






 本文介绍了AdCo,一种对抗性的对比学习方法,用于自监督学习。AdCo通过将负样本作为网络参数进行端到端训练,提高了负样本质量和对比学习效率。与MoCoV2的静态负样本队列相比,AdCo允许所有负样本实时更新,避免了旧样本的贡献减少问题。实验表明,AdCo在相同训练条件下能达到更高的精度,特别是在ImageNet分类任务上表现出色。
本文介绍了AdCo,一种对抗性的对比学习方法,用于自监督学习。AdCo通过将负样本作为网络参数进行端到端训练,提高了负样本质量和对比学习效率。与MoCoV2的静态负样本队列相比,AdCo允许所有负样本实时更新,避免了旧样本的贡献减少问题。实验表明,AdCo在相同训练条件下能达到更高的精度,特别是在ImageNet分类任务上表现出色。
本文提出了一种对抗对比学习的方式,用对抗的思路 end-to-end 来直接学习负样本,在 ImageNet 和下游任务均达到 SOTA。
1.Introduction
在自监督学习的领域,对比学习在许多下游任务(分类任务、目标检测任务等)中都有很大的优势。在对比学习中,正样本和负样本是对比学习的关键,负样本的数量和质量决定了对比学习的效果。
如何充分地利用负样本去提高在对比学习中的效果和效率是一个值得探索的方向。
作者在 AdCo 中提出了一种新的方法,它不再像 MoCo V2 一样被动地维护一个负样本队列去训练对比模型,而是直接通过主动学习的方法把负样本当作网络参数的一部分去做 end-to-end 的训练。
负样本的作用:
