









 本文深入探讨了反向传播算法的原理与应用,这是一种广泛应用于训练人工神经网络的方法,尤其适用于利用梯度下降策略进行权重更新。文章详细解析了算法背后的数学原理,包括链式法则的应用、Sigmoid函数的特性及其导数的计算,并展示了如何通过误差逆传播来调整网络中的权重和阈值。
本文深入探讨了反向传播算法的原理与应用,这是一种广泛应用于训练人工神经网络的方法,尤其适用于利用梯度下降策略进行权重更新。文章详细解析了算法背后的数学原理,包括链式法则的应用、Sigmoid函数的特性及其导数的计算,并展示了如何通过误差逆传播来调整网络中的权重和阈值。
Back propagation(反向传播)
Backpropagation algorithms are a family of methods used to efficiently train artificial neural networks (ANNs) following a gradient descent approach that exploits the chain rule. The main feature of backpropagation is its iterative, recursive and efficient method for calculating the weights updates to improve in the network until it is able to perform the task for which it is being trained.[1] It is closely related to the Gauss–Newton algorithm.
artificial neural networks
1943年,lMcCuIIochandPitts,1943]将生物神经网络抽象为图所示的简单
模型,这就是一直沿用至今的“M-P神经元模型”,在这个模型中,神经元接
收到来自“个其他神经元传递过来的输入信号,这些输入信号通过带权重的连
接(connection)JE行传递,神经元接收到的总输入值将与神经元的阀值行比
较,然后通过“激活函数”(activationfunction)处理以产生神经元的输出.
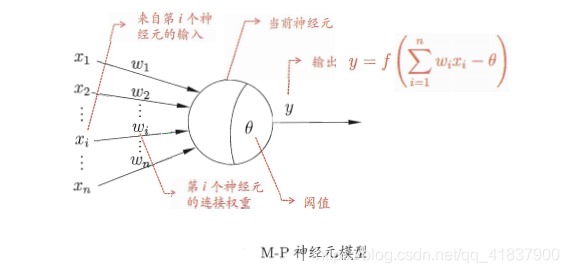
理想中的激活数是图5.2间所示的阶跃函数,它将输入值映射为输出
值“0”或“1”,显然“1”对应于神经元兴奋,“0”对应于神经元抑制.

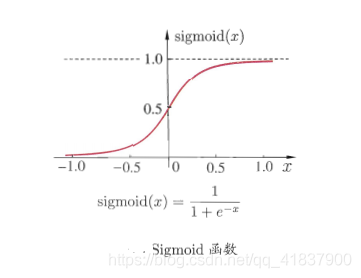
然而,阶跃函数具有不连续、不光滑等不太好的性质,因此实际常用Sigmoid
