










中文版FPGA vs GPU对比总结:
1 FPGA强大的原始数据计算力及可重构性,允许它处理任意精度的数据,但GPU的数据处理受限于开发平台。
2 FPGA片上资源可重构行及灵活的硬件布局特性使其具有强大的片上计算能力,故FPGA的数据处理效率高,但由于GPU在运算时需要外部处理器的支持,外部硬件资源的加入,导致对数据处理速度大大降低。
3 FPGA可以灵活指定数据处理深度,其可重配置性及指定宽度的存储资源灵活运用,允许DNN算法的大量多线程并行执行,但是GPU在线程并发过多时,计算力就大大减弱且效率较低。但由于CUDA是面向软件开发者开发的,其接口配置较为简单,而FPGA的接口即使可以灵活地接入到任意设备,不过还是需要开发者具有一定地硬件基础,方能更好地利用其灵活性。
4 函数安全性方面:GPU对ADAS这种对函数安全性应用有一定要求地应用来说,缺乏安全性,如果额外考虑安全性能地话势必又要耗费更多地时间。但FPGA具有良好的函数安全性,因此FPGA开发被广泛地应用到包括ADAS(Advanced Drivers Assistance System,自动驾驶)等一系列有安全性能要求地应用中。
综上,作者对FPGA在广泛地AI算法加速领域具有的强大地应用前景持以比较乐观的态度。
Ref.1 深入理解FPGA加速原理——不是随便写个C代码去HLS一下就能加速的_qq_32010099的博客-优快云博客_fpga加速卡的原理
1 FPGA加速的优势到底在哪里?
FPGA的DDR带宽、运行频率及运算数量元(低端芯片)都比不上GPU,但对于片上内存,FPGA具有更高的计算容量,而片上内存在深度学习等应用中对于减少延迟的产生是至关重要的。大量的片上Cache缓存减少了外部内存读取带来的内存瓶颈,也减少了高内存带宽需要的功耗和成本,因为访问DDR等外部存储需要消耗大于芯片本身做计算的能量。而FPGA片上内存的大容量和灵活配置能力,减少了对外部DDR的读写,自然可以缓解内存瓶颈。
FPGA最擅长实时流水线运算,就是各个阶段的处理过程重叠在一起。比如CPU做一次卷积的时间要小于FPGA,但FPGA能够充分利用图像正在传输的时间,还能并行流水线的第二次卷积,故FPGA运算延迟较小,能达到最高的实时性。
其次FPGA是硬件可编程的,故其每次所做的运算都是固定的,无需指令译码和数据选通。
Ref.2. 《FPGA vs GPU for Machine Learning Applications: Which one is better?》
1 Background
Since the popularity of using machine learning algorithms to extract and process the information from raw data, it has been a race between FPGA and GPU vendors to offer a hardware platform that runs computationally intensive machine learning algorithms fast and efficiently. Even though GPU have been aggressively positioned as the most efficient platform for this new area, FPGAs have shown a great improvement in both power consumption and performance in DNN applications, which offer high accuracies for important image classification tasks and are therefore becoming widely adopted. 功率高
To form your own opinion, I invite you to read this blog, which first touches on the benefits and barriers of using FPGAs and GPU, and consider the studies performed by the main players in this field.
2 DNN computation
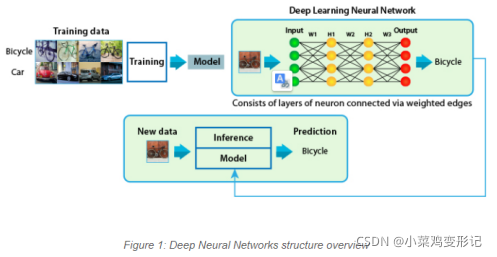
In this graph, each neuron and edge have a value, and the network has four layers. The computation of the network is derived by going through each layer. Each neuron’s value is calculated by multiplying and accumulating all the values of the previous layer’s neurons with the corresponding edge weights. This shows that the computation relies on the multiplication and accumulation operations.
每个神经元的值由前层网络神经元乘以权重计算得到。计算依赖于乘加运算。
3 Working Process of DNN
To predict a given sample, passing forward through the layers is enough.
For training, the prediction error is passed back to the model to update the network weights for accuracy.
Users of DNNs have been using different data types which has challenged GPUs and brought home the benefits of FPGAs for machine learning application.
随着DNN的用途逐渐广泛,其数据类型的多样化是对GPU平台精度的一个大挑战。因此开始转战FPGA来应用到机器学习中。
4 FPGA vs GPU - advantages and disadvantages
(1) Raw Compute Power 原始数据计算力
Under the condition of the two kinds of chips have the same compute power, when it comes to on-chip memory, which is essential to reduce the latency in deep learning applications, FPGAs result in significantly higher computer capability. The high amount of on-chip cache memory reduces the memory bottlenecks associated with external memory access as well as the power and costs of a high memory bandwidth solution. In addition, the flexibility of FPGAs in supporting the full range of data types precision is one of the strong arguments for FPGAs for DNN applications.The reason behind this is because deep learning applications are evolving at a fast pace and users are using different data types. To catch up with this demand, GPU vendors must tweak the existing architectures to stay up-to-date. So, GPU users must halt their project until the new architecture becomes available. Therefore, the re-configurability of FPGAs comes in handy because users can implement any custom data type into the design.