BYOL没有负样本,而在Adco中,负样本作为网络中的一层出现。也可作为backbone 网络进行端到端的训练,其效果和 BYOL 中 predictor 差不多。所以负样本其实也可以作为网络中的一部分发挥重要的作用,在自监督学习中也是非常有用的。
BYOL 中 predictor 的参数量近似于 AdCo 中应用 8192 个负样本的参数量。并且可以发现,AdCo 的训练速度具有一定的提升。是因为在 AdCo 中不需要进行 Global Batch Normalization(BN)。
其次 AdCo 在多个负样本的对比可以提供更多的样本的分布信息,BYOL 只在单个图像的两个变换增强样本得到的特征上做 MSE,从训练的角度来说不如 AdCo 稳定。
Contrastive learning 对比学习。它是通过最小化 contrastive loss 来学习一个无监督的表示。contrastive loss 主要以一种 softmax 的形式给出。在公式中
qi 和 qi' 分别是正样本对它们的表示。而 nk 指的是负样本的表示。
2.方法
最小化 loss 其实就是意味着将同一个样本的两个 augmentation。它们的 representation 使其相互接近,同时使得不同样本之间的 augmentation 相互远离。这种思路虽然简单,但实践证明对比学习在自监督领域已经取得非常好的效果。
现有的构建 Contrastive learning 中负样本的方法主要有两种:
1. 首先是以 MoCo 为代表的方法,对负样本的表示维护一个 FIFO 先进先出的队列。
这种方法的好处是它能够利用过往的 minibatch 的信息。
但缺点是在每次迭代中,只有一小部分的负样本的表示可以得到更新。
