









文章目录
参考书籍:《深度学习推荐系统》、《Python机器学习 第3版》塞巴斯蒂安著
1、算法原理:数学原理 & 训练方式
1.1 数学原理
以推荐的语境为例,LR的数学形式如图1所示,
(1)将特征向量
x
⃗
=
(
x
1
,
x
2
,
.
.
.
,
x
m
)
T
\vec {x}=(x_1,x_2,...,x_m)^T
x=(x1,x2,...,xm)T作为模型的输入
(2)通过为各特征赋予相应的权重
(
w
0
,
w
2
,
.
.
.
,
w
m
)
T
(w_0,w_2,...,w_m)^T
(w0,w2,...,wm)T,来表示各个特征的重要性差异,将各个特征进行加权求和,得到净输入
z
z
z(Net input function), 也即
w
⃗
T
x
⃗
\vec {w}^T\vec{x}
wTx
z
=
w
⃗
T
x
⃗
=
w
0
x
0
+
w
1
x
1
+
.
.
.
+
w
m
x
m
z=\vec {w}^T\vec{x}=w_0x_0+w_1x_1+...+w_mx_m
z=wTx=w0x0+w1x1+...+wmxm
(3)将z输入sigmoid函数,使之映射到0-1的区间,此时得到的是样本属于某一类的概率。sigmoid函数的具体形式如下
f
(
z
)
=
1
1
+
e
−
z
f(z) = \frac{1}{1+e^{-z}}
f(z)=1+e−z1
因此,逻辑函数的整个推断过程如下
f
(
x
⃗
)
=
1
1
+
e
−
(
w
⃗
⋅
x
⃗
+
b
)
f(\vec{x}) = \frac{1}{1+e^{-(\vec{w}·\vec{x}+b)}}
f(x)=1+e−(w⋅x+b)1
(4)预测概率可以简单的通过阈值函数(Threshold function)简单的转换为二元输出(假设阈值为0.5)
y
^
=
{
1
i
f
ϕ
(
z
)
≥
0.5
0
o
t
h
e
r
\hat{y} = \left\{ \begin{array}{ll} 1 \ \ if\ \phi(z)≥0.5\\ 0 \ \ other \end{array} \right.
y^={1 if ϕ(z)≥0.50 other
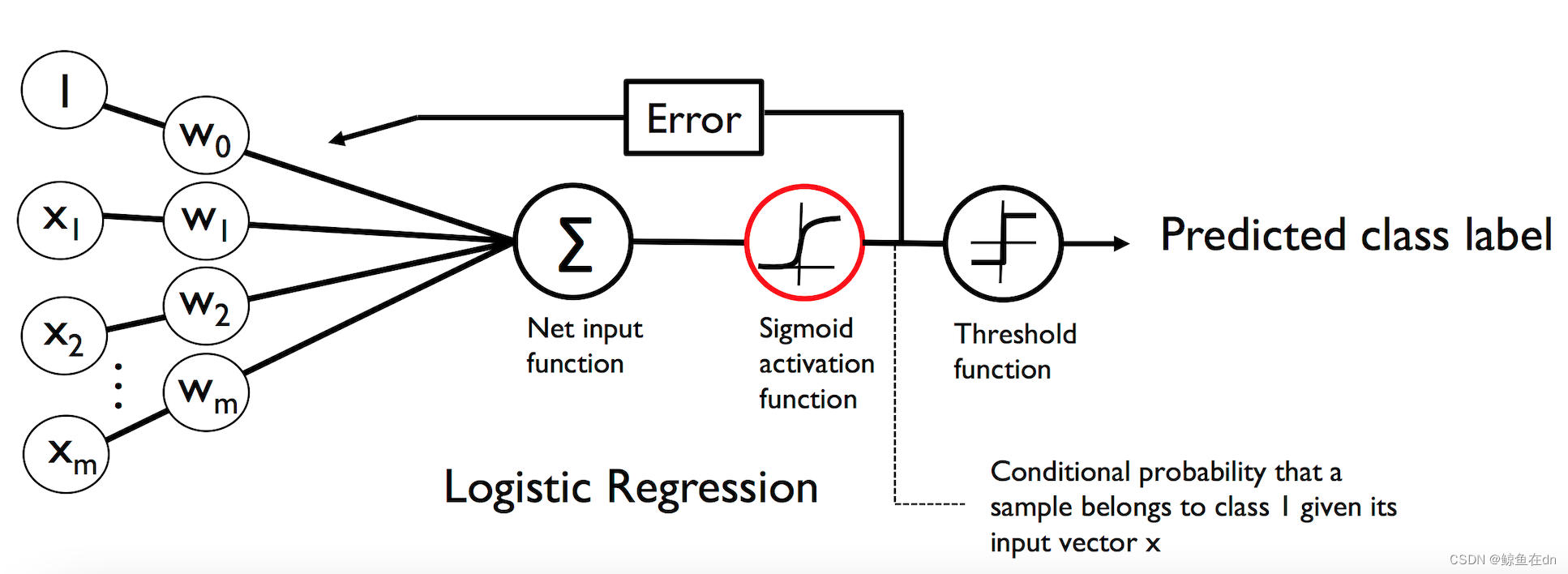
1.2 训练方式:使用梯度下降法更新模型参数
前置说明:梯度下降法,是一个一阶最优化算法,目的是找到一个函数的局部极小值,因此在优化某模型的目标函数时,只需要对目标函数进行求导,得到梯度的方向,沿梯度的反方向下降,并迭代此过程直至寻找到局部最小点。
1.2.1 确定目标函数
使用梯度下降法求逻辑函数的第一步,是确定逻辑回归的目标函数。用
f
w
(
x
)
f_w(x)
fw(x)来表示
1
1
+
e
−
(
w
⃗
⋅
x
⃗
+
b
)
\frac{1}{1+e^{-(\vec{w}·\vec{x}+b)}}
1+e−(w⋅x+b)1。

