




 本文介绍了HBase命令行操作,包括创建表、命名空间、数据的增删改查及过滤,详细阐述了各种操作步骤,并强调所有操作在特定环境下执行。文章适合初学者,帮助理解HBase在分布式存储中的应用。
本文介绍了HBase命令行操作,包括创建表、命名空间、数据的增删改查及过滤,详细阐述了各种操作步骤,并强调所有操作在特定环境下执行。文章适合初学者,帮助理解HBase在分布式存储中的应用。
1、课程简介
- 本文章先会介绍HBase命令行,接着会介绍java代码对hbase中的表进行增删改查。
- 本文章中所有命令均在CentOS-6.4-x86_64,hadoop-2.5.2,jdk1.8.0_152,zookeeper-3.4.11,hbase-1.2.6中运行通过,为减少linux权限对初学者造成影响,所有命令均在linux的root权限下进行操作。
2、理论回顾
- HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,是行业中最常用的NoSQL数据库。HBase正确运行的前提是安装好Hadoop。
- Hadoop技术本身包含HDFS、Map/Reduce。HDFS作海量数据存储之用;M/R作海量数据计算之用。
- HDFS包含namenode、datanode。namenode对datanode中的数据建立了索引。
- zookeeper作为协调服务,为namenode提供了高可用性。
3、命令行基本操作
注意:
在执行以下命令之前,确认以下组件启动成功:zookeeper, hdfs, yarn, hbase。
在hbase安装目录的bin下面,执行如下命令进入hbase命令行:

3.1创建普通表
步骤 1 创建普通表的语法为:create ‘表的名称’,‘列族的名称’。
输入命令:
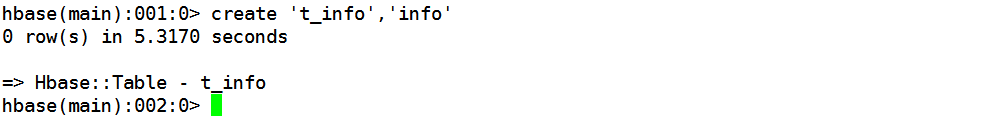
创建表“t_info”成功。
步骤 2 –list 功能:查看系统中共有多少个普通表。

由此看出系统中已经存在了3张表了。
3.2 创建namespace
创建namespace的语法为:create_namespace ‘名称‘。

步骤1 在指定namespace下创建表
在指定namespace下创建表:create ‘namespace的名称:表名‘,‘列族‘。

步骤2 查看指定namespace下的表
查看指定namespace下的表:list_namespace_tables ‘namespace的名称‘’。

3.3 增加数据
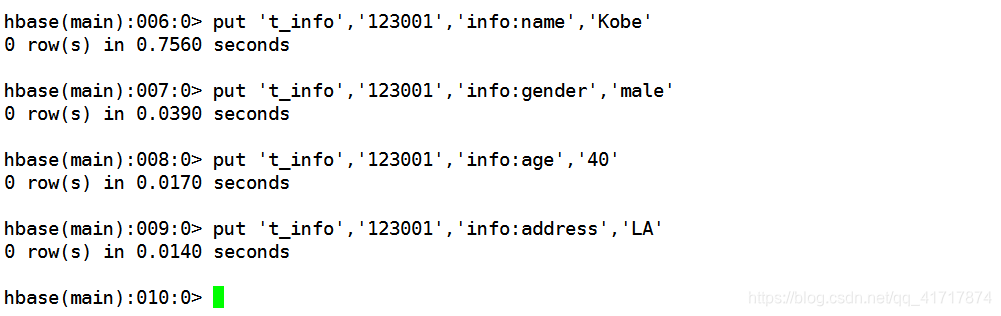
增加数据:put ‘表的名称‘,‘RowKey’,‘列的名称’,‘具体的赋值’。
将一个名字为Kobe,居住在洛杉矶的40岁男人的信息输入到表“cga_info”中:
3.4 get方式查询数据
步骤 1 get 功能:精确查询。
精确查询某一个RowKey中存储的内容:get ‘表的名称‘,’RowKey‘

步骤 2 精确查询某一个RowKey中的一个单元格中存储的内容。
语法:get ‘表的名称‘,’RowKey‘,‘列名’