2. 另外一种方法是以 SimCLR 为代表的,它是将当前 minibatch 中的其他样本作为负样本。
这种方法的好处是它能够直接应用当前 batch 的 feature 作为负样本,就不会像上面方法一样,负样本中会有很大一部分是很古老的 representation,不会发挥很大的作用。
但这样的方法也是有缺点的,它需要维护一个非常大的 minibatch 的 size 使得能构建足够数量的负样本表示。同时也丢弃了过往 minibatch 中丰富的信息。
作者提出了 AdCo 对抗对比学习,引出了这篇 paper。作者的目标是学到的负样本能够紧密地跟踪网络中正样本表示的变化,同时又能保留历史 minibatch 中存在的丰富的信息,进一步提高负样本的质量从而促进对比学习。
The Proposed Algorithm
作者的思路是通过一种对抗的方式,将整个负样本作为网络的一部分进行一个端到端的训练。
这样“所有”负样本的表示都可以作为一个“整体”,实时地进行更新。
1. 相比于 memory bank 去存储过往图片 embedding 的方式,我们完全可以把负样本作为可学习的权重来训练,这里的好处是我们的所有负样本可以在每次迭代中同步更新权重。相反,MoCo V2 每次只能更新当前负样本队列里的很小的一部分,这导致了最早进入 memory bank 的负样本对于对比学习的贡献相对较小。
2. 当然,更新负样本就不能去最小化对应的 contrastive loss,而要最大化它,使得得到的负样本更加地困难,而对训练 representation network 更有价值,这就得到了一个对抗性的对比学习,对抗的双方是负样本和特征网络。
