







 本文概述了命名实体识别(NER)的研究,包括任务类型、数据集、传统方法和深度学习方法。NER任务分为粗粒度和细粒度,深度学习方法如CNN、RNN、Transformer在NER中表现出色,而预训练模型如BERT带来了性能提升。文章还讨论了面临的挑战,如数据标注、非正式文本处理,以及未来研究方向,如细粒度NER、深度迁移学习和工具开发。
本文概述了命名实体识别(NER)的研究,包括任务类型、数据集、传统方法和深度学习方法。NER任务分为粗粒度和细粒度,深度学习方法如CNN、RNN、Transformer在NER中表现出色,而预训练模型如BERT带来了性能提升。文章还讨论了面临的挑战,如数据标注、非正式文本处理,以及未来研究方向,如细粒度NER、深度迁移学习和工具开发。
前言:研究课题定为特定领域的命名实体识别,所以先阅读一篇综述,在此简单记录阅读过程。
摘要
在文章中,首先介绍现有的NER资源,包括标记的NER语料库及现成的NER工具,然后对现有的工作进行了分类:输入的分布式表示、上下文编码器、标签解码器。接下来探讨当前最有代表性的深度学习NER方法。最后,介绍NER面临的挑战和未来的研究方向。
简介
命名实体识别(NER)的概念
命名实体识别(NER)旨在识别文本中提到刚性指示符预定义的语义类型,例如人员,位置,组织等。
作者将命名实体分为了两大类,第一类:通用命名实体(如人、地点)。第二类:特定领域命名实体(如蛋白质,基因)。而该文章聚焦的是英文、第一类命名实体识别任务。
命名实体识别的方法
- 基于规则的方法
- 无监督学习的方法
- 基于特征的规则学习方法
- 基于深度学习的方法
背景
命名实体识别任务种类
- 粗粒度命名实体识别:总的类别比较少,并且每个实体只有一个类别。
- 细粒度命名实体识别:总的类别比较多,并且每个实体可能有多个类别。
数据集资源
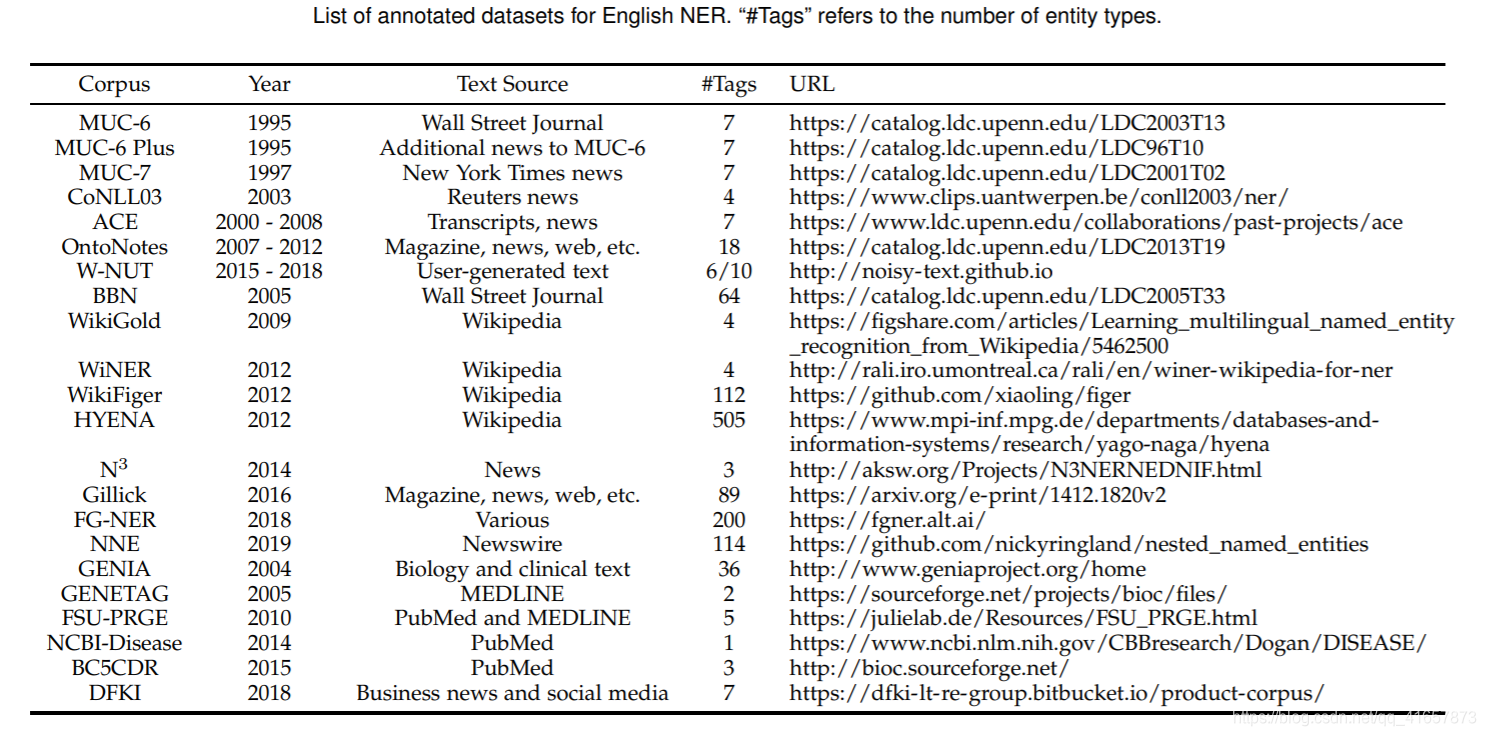
现有工具
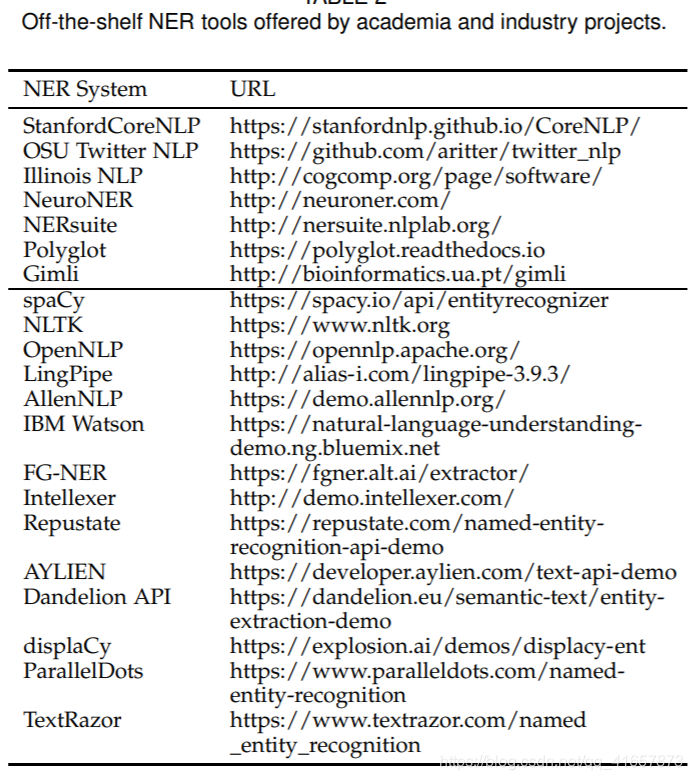
传统方法
基于规则的方法
