




 本文深入解析Java中的List、Set和Map集合,包括ArrayList、LinkedList、HashSet、TreeSet、HashMap、HashTable、ConcurrentHashMap、TreeMap和LinkedHashMap的特性与应用场景。详细介绍了各集合的底层实现原理,如数组、链表、哈希表、红黑树等数据结构,以及线程安全性和性能优化策略。
本文深入解析Java中的List、Set和Map集合,包括ArrayList、LinkedList、HashSet、TreeSet、HashMap、HashTable、ConcurrentHashMap、TreeMap和LinkedHashMap的特性与应用场景。详细介绍了各集合的底层实现原理,如数组、链表、哈希表、红黑树等数据结构,以及线程安全性和性能优化策略。
集合List/Set/Map
1.List:有序 可重复的
List的实现类:ArrayList 内部是数组数据结构,线程不安全。替代了Vector。查询的速度快 增删效率低
LinkedList 内部是链表数据结构,线程不安全。增删元素的速度很快。(链表数据结构)
排序:Collections.reverse(); List倒序
Collections.sort();List正序
底层实现:
1):ArrayList
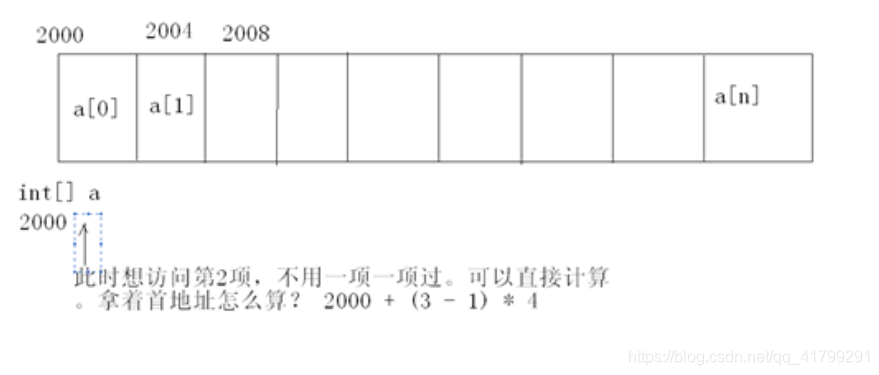
查询效率高是因为ArrayList是以数组的方式存贮值的可以用下标来查询。
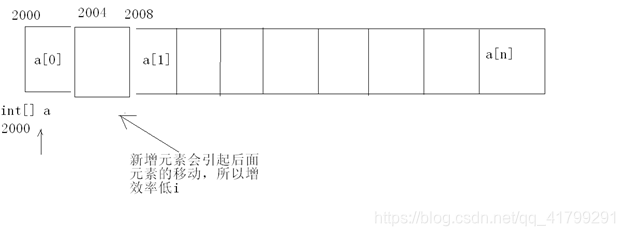
如果想在这个数组的中间或是第一项前插入一项,它的插入过程是以迭代的方式,让它后面的每一项依次往后挪,就如图上的要在第二项的位置上插入一项,其实这个过程是比较慢的,如果是你每次都在最后插入,这是个例外,因为它不用再去影响其它的元素,直接插在最后面;当然删也是同一个道理 。所以增删效率慢。
2):LinkedList:为什么查询效率低,增删效率快
LinkedList是底层用双向循环链表实现的List,链表的存储特点是不挨着,它存储的每个元素分为三段:上一项的地址、下一项的地址、元素的内容,而数组却没有上一项,下一项这种情况 ,因为数组只需要根据一个偏移量,就可以找到下一项或上一项
双向链表的底层结构图
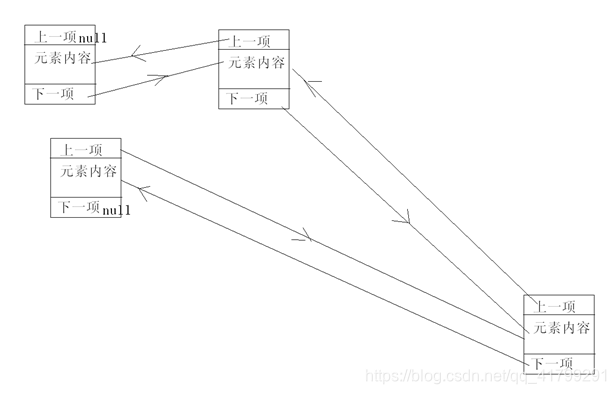
每 个元素在内存中的排列像是随机的,中间没有连续性,通过地址来找到上一项或下一项,从图上应该可以理解了
那么现在问题来了,如果查询LinkedList中的某一项,肿么办?