3. 通过对 update 负样本的梯度进行分析,我们发现这种方法具有非常明显的物理意义。负样本每次更新的方向都是指向当前正样本的一个以某个负样本所归属的正样本的后验概率为权重,对正样本做加权平均得到的梯度方向。
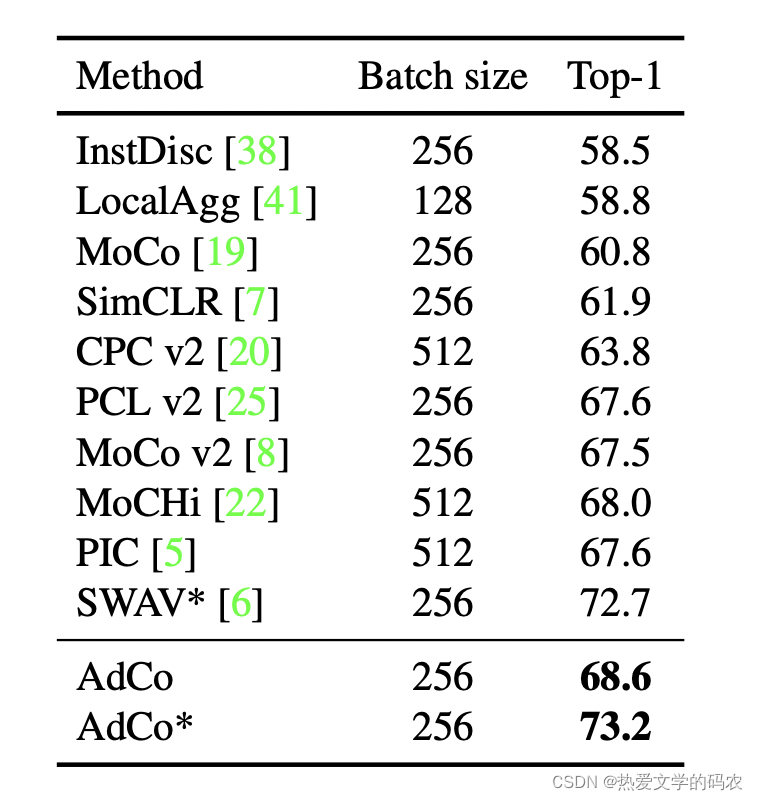
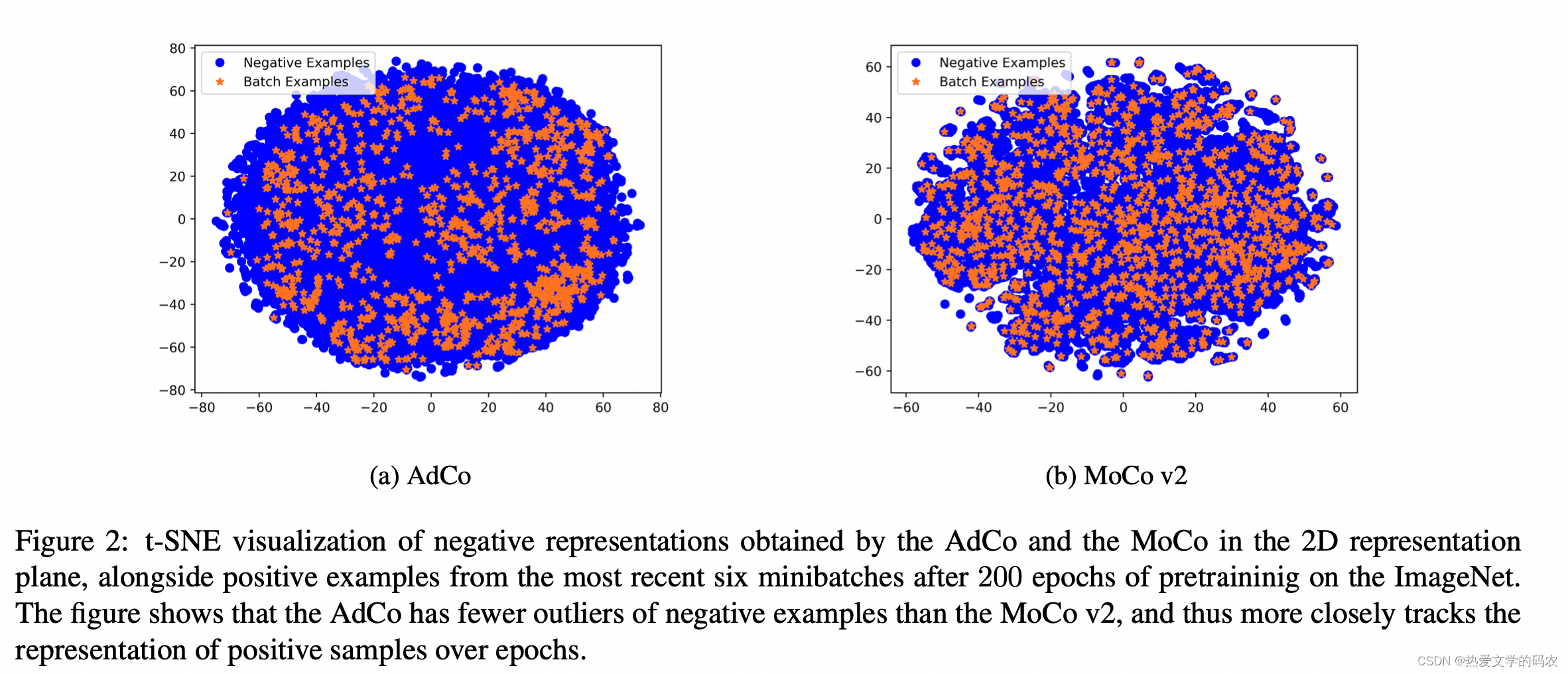
实验发现,在同样的训练时间、minibatch 大小下,AdCo 的精度都会更高。这说明了 AdCo 相比其他的自监督方法有更高的训练效率和精度。这种提升来自对负样本更有效的更新迭代。
3.实验
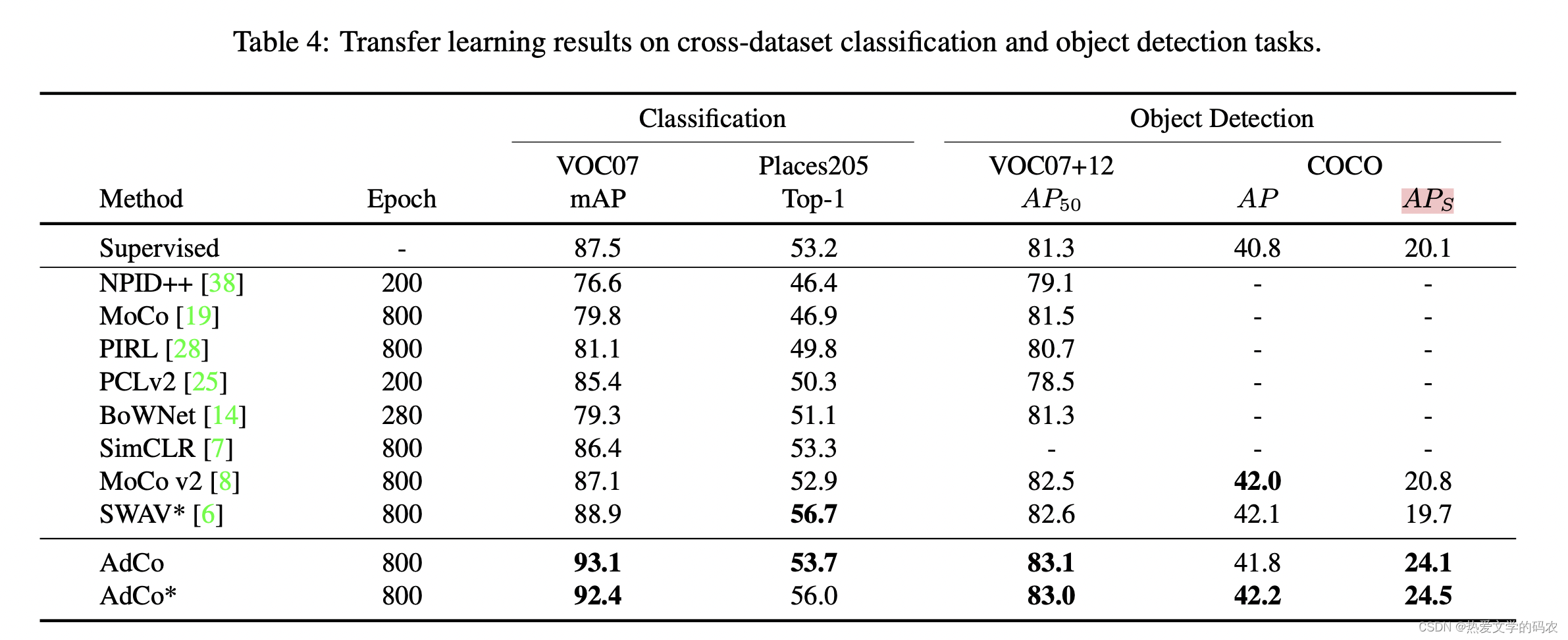
相比于基于 memory bank 的方法,作者的模型在 ImageNet 分类任务上有了显著的提升。
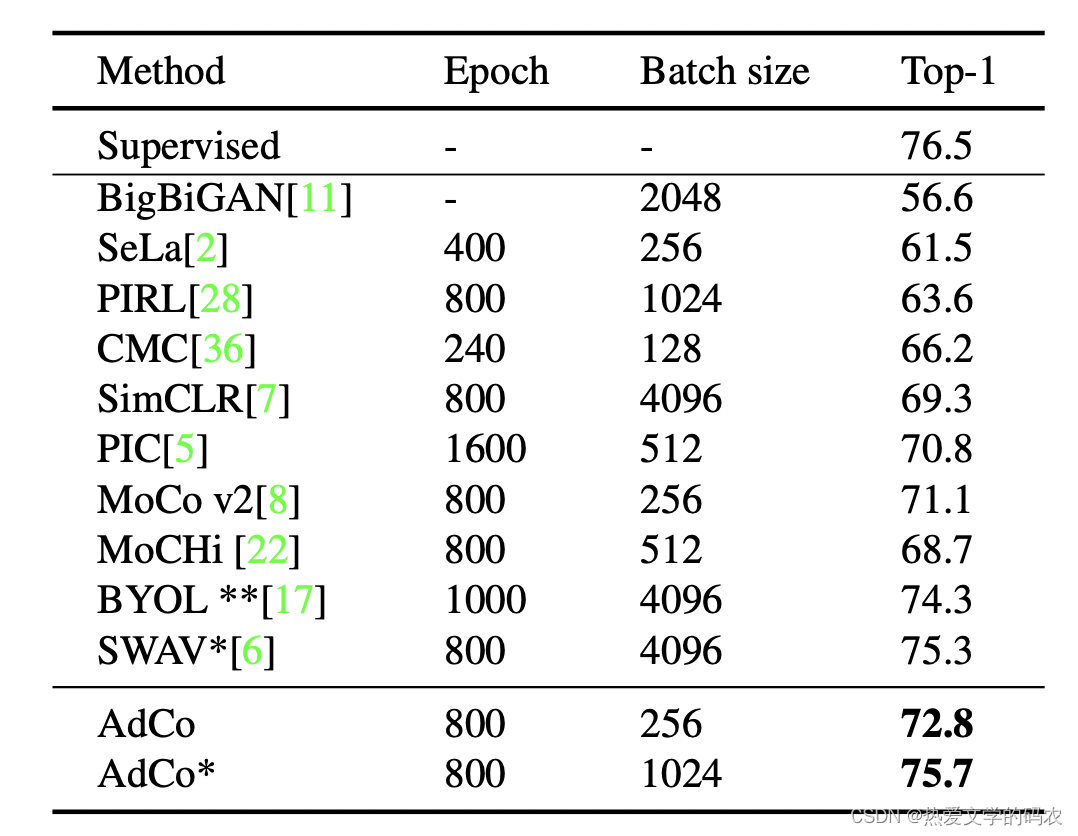
为了公平起见,作者对多尺度增强的方法进行了单独比较(标*)。
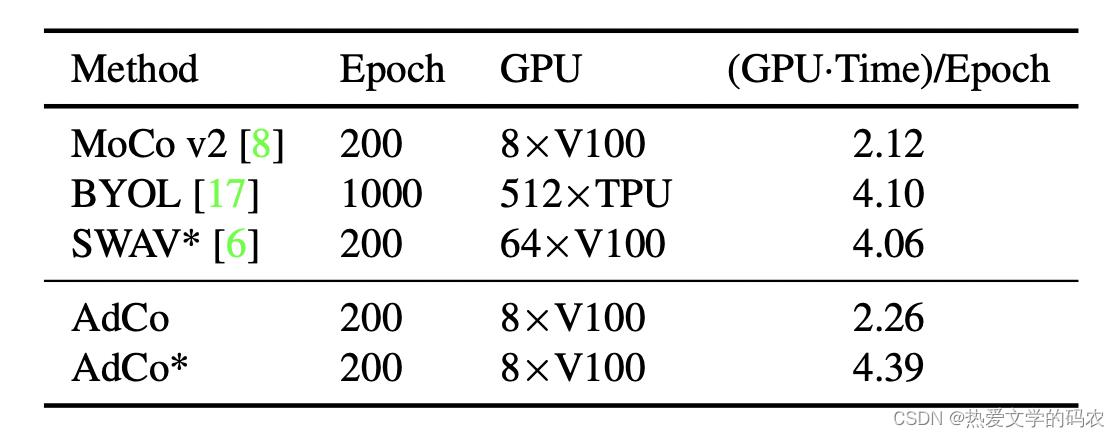
AdCo 由于引入了对负样本的训练,所以在时间上会有一点增加。
AdCo 用较小的 Epoch 以及 Batch size 获得了更高的精度,结果更加接近监督学习。
对BYOL进行了微调(标**)。


















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









