







 本文详细解析BERT模型的代码,重点介绍了预处理过程,包括tokenization的BasicTokenizer和WordpieceTokenizer,以及run_classifier.py中的关键步骤。讨论了BERT的预训练和微调部分,解释了DataProcessor、InputExample、InputFeatures等类的作用,特别是如何将数据转化为BERT的输入格式,并利用TPUEstimator进行训练、评估和预测。
本文详细解析BERT模型的代码,重点介绍了预处理过程,包括tokenization的BasicTokenizer和WordpieceTokenizer,以及run_classifier.py中的关键步骤。讨论了BERT的预训练和微调部分,解释了DataProcessor、InputExample、InputFeatures等类的作用,特别是如何将数据转化为BERT的输入格式,并利用TPUEstimator进行训练、评估和预测。
一、bert的原理
1、最核心的一点是:MLM损失函数的计算
什么是MLM损失函数?
损失函数就是用来表现预测与实际数据的差距程度-----我根据数据预测出一个函数来预测我之后的变化,而损失函数就是L=(Y-f(x))2,最后计算一个平均损失函数求和的值来表示差距。
MLM损失函数:
这个任务就是将sentence中一些token进行掩盖,模型会输出这些掩盖的token的隐藏状态,将这些隐藏状态输入softmax可以得到候选单词的概率分布,这样根据ground truth就可以计算cross entropy了
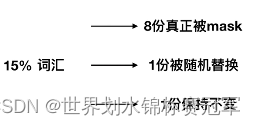
计算mlm损失的时候使用的是那部分数据
2、使用TRM的编码部分
BERT核心目的就是:是把下游具体NLP任务的活逐渐移到预训练产生词向量上
bert的亮点:
1、双向的transformers–同时考虑上下文
2、句子级别的应用
3、适用于不同任务----google已经预预训练好了模型,我们要做的就是根据不同的任务,按照bert的输入要求(后面会看到)输入我们的数据,然后获取输出,在输出层加一层(通常情况下)全连接层就OK啦,整个训练过程就是基于预训练模型的微调
主要分成文本分类,关系抽取等等的句子级别任务和命名实体识别,知识问答等token级别任务
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3980
3980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