基于规则的命名实体识别系统依靠手工制作的规则,主要是语义与句法规则。当语料充足时,基于规则的系统可以很好的工作,但是由于规则是基于特定领域的以及词典不完整,导致经常会从此类系统中得到高的准确率和低的召回率,并且这些系统无法转移到其他领域使用。
无监督学习方法
无监督学习的一种典型方法是聚类,基于聚类的NER系统基于上下文相似性从聚类组中提取命名实体。这种方法的关键思想是词汇资源、词汇模式以及在大型语料库上计算的统计信息,可用于推断命名实体。
基于特征的监督学习方法
应用监督学习,NER被转换为多类分类或序列标记任务。 给定带注释的数据样本,特征经过精心设计以表示每个训练示例。 然后利用机器学习算法来学习模型,以从未被标记的数据中识别出相似的样式。
基于多种特征的选取,许多机器学习算法已经被应用在NER领域,例如:HMM(隐马尔科夫模型)、DT(决策树)、Maximun Entropy Models(最大熵模型)、SVM、CRF等。
深度学习方法
深度学习的主要优势是表示学习的能力以及向量表示和神经处理所赋予的语义组成,这使机器可以获取原始数据,并自动发现分类或检测所需的潜在表示和处理。
为什么深度学习适用于NER
- NER受益于非线性变换,该变换生成从输入到输出的的非线性映射。与线性模型(例如对数线性HMM和线性链CRF)相比,基于深度学习的模型能够通过非线性激活函数从数据中学习错综复杂的特征。
- 深度学习省去了设计NER特征的大量工作。传统基于特征的方法需要大量的工程技术和领域知识,而基于深度学习的模型可以有效的从原始数据中自动学习有用的表示形式和潜在因素。
- 可以通过梯度下降在端到端范式中训练深度神经NER模型。 此属性使我们能够设计更复杂的NER系统。
输入的分布式表示
NER模型中使用的分布式表示共有三种:word-level, character-level, and hybrid representations。
- word-level:采用词级别的表示通常使用无监督算法(例如CBOW,Skip-gram)对大量文本进行预训练。最近的研究显示,这种预训练词嵌入的重要性,作为输入可以在NER模型训练期间固定或进一步微调预训练的词嵌入。常用的词嵌入工具包括Word2Vec、GloVe、fastText、SENNA.
