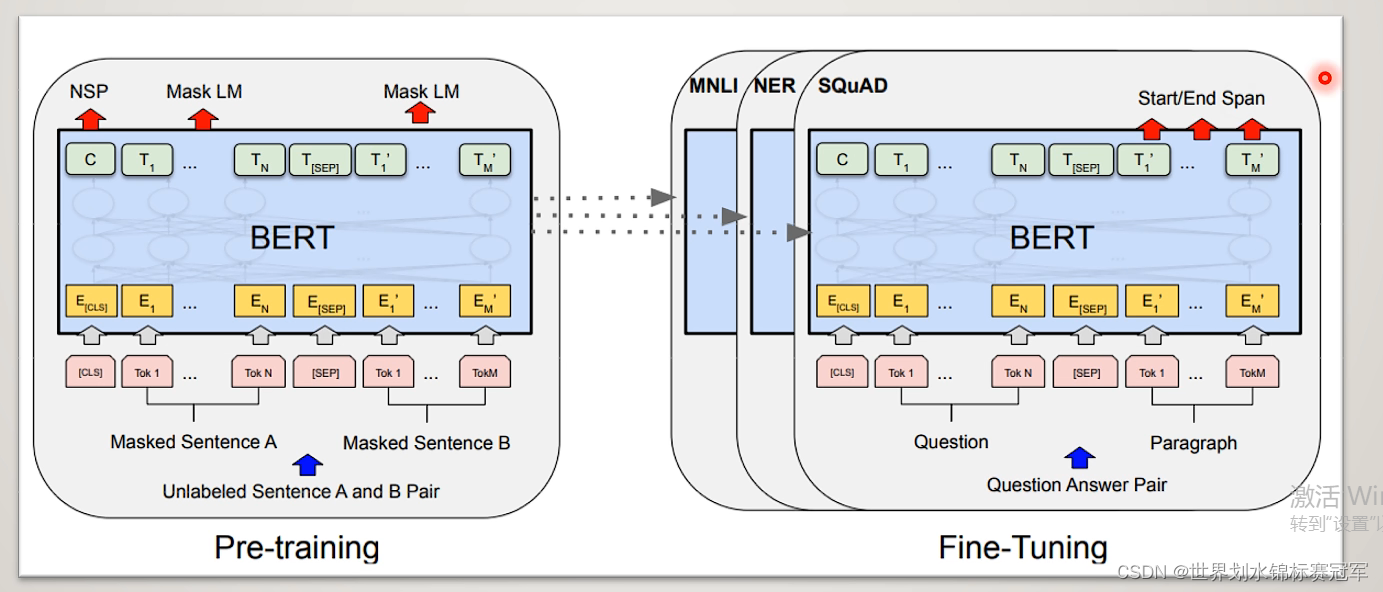
二、预训练
输入经过bert encoder层编码后,进行MLM任务和NSP任务,产生联合训练的损失函数从而迭代更新整个模型中的参数。
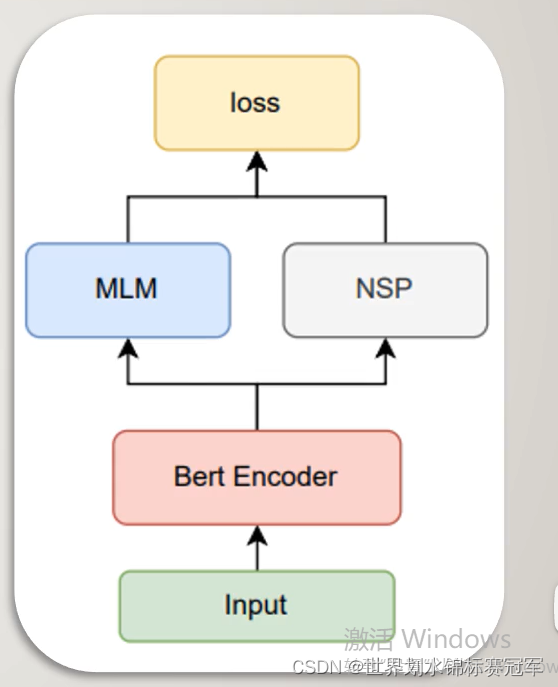
Bert Encoder:采用默认的12层transformer encoder layer对输入进行编码
MLM任务:掩蔽语言模型,遮盖句子中若干词,用周围词去预测遮盖的词
NSP任务:下个句子预测,判断句子B在文章中是否属于句子A的下一句
2.1 BERT Encoder
如何对输入进行编码
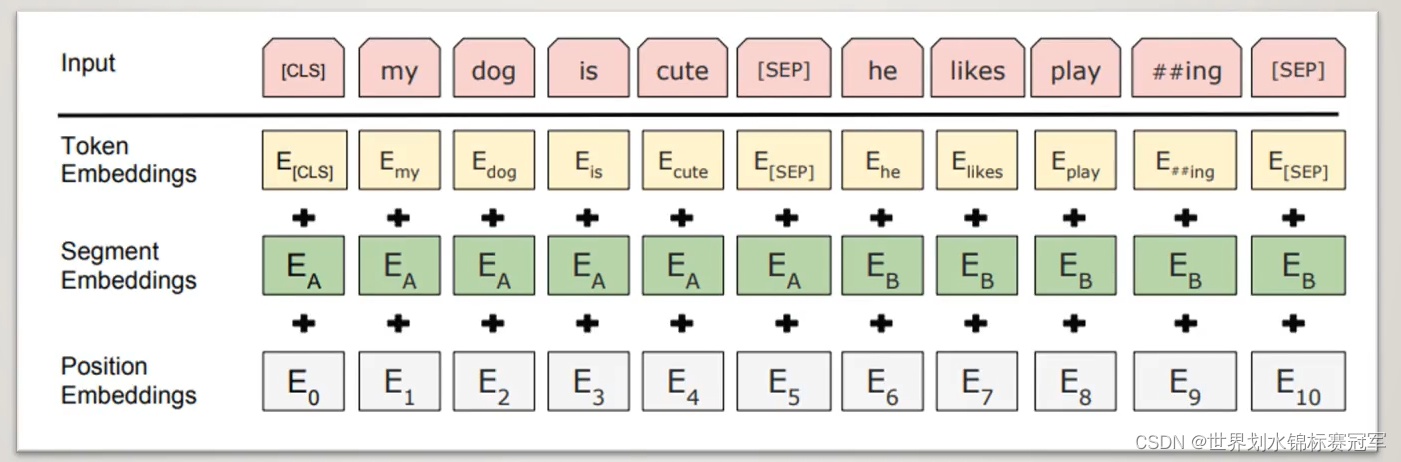
句首+ < CLS > ,句尾和两个句子之间+ < SEP >
句子级别的编码:用来区分每个句子,一个句子的编码是相同的
位置编码:其实就是数字编码123456789
经过编码器编码后输出张量的形状:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4509
4509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









