




环境配置
1. 创建虚拟环境
uv init
uv venv --python 3.12
source .venv/bin/activate
2. 安装 PyTorch
uv pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
3. 安装 Flash Attention
uv pip install flash-attn==2.7.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/ --no-build-isolation
4. 安装其他依赖
uv pip install transformers==4.46.3 tokenizers==0.20.3 einops addict easydict psutil wheel
使用方法
基本用法
from modelscope import AutoModel, AutoTokenizer
import torch
import os
# 设置 GPU
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
# 加载模型
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True
)
model = model.eval().cuda().to(torch.bfloat16)
print(model)
print(model.config)
DeepseekOCRForCausalLM(
(model): DeepseekOCRModel(
(embed_tokens): Embedding(129280, 1280)
(layers): ModuleList(
(0): DeepseekV2DecoderLayer(
(self_attn): LlamaFlashAttention2(
(q_proj): Linear(in_features=1280, out_features=1280, bias=False)
(k_proj): Linear(in_features=1280, out_features=1280, bias=False)
(v_proj): Linear(in_features=1280, out_features=1280, bias=False)
(o_proj): Linear(in_features=1280, out_features=1280, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): DeepseekV2MLP(
(gate_proj): Linear(in_features=1280, out_features=6848, bias=False)
(up_proj): Linear(in_features=1280, out_features=6848, bias=False)
(down_proj): Linear(in_features=6848, out_features=1280, bias=False)
(act_fn): SiLU()
)
(input_layernorm): DeepseekV2RMSNorm()
(post_attention_layernorm): DeepseekV2RMSNorm()
)
(1-11): 11 x DeepseekV2DecoderLayer(
(self_attn): LlamaFlashAttention2(
(q_proj): Linear(in_features=1280, out_features=1280, bias=False)
(k_proj): Linear(in_features=1280, out_features=1280, bias=False)
(v_proj): Linear(in_features=1280, out_features=1280, bias=False)
(o_proj): Linear(in_features=1280, out_features=1280, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): DeepseekV2MoE(
(experts): ModuleList(
(0-63): 64 x DeepseekV2MLP(
(gate_proj): Linear(in_features=1280, out_features=896, bias=False)
(up_proj): Linear(in_features=1280, out_features=896, bias=False)
(down_proj): Linear(in_features=896, out_features=1280, bias=False)
(act_fn): SiLU()
)
)
(gate): MoEGate()
(shared_experts): DeepseekV2MLP(
(gate_proj): Linear(in_features=1280, out_features=1792, bias=False)
(up_proj): Linear(in_features=1280, out_features=1792, bias=False)
(down_proj): Linear(in_features=1792, out_features=1280, bias=False)
(act_fn): SiLU()
)
)
(input_layernorm): DeepseekV2RMSNorm()
(post_attention_layernorm): DeepseekV2RMSNorm()
)
)
(norm): DeepseekV2RMSNorm()
(sam_model): ImageEncoderViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
)
(blocks): ModuleList(
(0-11): 12 x Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate='none')
)
)
)
(neck): Sequential(
(0): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
(net_2): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(net_3): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
)
(vision_model): VitModel(
(embeddings): CLIPVisionEmbeddings(
(patch_embedding): Conv2d(3, 1024, kernel_size=(14, 14), stride=(14, 14), bias=False)
(position_embedding): Embedding(257, 1024)
)
(transformer): NoTPTransformer(
(layers): ModuleList(
(0-23): 24 x NoTPTransformerBlock(
(self_attn): NoTPAttention(
(qkv_proj): Linear(in_features=1024, out_features=3072, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(mlp): NoTPFeedForward(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
)
(layer_norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(layer_norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