函数作为激活数.典型的Sigmoid函数如图5.2(b)所示,它把可能在较大
范围内变化的输入值挤压到(0,1)输出值范围内,因此有时也称为“挤压函
function).
感知层与多层神经元
-
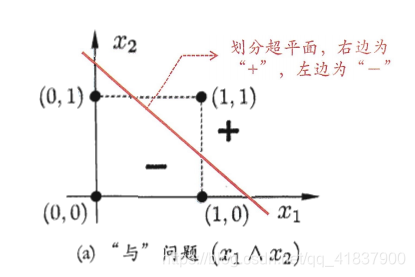
“与” (x1∧x2)\left(x_{1} \wedge x_{2}\right)(x1∧x2):令w1=w2=1w_{1}=w_{2}=1w1=w2=1,θ=2\theta=2θ=2,则
y=f(1⋅x1+1⋅x2−2)y=f\left(1 \cdot x_{1}+1 \cdot x_{2}-2\right)y=f(1⋅x1+1⋅x2−2),仅在x1=x2=1x_{1}=x_{2}=1x1=x2=1时,y=1;
-
“或” (x1∨x2)\left(x_{1} \vee x_{2}\right)(x1∨x2):令w1=w2=1w_{1}=w_{2}=1w1=w2=1,θ=0.5\theta=0.5θ=0.5,则
y=f(1⋅x1+1⋅x2−0.5)y=f\left(1 \cdot x_{1}+1 \cdot x_{2}-0.5\right)y=f(1⋅x1+1⋅x2−0.5),当x1=1x_{1}=1x1=1或x2=1x_{2}=1x2=1,y=1;
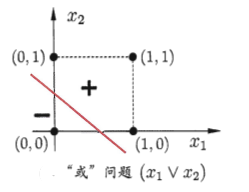
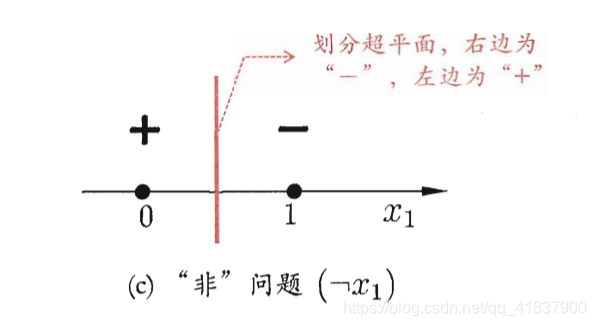
“非” (¬x1)\left(\neg x_{1}\right)(¬x1):令w1=−0.6,w2=0w_{1}=-0.6,w_{2}=0w1=−0.6,w2=0,θ=−0.5\theta=-0.5θ=−0.5,
y=f(−0.6⋅x1+0⋅x2+0.5)y=f\left(-0.6 \cdot x_{1}+0 \cdot x_{2}+0.5\right)y=f(−0.6⋅x1+0⋅x2+0.5),当x1=1x_{1}=1x1=1时,y=0; 当x1=1x_{1}=1x1=1时y=1;
这是对于线性问题,这样解决. 对于非线性问题, 单神经元就无法解决, 比如:
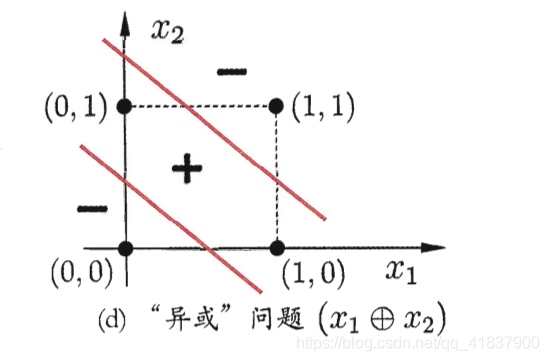
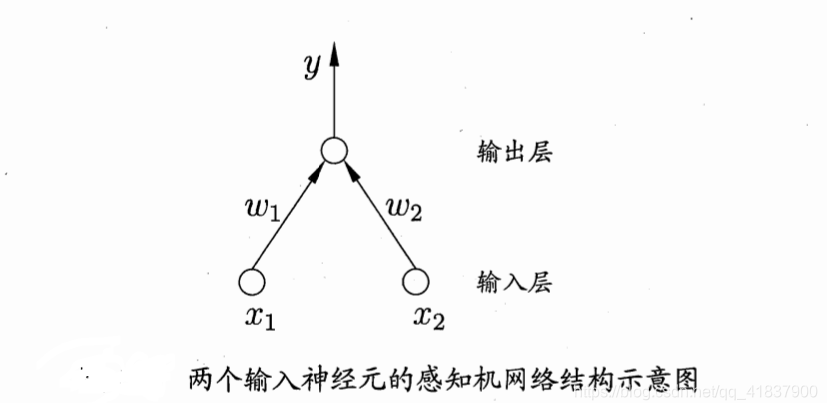
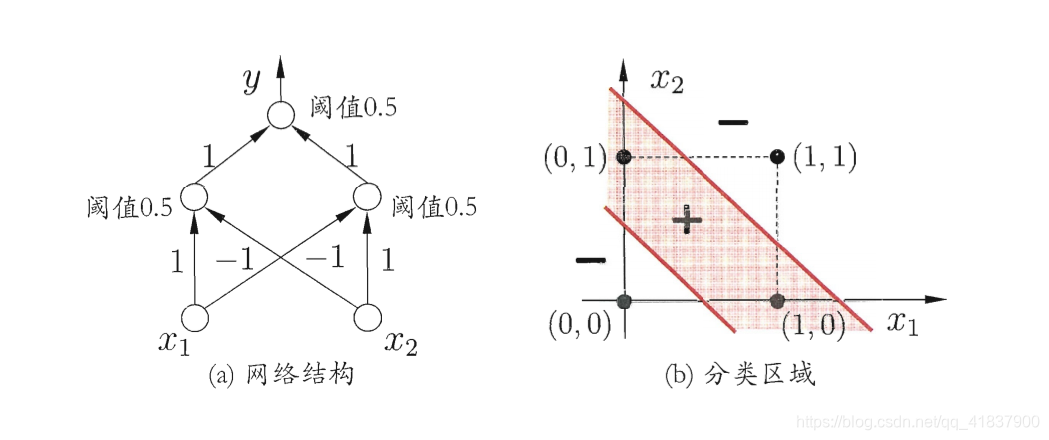
要解决非线性可分问题,需考虑使用多层功能神经元.例如图中这个
简单的两层感知机就能解决异或问题.在图中,输出层与输入层之间的一
层神经元,被称为隐层或隐含层(hiddenlayer),隐含层和输出层神经元都是拥
有激活函数的功能经元.