没有好办法,只能把元素全部过一遍,这样就会比较的慢
而它的好处体现在它的增删效率非常的快,为什么呢?
看下面的图解:
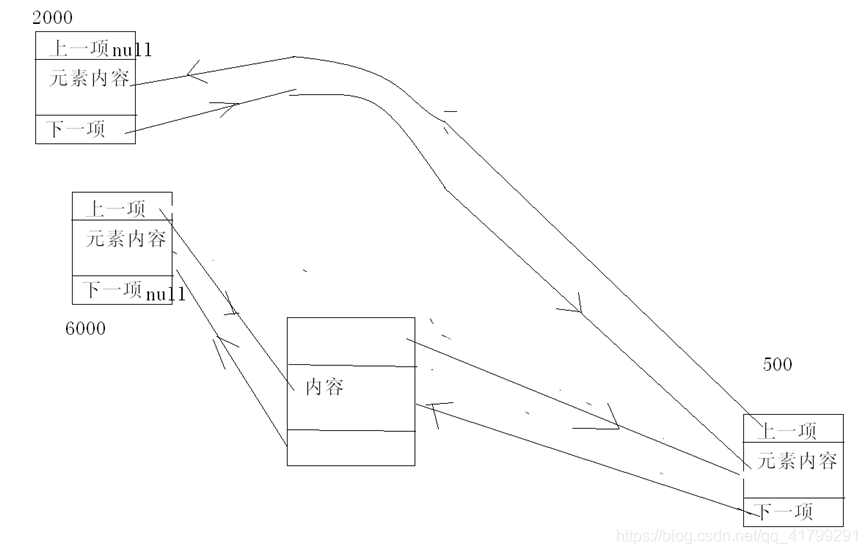
假如我把右上的一个元素删掉,可以看到左上和右下的两个元素会直接连上,至于它们两个是怎么牵上手的,这里不多讲了,你懂的…………….
同理,在下面增加一个的时候,也是同一个道理,也就是说,当你增加或删除一个元素的时候,在LinkedList里,它最多只会影响两个元素,而不像ArrayList里,当在中间插入一个元素时,它后面的所有的元素都要受到影响,那么这样在一定程度上LinkedList的增删效率就会明显的高于ArrayList的。
2.Set: 无序 不可重复的
Set的实现类:1.HashSet :无序,不存在重复元素,允许null元素的存在(只能放一个null) 重写hashcode方法和equals方法 来判断重复与否 。
2.TreeSet:该类与HashSet类最大的区别就是一个有序集合,其顺序的实现是依靠红黑树结构进行排序完成的
默认使用自然排序 实现compareable接口 实现 compareTo方法
来比较元素之间的大小关系,然后将元素按升序排列 compareTo方法返回0则认为相等
如果返回正数 则左大右 为负则左小右
3.LinkedHashSet 有序 底层是哈希表和链表实现的,迭代是性能比HashSet好 新增则稍逊HashSet
总结:HashSet是基于Hash算法实现的 其性能优于TreeSet 当要排序时才使用TreeSet
3.Map:实现类有:1.HashMap:它是线程不安全的Map,方法上都没有synchronize关键字修饰,jdk1.8改用红黑树存储,采用的是位桶数组,其底层采用红黑树, 相对于JDK1.7,HashMap处理hash冲突时,会首先存放在链表中去,但是一旦链表中的数据较多(即>8个)之后,就会转用红黑树来进行存储,优化存储速度。O(lgn)。如果是链表。一定是O(n)。
底层: 在jdk1.8之前时采用数组加链表的方式 数组查询快,链表增删快,他们相结合使得增删查都很快,HashMap的初始大小是16,
对于HashMap,我们最常使用的是两个方法:Get 和 Put
1.Put方法的原理
调用Put方法的时候发生了什么呢?
比如调用hashMap.put(‘apple’, 0) ,插入一个Key为“apple’的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index):
index= Hash(“apple”)但是,因为HashMap的长度是有限的,当插入的Entry越来越多时,再完美的Hash函数也难免会出现index(hash)冲突的情况。比如下面这样:这时候该怎么办呢?我们可以利用链表来解决。
HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可:需要注意的是,新来的Entry节点插入链表时,使用的是“头插法”。至于为什么不插入链表尾部,后面会有解释。
2.Get方法的原理
使用Get方法根据Key来查找Value的时候,发生了什么呢?