- character-level::两种广泛应用的提取字符级别的表示架构:基于CNN(如图a)和基于RNN(如图b)的模型。
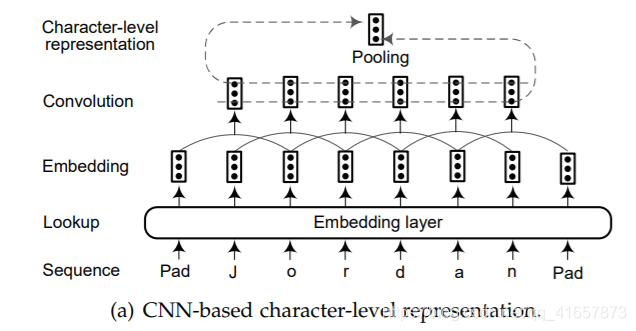
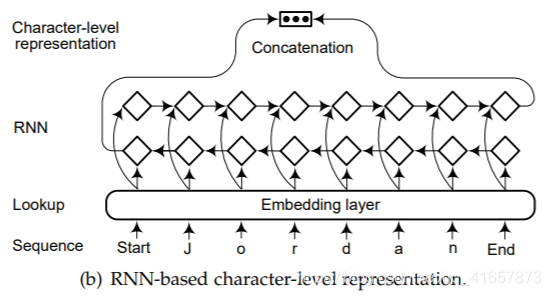
图(c)表示上下文字符串嵌入,使用字符级神经语言模型为句子上下文中的字符串生成上下文嵌入。
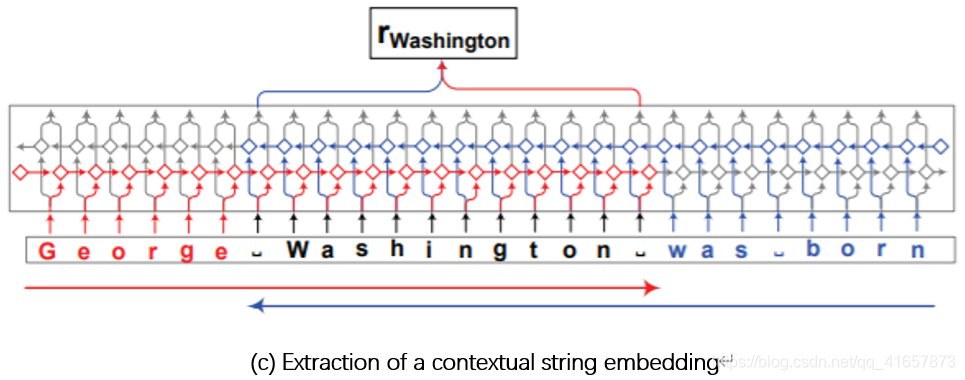
从句子上下文中提取单词"Washington"的上下文字符串嵌入,该模型从前向语言模型(红色)中提取单词中最后一个字符之后的输出隐藏状态。从后向语言模型(蓝色) 中提取单词中第一个字符之前的输出隐藏状态。 将两个输出的隐藏状态串联起来,形成单词的最终嵌入。
混合表示
除了单词级和字符级的表示方法之外,在输入上下文编码之前,还可以将地名词典、词汇相似性、语言依赖和视觉特征等纳入最终的表示法中。即将基于深度学习的方法与基于特征的方法混合在一起。这有助于提高NER性能,但是可能会降低系统的通用性。
在本篇文章中将语境化的语言模型归纳为混合表示,其中包括预训练模型Bert(需要大量的预料进行训练)和辅助嵌入(位置和分段嵌入)。
Context Encoder Architectures
Convolutional Neural Networks
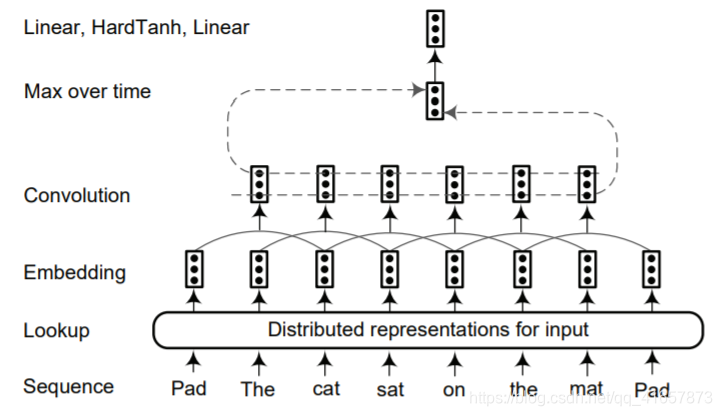
如上图所示,是一种句子逼近网络,该模型对整个句子的单词进行标记,在输入表示之后将输入序列中的每个单词嵌入到N维向量中。然后使用卷积层在每个单词周围产生局部特征,并且卷积层的输出大小取决于句子中单词的数量。通过结合由卷积层提取的局部特征向量来构造全局特征向量。 全局特征向量的维数是固定的,与句子长度无关,以便应用后续的标准仿射层。(这里有疑问)