3.5 scan方式查询数据
步骤1 查询表中某个列族下所有列的信息:scan ‘表的名称‘,{Columns=>’列‘}

步骤2 查询表中具体的一个列中存储的信息。
语法:scan ‘表的名称‘,{Columns=>’列的具体名称‘}

3.6 指定条件查询数据
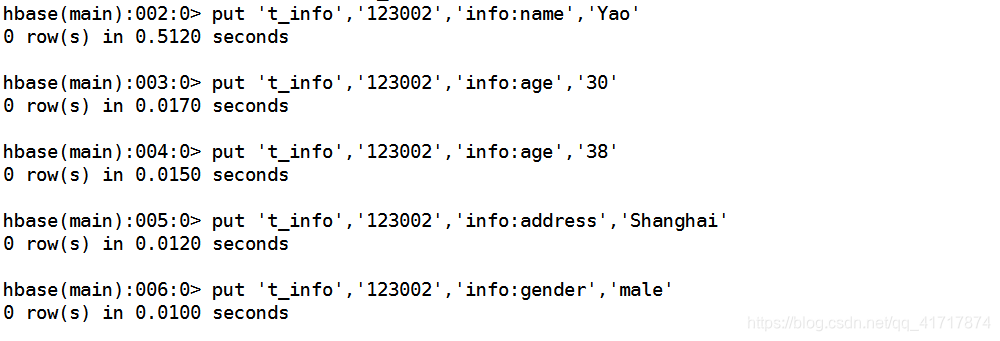
步骤0 加入姚明信息到数据库中
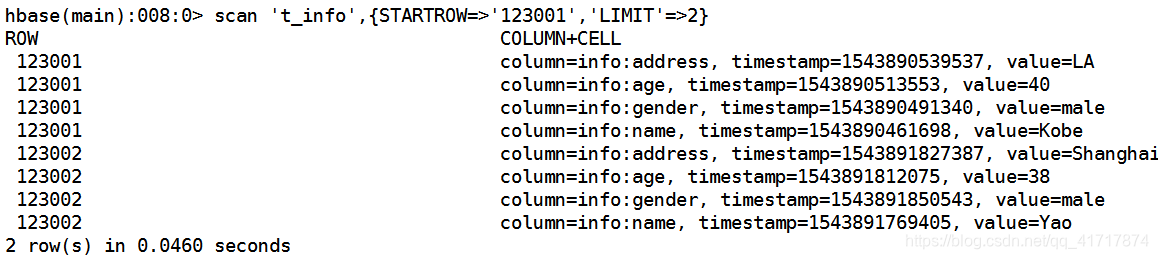
步骤 1 查询RowKey为“123001”和“123002”中的数据。
步骤 2 查询Rowkey为“123001”和“123002”中列名称为name的单元格中存储的信息。

3.7 更新数据
步骤 1 首先查询表中Rowkey为123001的年龄信息。

步骤 2 更改表中Rowkey为123001的年龄信息。

步骤 3 再次查询表中Rowkey为123001的年龄信息。

由步骤2和步骤3的结果比较可得,年龄信息已经被更新。
3.8 删除数据
(1)使用delete删除某一列数据
步骤 1 首先查询表中Rowkey为123001的信息。

步骤 2 使用delete删除123001中age列所存储的数据。

步骤 3 再次查询表中Rowkey为123001的信息。

由步骤1和步骤3的结果比较可得,年龄信息已经被删除了。
(2) 使用deleteall删除整行数据
步骤 1 使用deleteall删除表cga_info中123001的整行数据。

步骤 2 再次查询表中Rowkey为123001的信息。

此时表中已经没有RowKey为123001的信息,说明行数据删除成功。
(3) 使用drop删除数据表
步骤 1 首先disable ‘表的名称‘,然后再使用drop ‘表的名称‘删除数据表。

步骤 2 查询当前命名空间下的表。

结果显示表t_info已经被删除了。
3.9 过滤数据
Filter允许在Scan过程中,设置一定的过滤条件,符合条件的用户数据才返回,所有的过滤器都在服务端生效,以保证被过滤掉的数据不会传送到客户端。
示例1:查询年龄为38的人。

示例2:查询名叫Yao的人。

示例3:查询表中所有人的性别信息。

示例4:查询表中所有人的地址信息并且找出住在上海的人。

Fliter可以根据列族,列,版本等更多的条件来对数据进行过滤,这里只演示了4种过滤方式,带有过滤条件的RPC查询请求会把过滤器分发到各个RegionServer,这样可以降低网络传输的压力。
4、总结
HBase在存储上百万的列数十亿的行的情况下还能实时读取,值得我们深入使用和研究。后面我们将连载大数据系列博客,欢迎关注和交流。
本文中所有安装软件等更多福利请入群后向管理员获取。更有专业知识答疑解惑。入群即送价值499元在线课程一份。
QQ群号:560819979
敲门砖(验证信息):信天游

















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