首先会把输入的Key做一次Hash映射,得到对应的index:
index= Hash(“apple”)
由于刚才所说的Hash冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我们要查找的Key
是“apple”:
第一步,我们查看的是头节点Entry6,Entry6的Key是banana,显然不是我们要找的结果。
第二步,我们查看的是Next节点Entry1,Entry1的Key是apple,正是我们要找的结果。
之所以把Entry6放在头节点,是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大。这就是HashMap的底层原理。
在jdk1.8后: 红黑树具体链接(https://www.cnblogs.com/finite/p/8251587.html)
DK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。
当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。
针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。
HashMap 在 JDK 1.8 中新增的数据结构 – 红黑树
红黑树引入了“颜色”的概念。引入“颜色”的目的在于使得红黑树的平衡条件得以简化。红黑树并不追求“完全平衡”——它只要求部分地达到平衡要求,降低了对旋转的要求,从而提高了性能。 由于它的设计,任何不平衡都会在三次旋转之内解决.旋转是因为这破环了红节点下面的节点必须为黑色节点的规则。
2: HashTable
? ? ? ?hashTable是线程安全的一个map实现类,它实现线程安全的方法是在各个方法上添加了synchronize关键字。但是现在已经不再推荐使用HashTable了,因为现在有了ConcurrentHashMap这个专门用于多线程场景下的map实现类,其大大优化了多线程下的性能。
3、ConcurrentHashMap
? ? ? ?如果你经常参加面试,一定会被问到这个map实现类,这个map实现类是在jdk1.5中加入的,其在jdk1.6/1.7中的主要实现原理是segment段锁,它不再使用和HashTable一样的synchronize一样的关键字对整个方法进行枷锁,而是转而利用segment段落锁来对其进行加锁,以保证Map的多线程安全。
但是要注意咯,在JAVA的jdk1.8中则对ConcurrentHashMap又再次进行了大的修改,取消了segment段锁字段,采用了CAS+Synchronize技术来保障线程安全。底层采用数组+链表+红黑树的存储结构,也就是和HashMap一样。这里注意Node其实就是保存一个键值对的最基本的对象。其中Value和next都是使用的volatile关键字进行了修饰,以确保线程安全。这里推荐一下大神的Volatile的深入理解篇,写的非常好http://www.cnblogs.com/xrq730/p/7048693.html
4:TreeMap
? ? ?TreeMap也是一个很常用的map实现类,因为他具有一个很大的特点就是会对Key进行排序,使用了TreeMap存储键值对,再使用iterator进行输出时,会发现其默认采用key由小到大的顺序输出键值对,如果想要按照其他的方式来排序,需要重写也就是override 它的compartor接口。此处引用一下其他大神的代码:
import java.util.Comparator;
2 import java.util.Iterator;
3 import java.util.Set;
4 import java.util.TreeMap;
TreeMap map = new TreeMap(new xbComparator());
map.put(‘key_1’, 1);
11 map.put(‘key_2’, 2);
12 map.put(‘key_3’, 3);
13 Set keys = map.keySet();
14 Iterator iter = keys.iterator();
15 while(iter.hasNext())
16 {
17 String key = iter.next();
18 System.out.println(’ ‘+key+’:’+map.get(key));
19}
20 }
class xbComparator implements Comparator
23 {
24 public int compare(Object o1,Object o2)
25 {
26 String i1=(String)o1;
27 String i2=(String)o2;
28 return -i1.compareTo(i2);
29 }
30 }
另外,TreeMap底层的存储结构也是一颗红黑树。大笑是不是发现好多都是红黑树,没错因为红黑树查找效率高,只有O(lgn)。它是一种自平衡的二叉查找树。在每次插入和删除节点时,都可以自动调节树结构,以保证树的高度是lgn。
5:5、LinkedHashMap
? ? LinkedHashMap它的特点主要在于linked,带有这个字眼的就表示底层用的是链表来进行的存储。相对于其他的无序的map实现类,还有像TreeMap这样的排序类,linkedHashMap最大的特点在于有序,但是它的有序主要体现在先进先出FIFIO上。没错,LinkedHashMap主要依靠双向链表和hash表来实现的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