1.2.1 确定梯度方向& 参数更新公式

2、基于逻辑回归模型的推荐流程
逻辑回归将推荐问题看成一个分类问题,通过预测正样本的概率对物品进行排序。正样本既可以是用户“点击”了商品,也可以是用户“观看”了某视频,均是推荐系统希望用户产生的“正反馈”行为。因此,逻辑回归问题转化成了一个点击率问题。
在上述算法数学原理中,如果不加阈值函数,则sigmoid函数输出结果就可以得到“点击率”。
2.1 逻辑回归的优势
1)可解释性强
算法工程师可以轻易的根据权重的不同,解释哪些特征比较重要,在模型预测有偏差时,定位是哪些因素影响了最后的结果。在与负责运营、产品的同事合作时,也便于给出可解释的原因,有效降低沟通成本。
2)工程化的需要
逻辑回归易于并行化、模型简单、训练开销小。囿于工程团队的限制,即使其他复杂模型的效果有所提升,在没有明显击败逻辑回归之前,公司也不会贸然加大计算资源的投入。
3)数学含义的支持
逻辑回归假设因变量服从伯努利分布,用户是否点击广告,即CTR模型的因变量也是服从伯努利分布的。所以采用逻辑回归作为CTR模型是符合“点击”这一物理意义的。
2.2 逻辑回归的局限性
表达能力不强,无法进行特征交叉,特征筛选等一系列操作,因此不可避免的造成信息的损失。
3、面试高频题 & 解答文章集合
https://zhuanlan.zhihu.com/p/100763009
文章2:https://blog.youkuaiyun.com/qq_16236875/article/details/91977114
问题记录:
- 逻辑回归的假设:服从伯努利分布
- 逻辑回归的损失函数:对数损失函数,又称为binary cross entropy(PS:7种损失函数的解释https://blog.youkuaiyun.com/weixin_44177594/article/details/124034699)
- 逻辑回归的求解方法:梯度下降
- 逻辑回归的目的:二分类
- 逻辑回归如何分类:划定阈值
- 逻辑回归在训练的过程当中,如果有很多的特征高度相关或者说有一个特征重复了100遍,会造成怎样的影响?
- 为什么不选平方损失函数,而选对数损失函数
- 有很多的特征高度相关或者说有一个特征重复了100遍,会造成怎样的影响
- 为什么要去掉相关的特征
- 线性回归和逻辑回归的区别
4、用Python实现逻辑回归的两种方式:直接实现 & scikit-learn实现
4.1直接实现
class LogisticRegressionGD(object):
"""Logistic Regression Classifier using gradient descent.
Parameters
------------
eta : float
Learning rate (between 0.0 and 1.0)
n_iter : int
Passes over the training dataset.
random_state : int
Random number generator seed for random weight
initialization.
Attributes
-----------
w_ : 1d-array
Weights after fitting.
cost_ : list
Logistic cost function value in each epoch.
"""
def __init__(self, eta=0.05, n_iter=100, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
""" Fit training data.
Parameters
----------
X : {array-like}, shape = [n_examples, n_features]
Training vectors, where n_examples is the number of examples and
n_features is the number of features.
y : array-like, shape = [n_examples]
Target values.
Returns
-------
self : object
"""
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
net_input = self.net_input(X)
output = self.activation(net_input)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
# note that we compute the logistic `cost` now
# instead of the sum of squared errors cost
cost = -y.dot(np.log(output)) - ((1 - y).dot(np.log(1 - output)))
self.cost_.append(cost)
return self
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, z):
"""Compute logistic sigmoid activation"""
return 1. / (1. + np.exp(-np.clip(z, -250, 250)))
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.net_input(X) >= 0.0, 1, 0)
# equivalent to:
# return np.where(self.activation(self.net_input(X)) >= 0.5, 1, 0)
4.2 scikit-learn实现
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=100.0,
random_state=1,
solver='lbfgs',
multi_class='ovr')
lr.fit(X_train_std, y_train)
注:sklearn中的LogisticRegression参数、方法、属性说明https://scikit-learn.org.cn/view/378.html




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