FPGA的片上计算能力较强。并且支持任意精度的运算,这个特点特别适合DNN的快速演变,因为GPU框架的更新需要时间,开发者必须等到新的GPU框架开发出来之后才能进行要发展的项目,亦即平台框架在某种程度上决定了项目工程。FPGA的重构特性能够帮助开发者开发任意数据类型的设计。
(2) Efficiency and Power 功效
FPGAs are well-known for their power efficiency. The main reason for GPUs being power-hungry is that they require additional complexity around their compute resources to facilitate software programmability. Although the NVidia V100 provides a comparable efficiency to Xilinx FPGAs due to the hardened Tensor Cores for tensor operations for today’s deep learning workloads, it is unpredictable for how long NVidia’s Tensor Cores remain efficient for deep learning applications, as this field is evolving quite fast. The reconfigurability of FPGAs in addition to the software development stack of main vendors such as Xilinx and Intel provides much higher efficiency for a large number of end applications and workloads.
GPU用于DL的计算时效率底下的原因是它们需要在计算资源外额外的计算力(外置处理器)来加速软件程序开发,尽管NVidia提供了一些计算核但是由于DL领域发展迅速,不知道这种短暂性的计算力提供还能持续多久。而且硬件之间尤其是处理器对存储器的访问,需要耗费大量的时间。但是由于FPGA的可重构性(硬件布局,比如FPGA+ARM的ZYNQ),为大量的计算提供了更高的效率。
(3) FPGA’s Flexibility and CUDA’s Ease-of-Use FPGA的灵活性及CUDA的用户友好特性
The latency and power associated with memory access and memory conflicts increase rapidly as data travel through the memory hierarchy. Data flow in GPUs is defined by software and is directed by the GPU’s complex memory hierarchy. And the architecture of the GPU, which is Single Instruction Multiple Thread. The feature allows GPUs to be more power efficient than CPUs. However, in the case of receiving a large number of GPU threads, only parts of a workload can be mapped efficiently into vastly parallel architecture, and if enough parallelism cannot be found within the threads, this results in lower performance efficiency.
GPU优秀的点在于它的单指令多线程功能,如果线程过多的时,只有一部分指令可以并行执行,如果这些线程中没有足够的并行指令(即并行深度有限,这里是指处理器并行处理能力不足,无法并行处理足够多的线程),导致整个运算过程处于低功率状态。
FPGAs can deliver more flexible architectures, which are a mix of hardware programmable resource, DPS and BRAM blocks. User can address all the needs of a desired workload by the resources provided by FPGAs. This allows user to reconfigure the datapath easily, even during run time, using parallel configuration. This unique re-configurability means the user is free from certain restrictions, like SIMT or a fixed datapath, yet massively parallel computations are possible.
FPGA的可重配置性以及指定宽度的存储资源灵活运用,允许大量多线程并行。
Another important feature of FPGAs, and one that makes them even more flexible is the any-to-any I/O connection, which allows FPGAs to connect to any device.
Regarding ease-of-use, GPUs are more easy going than FPGAs. This is one of the main reasons that GPUs are widely used these days. CUDA is very easy to use for Software developers, who don’t need an in-depth understanding of the underlying hardware. While using FPGAs, the developer should have the knowledge of both FPGAs and machine learning algorithms. This is the main challenge for FPGA vendors.
CUDA面向软件开发人员,所以接口界面简单使得开发过程只需要考虑软件层面,而不需要考虑硬件层次。但是对FPGA的DL运用使得开发人员必须对底层硬件层级具有一定程度的了解,从而可以灵活运用FPGA灵活的对外接口。目前的一些开发工具如Vivado HLS使得在FPGA上的算法开发越来越简单。
(5)Functional Safety函数安全性
Some applications, such as ADAS, do require functional safety. GPUs are designed for graphics and high-performance computing systems where safety is not a necessary. While if it be designed in a way to meet the safety requirements, this could be a time-consuming challenge for GPU vendors.
On other hand, FPGAs have been used in industries where functional safety plays a very important role such as automation, avionics and defense. Therefore, FPGAs have been designed in way to meet the safety requirement of wide range of applications including ADAS.
5 Conclusion
FPGAs have shown stronger potential over GPUs for the new generation of machine learning algorithms where DNN comes to play massively. The main winning points of FPGAs over GPUs would be the flexibility provided by FPGAs to play with different data types-such as binary, ternary, and even custom ones - as well as the power efficiency and adaptability to irregular parallelism of sparse DNN algorithms. 所以对FPGA的任意精度编程HLS中实现对一个AI based on FPGAer 来说,需要掌握。However, the challenge for FPGA vendors is to provide an easy-to-use platform.
Building any type of advanced FPGA designs such as for ML require advance FPGA design and verification tools. Simulation is the de-factor verification methodology for verifying FPGA designs using mixed-language HDL with C families testbenches. Compilation and simulation speed are the key factors the faster simulations you can do the more test scenarios you can check within a given timeframe. 仿真验证debug在FPGA开发中是十分重要并且耗费时间的一步。因此需要借助强大的debug工具。


















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











