







 本文介绍了使用深度卷积神经网络(CNN)在ImageNet数据集上实现的卓越性能,包括5层卷积和3层全连接结构,采用ReLU激活、GPU加速、dropout正则化等技术。文章详细阐述了数据预处理、体系结构优化和过拟合防治措施,展示了训练细节和最终的优秀测试结果。
本文介绍了使用深度卷积神经网络(CNN)在ImageNet数据集上实现的卓越性能,包括5层卷积和3层全连接结构,采用ReLU激活、GPU加速、dropout正则化等技术。文章详细阐述了数据预处理、体系结构优化和过拟合防治措施,展示了训练细节和最终的优秀测试结果。
ImageNet Classification with Deep Convolutional Neural Networks(基于深度卷积网络的图像分类)
摘要
针对ImageNet数据集,我们训练了一个深度卷积网络,该网络有5个卷积层和3个全连接层构成,包含很多的参数,它在ImageNet测试集的表现很优秀,远远超过了第一名。为了加快训练速度,我们使用非饱和非线性函数(ReLU)以及GPU加速。为了解决过拟合的问题,首次引入了dropout正则化方法。
1.引言
CNN的参数更少,更易于训练。本文将CNN应用到图像中。同时,使用GPU搭建了一个高度优化的2D卷积工具,可以促进网络训练,而且不会有严重的过拟合。需要注意的是:移去任何卷积层(其中每一个包含的模型参数都不超过1%)都会导致性能变差。
2.数据集
将所有图片下采样到256*256,同时使用原始图片来做实验,不需要任何的特征提取,为后来的端到端学习提供了方向。
3.体系结构
该网络由5个卷积层和3个全连接层构成。
3.1ReLU激活函数
饱和激活函数会压缩输入值。例如tanh,sigmoid等,它们的输出在一个范围之内。ReLU的输出不在一个范围内,故称之为非饱和非线性函数。训练带ReLU的深度卷积神经网络比带tanh单元的同等网络要快好几倍。
3.2多个GPU并行计算
在计算机视觉领域,暂时不需要分割模型在不同的GPU上计算,但是在NLP领域,最近需要训练很大的模型,可能会考虑这个方面。
第2个和第3个卷积层之间有GPU的通讯,最后一个卷积层和第一个全连接层之间有GPU之间的通讯。
3.3LRN(Local Response Normalization) 局部响应归一化
现在LRN基本不用,后期有人提出论文说是LRN没什么用
LRN一般是在激活、池化后进行的一种处理方法。对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
3.4重叠池化。
该网络设置s=2,z=3。也即步长小于核大小,产生重叠池化,效果要比一般的不重叠池化要好。
3.5总体结构
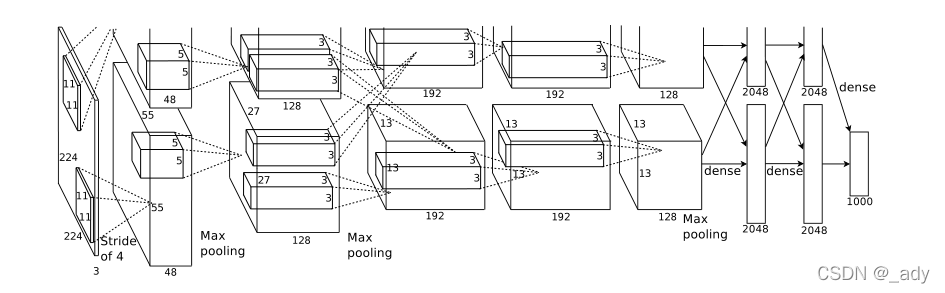
该结构可以分为两层,上层是一个GPU计算的过程,下层也是一个GPU计算的过程。可以由图看到每层所用的核大小、数量以及卷积的步长等。第2层、第4层以及第5层,只连接到位于同一个GPU内的前一层上。第3层卷积层和全连接层,连接了两个GPU之间所有的层。LRU在第1层和第2层的ReLU之后,Max Pooling在第5层和第2层的LRU之后做。ReLU非线性应用于每个卷积层及全连接层的输出。
4减少过拟合
4.1数据增强
主要是通过两种方式来进行数据增强。第一种是将原始图片裁剪为2242243的图片大小。这种方式使得训练集扩充了很多倍。第二种是改变RGB通道的强度,使得形成不同色彩的图片。
4.2随机失活
随机的把一些隐藏层的输出变成用0.5的概率设为0.
5.训练细节
使用SGD算法来进行反向传播,用一个均值为0,方差为0.01的高斯分布来初始化每一层的权值系数。
机器学习的精髓:知识的压缩,使人能看懂的东西,机器也能看懂
6.结果
结果很优秀,测试集上的表现很好。
7.讨论
有足够的数据,足够的GPU运算单元,神经网络会更容易被训练出来。

















 4007
4007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









