







 该代码利用集成学习和五种重采样策略,包括随机过采样、SMOTER、高斯噪声、WERCS以及它们的组合策略,对酶的最佳催化温度进行预测。通过预处理数据、设置超参数,进行网格搜索,对不同策略进行组合,然后使用蒙特卡洛交叉验证评估预测模型的性能,包括r2分数、MSE、MCC和F1分数等指标。最终,将结果存储在Excel文件中,以供进一步分析。
该代码利用集成学习和五种重采样策略,包括随机过采样、SMOTER、高斯噪声、WERCS以及它们的组合策略,对酶的最佳催化温度进行预测。通过预处理数据、设置超参数,进行网格搜索,对不同策略进行组合,然后使用蒙特卡洛交叉验证评估预测模型的性能,包括r2分数、MSE、MCC和F1分数等指标。最终,将结果存储在Excel文件中,以供进一步分析。
总结
把整个代码看完之后的总结,本代码中使用集成学习和5种重采样策略,使用回归器对数据进行预测。
- 所谓集成学习,就是使用多个回归器进行预测,对预测结果求平均值。
- 5种重采样策略+集成学习结合5种重采样策略= 10种
- 然后对一些超参数组组合进行训练,并将训练结果存储在excel文件中
- 评估指标:r2、mse、mcc、f1分数、每个箱子的mse
- 使用重采样策略提高酶的最佳催化温度(Topt)预测
- 把数据按照温度区间分成稀有域DR(大于72.2℃和小于20℃)和正常域DN(20℃-72.2℃)
引用包:
resreg: 回归的重采样策略
1. 计算氨基酸频率AA和取每个序列的生物体最适生长温度OGT
并对数据进行预处理:标准化,y值为Topt值。
aalist = list('ACDEFGHIKLMNPQRSTVWY')
def getAAC(seq):
aac = np.array([seq.count(x) for x in aalist])/len(seq)
return aac
data = pd.read_excel('data/sequence_ogt_topt.xlsx', index_col=0)
aac = np.array([getAAC(seq) for seq in data['sequence']])
ogt = data['ogt'].values.reshape((data.shape[0],1))
X = np.append(aac, ogt, axis=1)
sc = StandardScaler()
X = sc.fit_transform(X)
y = data['topt'].values2. 设置超参数与重采样策略
- l表示低极值,h表示高极值
- cl_vals、ch_values:表示设置稀有域和正常域的分隔温度(如上文中的72.2℃和20℃)。
通过网格搜索确定的超参数空间。
cl的值对应Topt的第10和20个百分位。最右侧的稀有域由None表示
ch的值对应Topt值的第90和80个百分位
- ks:插值选择的最近邻
- overs:WERCS方法中过采样的数量比例
- unders:WERCS方法中欠采样的数量比例
- sample_methods:采样的方法,对原始数据集重新采样后稀有域和正常域的个数重新分配
- size_methods:REBAGG算法的两种模式平衡模式和变化模式
balance:从稀有域和正常域中随机抽取相等数量的样本S/2 .S为样本总数
variation:按照比例抽取样本,其中比例从集合中选取(1/3、2/5、1/2、3/5、2/3)
cl_vals = [25.0, 30.0, None]
ch_vals = [72.2, 60.0]
ks = [5, 10, 15]
deltas = [0.1, 0.5, 1.0]
overs = [0.5, 0.75]
unders = [0.5, 0.75]
sizes = [300, 600]
sample_methods = ['balance', 'extreme', 'average']
size_methods = ['balance', 'variation']
all_params = {}3. 超参数组合(网格搜索)
- 网格搜索:一种调参手段;穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。(为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search)
- RO:随机过采样

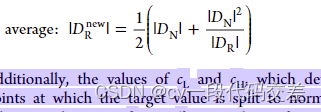
- SMOTER:用于回归的合成少数过采样技术:在DR中随机插值合成数据

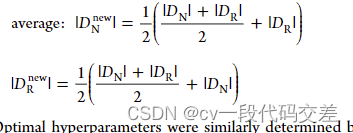
- GN:通过添加高斯噪声合成数据(采样方式与SMOTER相同)
- WERCS:基于加权相关性的组合策略通过相关值作为权重进行过采样和欠采样(复制和删除数据(没有正常域和稀有域)
计算每个值用于过采样和欠采样的概率进行采样。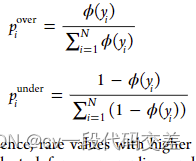
- WERCS-GN:向WERCS策略中选择的过采样值添加高斯噪声,也就是过采样使用合成数据。
- REBAGG-xx:各种采样策略与REBAGG算法相结合
product(*args):
接收若干个位置参数,转换成元组tuple形式
即几组参数随机组合
all_params['RO'] = list(itertools.product(cl_vals, ch_vals, sample_methods))
all_params['SMOTER'] = list(itertools.product(cl_vals, ch_vals, sample_methods, ks))
all_params['GN'] = list(itertools.product(cl_vals, ch_vals, sample_methods, deltas))
all_params['WERCS'] = list(itertools.product(cl_vals, ch_vals, overs, unders))
all_params['WERCS-GN'] = list(itertools.product(cl_vals, ch_vals, overs, unders, deltas))
all_params['REBAGG-RO'] = list(itertools.product(cl_vals, ch_vals, size_methods,
sizes))
all_params['REBAGG-SMOTER'] = list(itertools.product(cl_vals, ch_vals, size_methods,
sizes, ks))
all_params['REBAGG-GN'] = list(itertools.product(cl_vals, ch_vals, size_methods,
sizes, deltas))
all_params['REBAGG-WERCS'] = list(itertools.product(cl_vals, ch_vals, sizes, overs,
unders))
all_params['REBAGG-WERCS-GN'] = list(itertools.product(cl_vals, ch_vals, sizes, overs,
unders, deltas))
strategies = list(all_params.keys())4. 将每个策略应用于 Topt 预测并评估性能
bins:按照集合中的温度分成五个箱子
m:REBAGG 集成中的回归器数量
bins = [30, 50, 65, 85] # For splitting target values into bins
m = 100 # Number of regressors in REBAGG ensemble 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









