







基于模型的学习和规划
本文未经许可,禁止转载,如需转载请联系笔者
0. 引言
无论是前面第五章的关于价值函数的近似,还是第六章的基于策略梯度的深度强化学习,都没有让个体去试图理解环境,没有让他学习环境的变化规律。
如果能建一个较为准确的模拟环境动力学特征的模型或者问题的模型本身就类似于一些棋类游戏是明确或者简单的,个体就可以通过构建这样的模型来模拟其与环境的交互,这种依靠模型模拟而不实际与环境交互的过程类似于“思考”过程。通过思考,个体可以对问题进行规划、在与环境实际交互时搜索交互可能产生的各种后果并从中选择对个体有利的结果。这种思想可以广泛应用于 规则简单、但状态或结果复杂 的强化学习问题中。
1. 环境的模型
正如前面所说,可以根据价值函数或者策略函数来制定agent与环境互动的策略,但是如果能够建立 环境的模型,那么它在与环境 交互的过程 中,既可以通过实际交互来提高模型的准确程度,也可以在 交互间隙 利用构建的模型进行思考、规划,决策出对个体有力的行为。
基于模型的强化学习流程可以用下图表示:
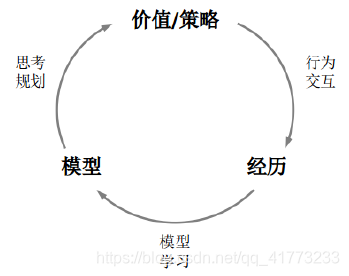
理论上来说,模型

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









