




 本文介绍了单目深度估计技术,通过神经网络对输入图像进行特征提取,预测每个像素点的深度值。特征提取过程中,网络结构设计将特征图按比例拎出,以获取不同层次的特征。为了提取物体轮廓信息,采用差异方法,通过上、下采样计算不同尺度的差异。此外,文中还提及了空洞卷积和SPP(Spatial Pyramid Pooling)技术,通过结合空洞卷积和SPP(ASPP)实现特征多样性,提高深度估计的准确性。
本文介绍了单目深度估计技术,通过神经网络对输入图像进行特征提取,预测每个像素点的深度值。特征提取过程中,网络结构设计将特征图按比例拎出,以获取不同层次的特征。为了提取物体轮廓信息,采用差异方法,通过上、下采样计算不同尺度的差异。此外,文中还提及了空洞卷积和SPP(Spatial Pyramid Pooling)技术,通过结合空洞卷积和SPP(ASPP)实现特征多样性,提高深度估计的准确性。
-
什么是单目深度估计?
-
青铜:在图片当中,深度就是距离,所以深度估计就是距离估计。这个距离,指的是图片当中每一个像素点和相机(摄像头)之间的距离。
白银:对于单目深度估计,输入的是一张图片,输出的是图像中每个像素点的深度值。即通过神经网络对输入的图像进行特征提取,最后逐一的对每个像素点做一个回归,预测出每一个像素点离相机的距离。 深度估计要做啥?
-
输入一张彩色图片
输出深度估计

也就是说,输入一张彩色的图片,输出的则是这个彩色图片中每个像素点的深度值,也就是距离值。
论文:Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals(基于拉普拉斯金字塔深度残差的单目深度估计)
第一招:特征提取网络结构设计(backbone)
整体结构图:
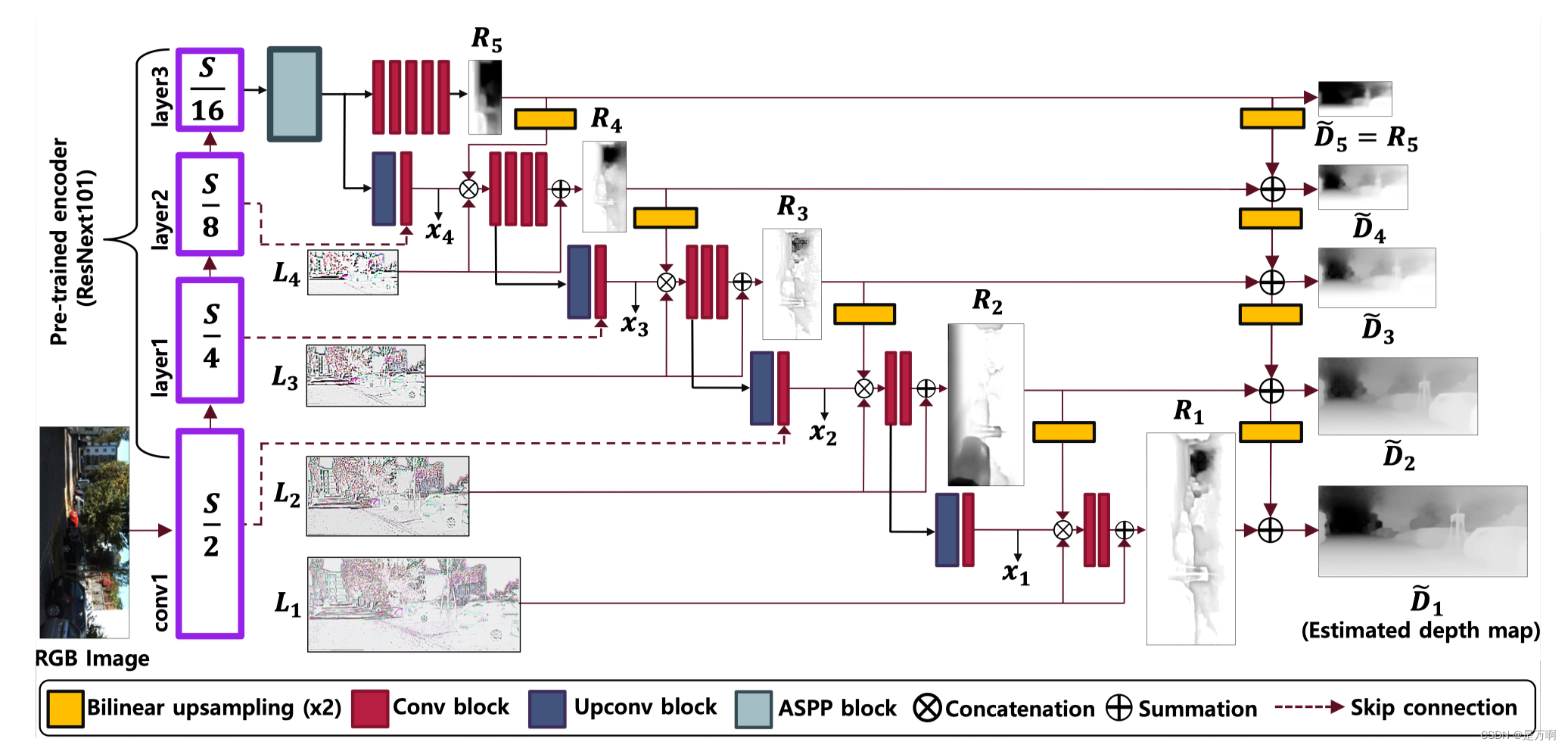
分解整体结构图:

解前小故事:有这样一道数学题−25+34 -\frac{2}{5}+\frac{3}{4}\ −52+43
对于一年级的我来说:这是啥?看不懂
对于二年级的我来说:有点印象,但是不会做
对于六年级的我老说:就这?然后做出结果
也就是说,我们对于某一件事,在不同的年龄阶段,对它的看法是不一样的。
对于本文的提取特征的网络结构,同样有这样的思想。即对于一张输入的彩色图片(某一件事),把特征提取过程分为几段去看(不同的年龄阶段),则每段的含义是不一样的(不同的看法)。
疑问一:为什么要把特征提取过程分为几段去看???
如上分解整体结构图,在对输入的彩色图像(SXSX3)进行卷进的过程中,我们要做很多次的卷积操作。而在不断卷积的过程中,我们把特征图是原始输入图像的1/2、1/4、1/8和1/16的特征图把它单独拎出来。而这拎出来的特征图,另作他用。
注:S/2是输入图像1/2倍大小的特征图尺寸,有可能是第10次提取特征得到特征图的大小,也有可能是第20次提取特征图的大小,但不是第S/2次提取特征的提取次数。
解决疑问一:是为了得到在提前特征的过程中,得到特征的多样性(后面还有其他的特征多样性)。即,在特征提取的过程中,比如第10次卷积操作得到的特征图,只能得到一些浅层的特征,比如图片的纹理或者边缘的特征信息。而在做第20次卷积的时候,得到的特征就会比第10次得到的特征更加的深,那么得到的特征信息也会更加的深层。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