)
(pre_layrnorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(projector): MlpProjector(
(layers): Linear(in_features=2048, out_features=1280, bias=True)
)
)
(lm_head): Linear(in_features=1280, out_features=129280, bias=False)
)
DeepseekOCRConfig {
"_attn_implementation_autoset": true,
"_name_or_path": "/root/.cache/modelscope/hub/models/deepseek-ai/DeepSeek-OCR",
"architectures": [
"DeepseekOCRForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"auto_map": {
"AutoConfig": "modeling_deepseekocr.DeepseekOCRConfig",
"AutoModel": "modeling_deepseekocr.DeepseekOCRForCausalLM"
},
"aux_loss_alpha": 0.001,
"bos_token_id": 0,
"candidate_resolutions": [
[
1024,
1024
]
],
"eos_token_id": 1,
"ep_size": 1,
"first_k_dense_replace": 1,
"global_view_pos": "head",
"hidden_act": "silu",
"hidden_size": 1280,
"initializer_range": 0.02,
"intermediate_size": 6848,
"kv_lora_rank": null,
"language_config": {
"architectures": [
"DeepseekV2ForCausalLM"
],
"auto_map": {
"AutoConfig": "configuration_deepseekv2.DeepseekV2Config",
"AutoModel": "modeling_deepseek.DeepseekV2Model",
"AutoModelForCausalLM": "modeling_deepseek.DeepseekV2ForCausalLM"
},
"bos_token_id": 0,
"eos_token_id": 1,
"first_k_dense_replace": 1,
"hidden_size": 1280,
"intermediate_size": 6848,
"kv_lora_rank": null,
"lm_head": true,
"max_position_embeddings": 8192,
"moe_intermediate_size": 896,
"n_group": 1,
"n_routed_experts": 64,
"n_shared_experts": 2,
"num_attention_heads": 10,
"num_experts_per_tok": 6,
"num_hidden_layers": 12,
"num_key_value_heads": 10,
"q_lora_rank": null,
"qk_nope_head_dim": 0,
"qk_rope_head_dim": 0,
"rm_head": false,
"topk_group": 1,
"topk_method": "greedy",
"torch_dtype": "bfloat16",
"use_mla": false,
"v_head_dim": 0,
"vocab_size": 129280
},
"lm_head": true,
"max_position_embeddings": 8192,
"model_type": "DeepseekOCR",
"moe_intermediate_size": 896,
"moe_layer_freq": 1,
"n_group": 1,
"n_routed_experts": 64,
"n_shared_experts": 2,
"norm_topk_prob": false,
"num_attention_heads": 10,
"num_experts_per_tok": 6,
"num_hidden_layers": 12,
"num_key_value_heads": 10,
"pretraining_tp": 1,
"projector_config": {
"input_dim": 2048,
"model_type": "mlp_projector",
"n_embed": 1280,
"projector_type": "linear"
},
"q_lora_rank": null,
"qk_nope_head_dim": 0,
"qk_rope_head_dim": 0,
"rm_head": false,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 10000.0,
"routed_scaling_factor": 1.0,
"scoring_func": "softmax",
"seq_aux": true,
"tie_word_embeddings": false,
"tile_tag": "2D",
"topk_group": 1,
"topk_method": "greedy",
"torch_dtype": "bfloat16",
"transformers_version": "4.46.3",
"use_cache": true,
"use_mla": false,
"v_head_dim": 0,
"vision_config": {
"image_size": 1024,
"mlp_ratio": 3.7362,
"model_name": "deeplip_b_l",
"model_type": "vision",
"width": {
"clip-l-14-224": {
"heads": 16,
"image_size": 224,
"layers": 24,
"patch_size": 14,
"width": 1024
},
"sam_vit_b": {
"downsample_channels": [
512,
1024
],
"global_attn_indexes": [
2,
5,
8,
11
],
"heads": 12,
"layers": 12,
"width": 768
}
}
},
"vocab_size": 129280
}
# 设置参数
prompt = "<image>\n<|grounding|>Convert the document to markdown."
image_file = 'image.jpg'
output_path = 'output'
# 执行推理
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
test_compress=True
)
模型配置选项
| 配置名称 | base_size | image_size | crop_mode | 说明 |
|---|---|---|---|---|
| Tiny | 512 | 512 | False | 最小配置 |
| Small | 640 | 640 | False | 小型配置 |
| Base | 1024 | 1024 | False | 基础配置 |
| Large | 1280 | 1280 | False | 大型配置 |
| Gundam | 1024 | 640 | True | 推荐配置 |
提示词选项
# 基础 OCR
prompt = "<image>\nFree OCR."