Strubell等提出了ID-CNN,由于能够处理更大的上下文和结构化的预测,它的计算效率更高。上图显示了一个滤波器宽度为3且最大扩张宽度为4的ID-CNN的体系结构。实验结果表明,与Bi-LSTM-CRF相比,ID-CNN的测试时间加快了14-20倍,同时保持了相当的准确性。
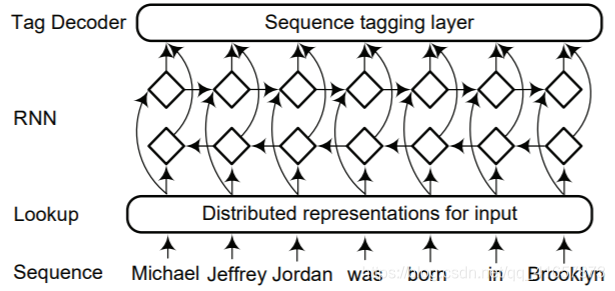
Recurrent Neural Networks
RNN网络和其变体例如GRU、LSTM等在建模顺序数据方面取得了瞩目的成就。特别是双向RNN能充分利用过去和将来的信息,下图是一个典型的基于RNN的上下文编码器的体系结构。
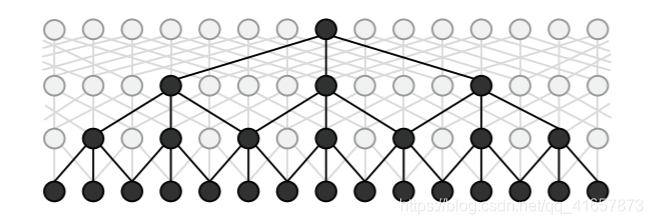
Recursive Neural Networks
命名实体与语言成分相关度很高,然而典型的序列标注模型很少考虑到句子的短语结构。该模型递归计算每个节点的隐藏状态向量,并根据这些隐藏向量对每个节点进行分类。下图显示了如何递归计算每个节点的两个隐藏状态特征。

用于NER的双向递归神经网络,其计算是从两个方向递归进行的。自下而上的计算每个节点的子树的语义组成,自上而下的方向则是将包含子树的语言结构传播到该节点。给定每个节点的隐藏矢量,网络将计算实体类型加上特殊的非实体类型的概率分布。
Neural Language Models
语言模型是描述序列生成的一系列模型。 给定令牌序列(t1t_{1}t1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