更一般的,常见的神经网络是形如图5、6所示的层级结构,每层神经元与下
一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接.这样的
神经网络结构通常称为“多层前馈神经网络”(multi-layer feedforward nenral netowrks).
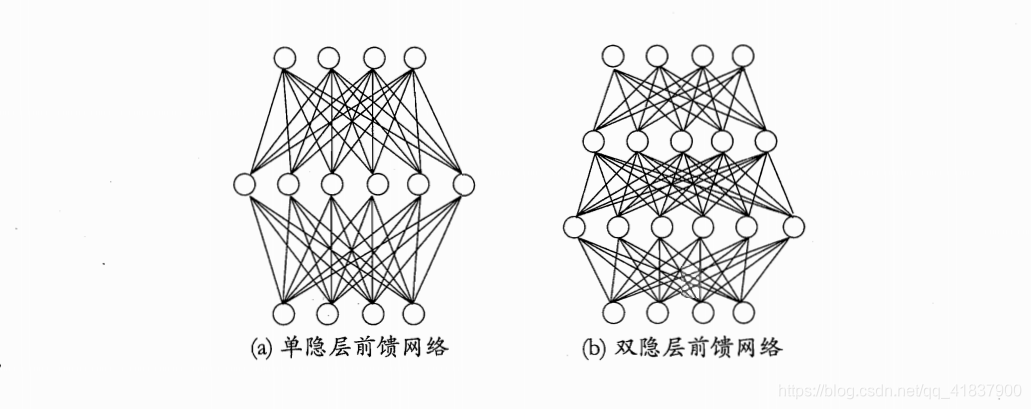
backpropagation
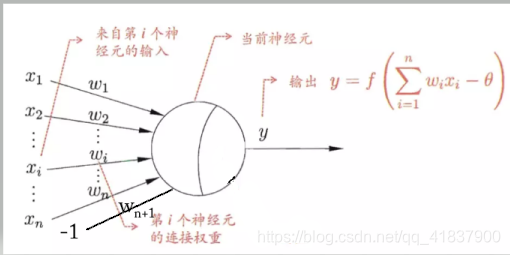
给定训练数据集,权重(i=1,2,… ,n)以及θ\thetaθ阈值可通过学习得到.阈值θ\thetaθ可看作一个固定输入为-1.0的“哑结点”(dummynode)所对应的连接权重wn+1w_{n+1}wn+1,这样,权重和阀值的学习就可统一为权重的学习.感知机学习规则非常简单,对训练样例(x,y), 若当前感知机的输出为则感知机权重将这样调整 :
wi←wi+ΔwiΔwi=η(y−y^)xi
\begin{array}{c}{w_{i} \leftarrow w_{i}+\Delta w_{i}} \\ {\Delta w_{i}=\eta(y-\hat{y}) x_{i}}\end{array}
wi←wi+ΔwiΔwi=η(y−y^)xi
其中η∈(0,1)\eta \in(0,1)η∈(0,1)称为学习率(learningrate).从式(1)可看出,若感知机对训练样例,(x,y)预测正确,即 y^=y\hat{y}=yy^=y, 则感知机不发生变化,否则将根据错误的程度进行权重调整.