# 转换为 Markdown(推荐)
prompt = "<image>\n<|grounding|>Convert the document to markdown."
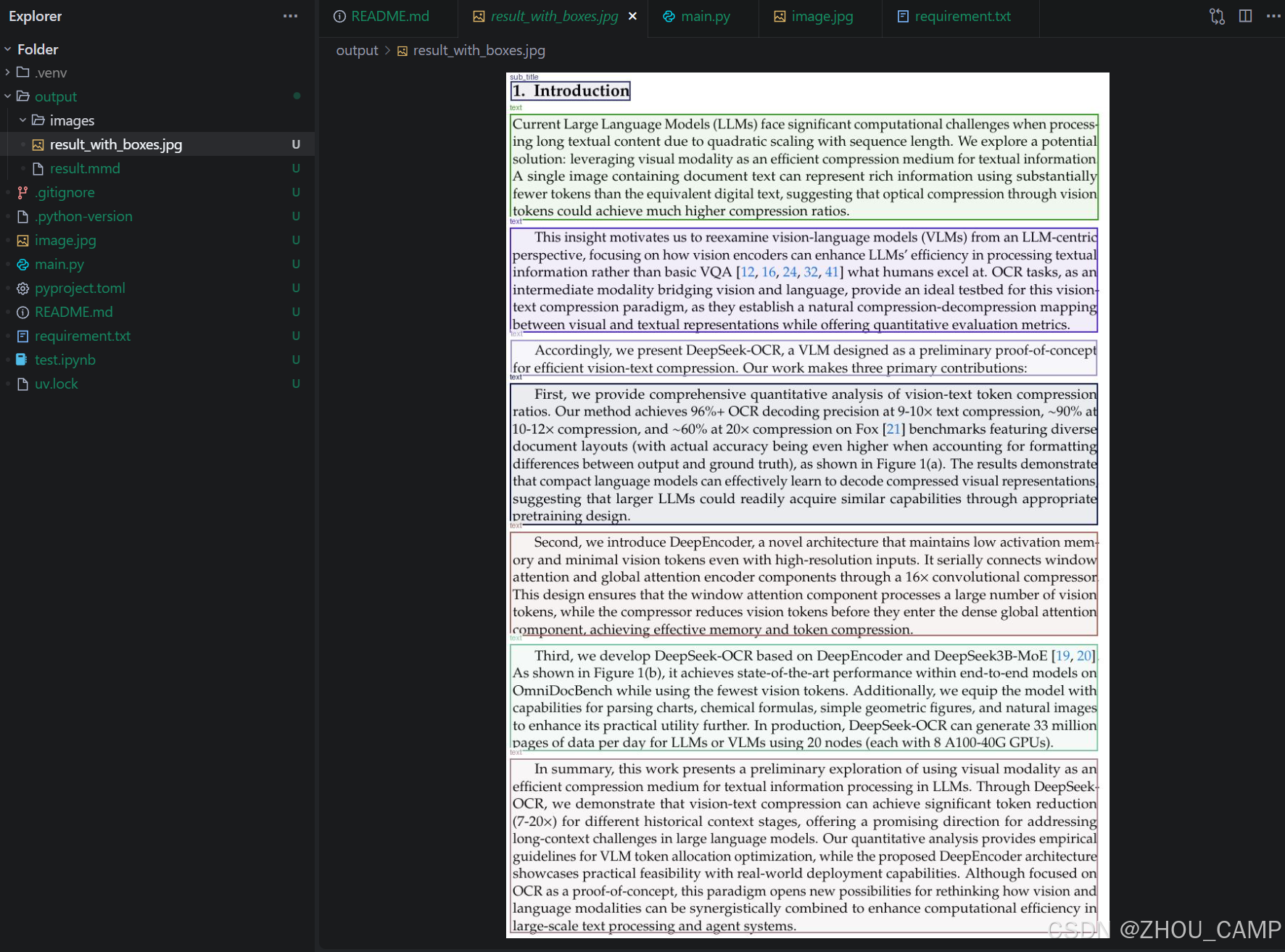
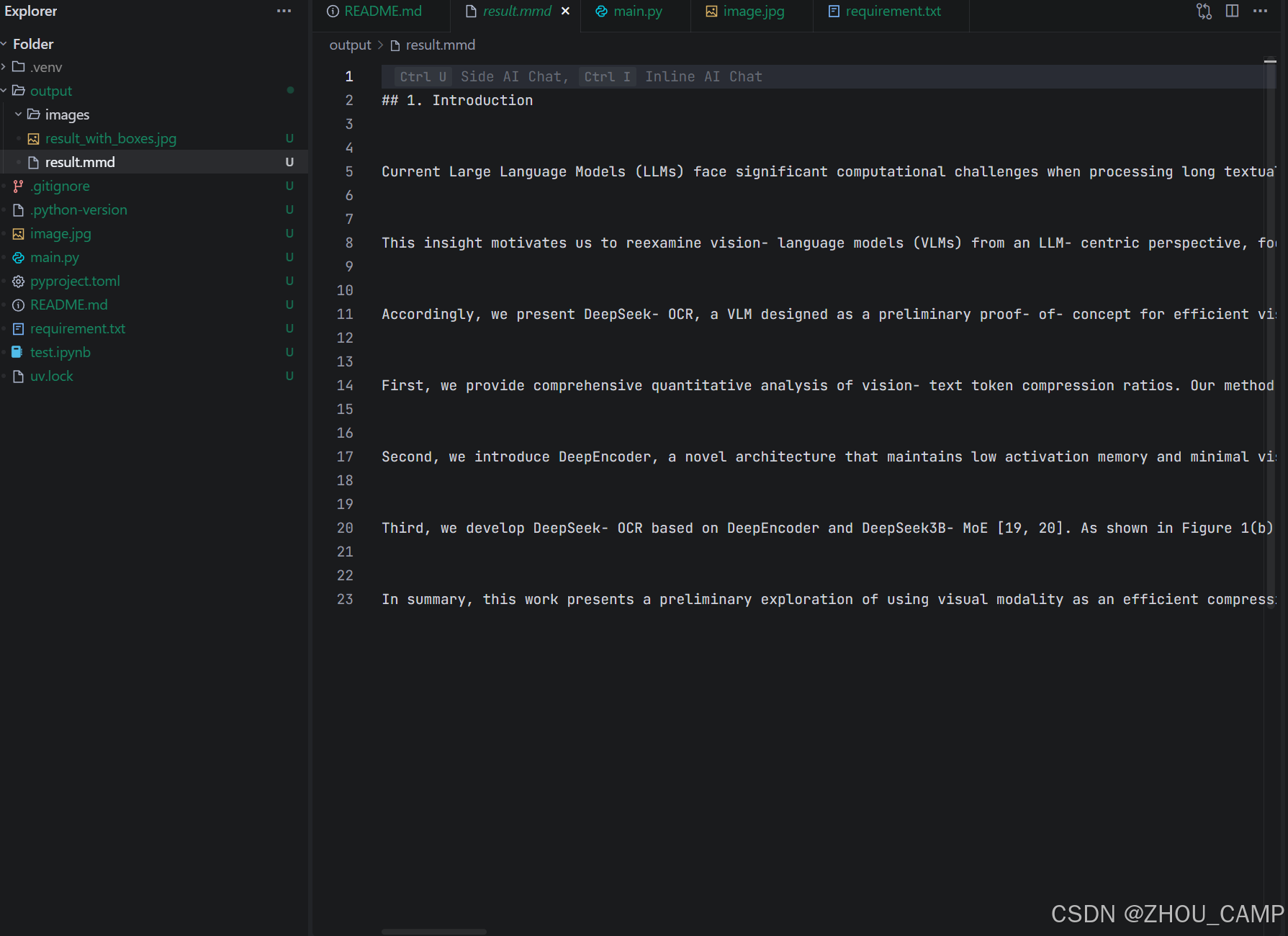
测试效果
测试图片:image.jpg

输出结果保存在 output/ 目录下:
result.mmd:Markdown 格式的识别结果result_with_boxes.jpg:带有识别框的图片


















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