哑节点示意图 :
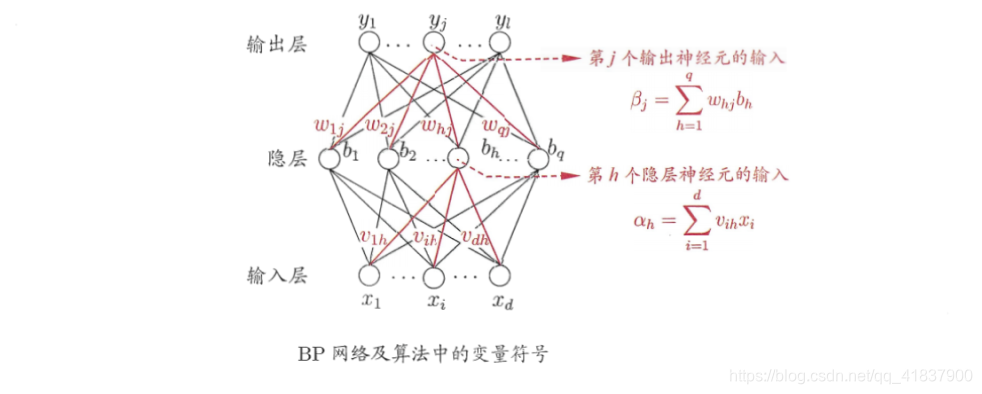
多层网络的学习能力比单层感知机强得多、欲训练多层网络,上面的简单感知机学习规则显然不够了,需要更强大的学习算法.误差逆传播(error BackPropagation,简称BP)算法就是其中最杰出的代表,它是迄今最成功的神经网络学习算法.现实任务中使用神经网络时,大多是在使用BP算法进行训练,值得指出的是,BP算法不仅可用于多层前馈神经网络,还可用于其他类型的神经网络,例如训练递归神经网络[Pineda,1987],
但通常说"BP网络”时,一般是指用BP算法训练的多层前馈神经网络、下面我们来看看BP算法究竟是什么样.给定训练 即输入示例由d个属性描述,输出D={(x1,y1),(x2,y2),…,(xm,ym)},xi∈Rd,yi∈RlD=\left\{\left(\boldsymbol{x}_{1}, \boldsymbol{y}_{1}\right)\right.,\left(\boldsymbol{x}_{2}, \boldsymbol{y}_{2}\right), \ldots,\left(\boldsymbol{x}_{m}, \boldsymbol{y}_{m}\right) \}, \boldsymbol{x}_{i} \in \mathbb{R}^{d}, \boldsymbol{y}_{i} \in \mathbb{R}^{l}D={(x1,y1),(x2,y2),…,(xm,ym)},xi∈Rd,yi∈Rl . 即输入示例由d个属性描述,输出l维实职=值向量 . 为便于讨论,图给出了一个拥有d个输入神经元、l个输出神经元、q个隐层神经元的多层前馈网络结构,其中输出层第j个神经元的阈值用θj\theta_{j}θj表示,隐层第h个神经元的阈值用γh\gamma_{h}γh表示.输入层第i个神经元与隐层第h个神经元之间的连接权为vihv_{i h}vih,记隐层第h个神经元与输出层第j个神经元之间的连接权为whjw_{h}jwhj.记隐层第h个神经元接收到的输入为αh=∑i=1dvihxi\alpha_{h}=\sum_{i=1}^{d} v_{i h} x_{i}αh=∑i=1dvihxi ,输出层第j个神经元接收的输入为βj=∑h=1qwhjbh\beta_{j}=\sum_{h=1}^{q} w_{h j} b_{h}βj=∑h=1qwhjbh , 其中bnb_{n}bn为隐层第h个神经元的输出 . 假设隐层和输入层神经元都使用Sigmoid函数 .
对于训练例 (xk,ykx_{k},y_{k}xk,yk),假定神经网络输入为y^k=(y^1k,y^2k,…,y^lk)\hat{\boldsymbol{y}}_{k}=\left(\hat{y}_{1}^{k}, \hat{y}_{2}^{k}, \ldots, \hat{y}_{l}^{k}\right)y^k=(y^1k,y^2k,…,y^lk)即 :
y^jk=f(βj−θj)(3)\hat{y}_{j}^{k}=f\left(\beta_{j}-\theta_{j}\right) \qquad \qquad \qquad (3)y^jk=f(βj−θj)(3)
则神经网络在(xk,ykx_{k},y_{k}xk,yk)上的均方误差为:
Ek=12∑j=1l(y^jk−yjk)2(4)E_{k}=\frac{1}{2} \sum_{j=1}^{l}\left(\hat{y}_{j}^{k}-y_{j}^{k}\right)^{2} \qquad \qquad \qquad (4)Ek=21j=1∑l(y^jk−yjk)2(4)
图中的网络共有(d+l+1)q+l个参数需要确定 : 输入层到隐层的dXq个权值, q个隐层神经元阀值,l个输出层神经元阀值BP是一个迭代的学习算法 . 在迭代的每一轮中采用广义的感知机学习规则对参数进行更新估计 . 任意参数v的更新估计式为:
v←v+Δv(5)v \leftarrow v+\Delta v \qquad \qquad \qquad (5)v←v+Δv(5)
下面我们以图中隐层到输出层的连接权whjw_{h j}whj为例推导 .
BP算法基于梯度下降(gradicent descent)策略,以目标的负梯度方向对参数进行调整, 对公式(4)的误差EkE_{k}Ek , 给定学习率η\etaη ,由:
Δwhj=−η∂Ek∂whj(6)
\Delta w_{h j}=-\eta \frac{\partial E_{k}}{\partial w_{h j}}\qquad \qquad \qquad (6)
Δwhj=−η∂whj∂Ek(6)
注意到whjw_{hj}whj先影响到第j个输出层神经元的输出值βj\beta_{j}βj, 再影响到其输出值y^jk\hat{y}_{j}^{k}y^jk然后影响到EkE_{k}Ek,有:
∂Ek∂whj=∂Ek∂y^jk⋅∂y^jk∂βj⋅∂βj∂whj(7)\frac{\partial E_{k}}{\partial w_{h j}}=\frac{\partial E_{k}}{\partial \hat{y}_{j}^{k}} \cdot \frac{\partial \hat{y}_{j}^{k}}{\partial \beta_{j}} \cdot \frac{\partial \beta_{j}}{\partial w_{h j}}\qquad \qquad \qquad (7)∂whj∂Ek=∂y^jk∂Ek⋅∂βj∂y^jk⋅∂whj∂βj(7)
根据βj\beta_{j}βj的定义,显然
∂βj∂whj=bh(8)\frac{\partial \beta_{j}}{\partial w_{h j}}=b_{h}\qquad \qquad \qquad (8)∂whj∂βj=bh(8)
Simoid函数有一个很好的性质:
f′(x)=f(x)(1−f(x))(9)f^{\prime}(x)=f(x)(1-f(x))
\qquad \qquad \qquad (9)f′(x)=f(x)(1−f(x))(9)
推导过程Simoid -> s(x)=11+e−xs(x)=\frac{1}{1+e^{-x}}s(x)=1+e−x1
倒置函数-> f(x)=1s(x)=1+e−xf(x)=\frac{1}{s(x)}=1+e^{-x}f(x)=s(x)1=1+e−x
f′(x)=−s′(x)s(x)2(1)f^{\prime}(x)=-\frac{s^{\prime}(x)}{s(x)^{2}}\qquad(1)f′(x)=−s(x)2s′(x)(1)
f′(x)=(1+e−x)ddx=−e−x=1−f(x)=1−1s(x)=s(x)−1s(x)(2)f^{\prime}(x)=\left(1+e^{-x}\right)\frac{d}{d x}=-e^{-x}=1-f(x)=1-\frac{1}{s(x)}=\frac{s(x)-1}{s(x)}\qquad(2)f′(x)=(1+e−x)dxd=−e−x=1−f(x)=1−s(x)1=s(x)s(x)−1(2)
根据(1),(2)消元就可以得到Sigmoid的导数公式
s′(x)=s(x)⋅(1−s(x))s^{\prime}(x)=s(x) \cdot(1-s(x))s′(x)=s(x)⋅(1−s(x))
根据公式(3),(4),有
gj=−∂Ek∂y^jk⋅∂y^jk∂βj=−(y^jk−yjk)f′(βj−θj)=y^jk(1−y^jk)(yjk−y^jk)(10)\begin{aligned} g_{j} &=-\frac{\partial E_{k}}{\partial \hat{y}_{j}^{k}} \cdot \frac{\partial \hat{y}_{j}^{k}}{\partial \beta_{j}} \\ &=-\left(\hat{y}_{j}^{k}-y_{j}^{k}\right) f^{\prime}\left(\beta_{j}-\theta_{j}\right) \\ &=\hat{y}_{j}^{k}\left(1-\hat{y}_{j}^{k}\right)\left(y_{j}^{k}-\hat{y}_{j}^{k}\right) \end{aligned}
\qquad \qquad \qquad (10)gj=−∂y^jk∂Ek⋅∂βj∂y^jk=−(y^jk−yjk)f′(βj−θj)=y^jk(1−y^jk)(yjk−y^jk)(10)
将公式(10)和(8)代入(7) , 再代入(6) , 就得到了BP算法中关于WhjW_{hj}Whj的更新公式
Δwhj=ηgjbh\Delta w_{h j}=\eta g_{j} b_{h}Δwhj=ηgjbh
同理可得:
Δθj=−ηgjΔvih=ηehxiΔγh=−ηeh\begin{aligned} \Delta \theta_{j} &=-\eta g_{j} \\ \Delta v_{i h} &=\eta e_{h} x_{i} \\ \Delta \gamma_{h} &=-\eta e_{h} \end{aligned}ΔθjΔvihΔγh=−ηgj=ηehxi=−ηeh
其中
eh=−∂Ek∂bh⋅∂bh∂αh=−∑j=1l∂Ek∂βj⋅∂βj∂bhf′(αh−γh)=∑j=1lwhjgjf′(αh−γh)=bh(1−bh)∑j=1lwhjgj\begin{aligned} e_{h} &=-\frac{\partial E_{k}}{\partial b_{h}} \cdot \frac{\partial b_{h}}{\partial \alpha_{h}} \\ &=-\sum_{j=1}^{l} \frac{\partial E_{k}}{\partial \beta_{j}} \cdot \frac{\partial \beta_{j}}{\partial b_{h}} f^{\prime}\left(\alpha_{h}-\gamma_{h}\right) \end{aligned}\\=\sum_{j=1}^{l} w_{h j} g_{j} f^{\prime}\left(\alpha_{h}-\gamma_{h}\right) \\ =b_{h}\left(1-b_{h}\right) \sum_{j=1}^{l} w_{h j} g_{j}eh=−∂bh∂Ek⋅∂αh∂bh=−j=1∑l∂βj∂Ek⋅∂bh∂βjf′(αh−γh)=j=1∑lwhjgjf′(αh−γh)=bh(1−bh)j=1∑lwhjgj
学习率η∈(0,1)\eta \in(0,1)η∈(0,1)控制着算法每一轮迭代的更新步长,太大会振荡不收敛 . 太小会收敛过慢 .
指数衰减学习率。这个算法实现达到的效果是:随着迭代次数的增加逐步减小学习率,是模型前期训练速度加快,后期训练模型更加稳定而不会出现极优值两边跳动的情况。

累计误差逆传播:
E=1m∑k=1mEkE=\frac{1}{m} \sum_{k=1}^{m} E_{k}E=m1k=1∑mEk
BP算法的目标是最小化训练集D桑拿的累计误差 .
补充:
由于神经网络强大的表达能力,BP神经网络常常出现过拟合现象.
对此我们可以使用正则化 , 其基本思想是在误差目标中添加一个用于描述网络复杂度的部分,例如连接权与阀值的平方 ,令EkE_{k}Ek表示第k个训练样例的误差 , wiw_{i}wi表示连接权与阀值,则误差目标函数变为
E=λ1m∑k=1mEk+(1−λ)∑iwi2E=\lambda \frac{1}{m} \sum_{k=1}^{m} E_{k}+(1-\lambda) \sum_{i} w_{i}^{2}E=λm1k=1∑mEk+(1−λ)i∑wi2

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









