







 本文介绍了作者针对图像文本匹配提出的相似图推理(SGR)和相似注意过滤(SAF)技术,解决全局对齐、局部对齐表达及无意义对齐干扰问题。方法包括特征提取、图和文本表示学习,以及SGR与SAF模块的应用,实验结果展示了SAF的有效性,特别是对冠词等无意义词汇的过滤。
本文介绍了作者针对图像文本匹配提出的相似图推理(SGR)和相似注意过滤(SAF)技术,解决全局对齐、局部对齐表达及无意义对齐干扰问题。方法包括特征提取、图和文本表示学习,以及SGR与SAF模块的应用,实验结果展示了SAF的有效性,特别是对冠词等无意义词汇的过滤。
Similarity Reasoning and Filtration for Image-Text Matching
发表时间:2021
引用:Diao, Haiwen, et al. “Similarity reasoning and filtration for image-text matching.” arXiv preprint arXiv:2101.01368 (2021).
论文地址:https://openaccess.thecvf.com
代码地址:https://github.com/Paranioar/SGRAF
介绍
作者还是为了实现更为细粒度的对齐。虽然此前使用全局对齐或者局部对齐的方式已经取得了一些成效,但是作者认为,当下的模型方法还是存在三点问题:
- 大多方法使用标量的方法计算局部特征之间的相似性,也就是说会直接转换成一个数值,而数值是很难描述区域和单词之间的关联的
- 在计算完区域和单词之间的潜在对齐后,部分模型就直接用最大池化或者平均池化的方法计算出全局相似。无论是哪种方法,都会阻碍全局对齐和局部对齐之间的信息交流。(比如SCAN最后用的就是一个平均池化的方法: S A V G ( I , T ) = ∑ i = 1 k R ( v i , a i t ) k S_{AVG}(I,T)=\frac{\sum_{i=1}^{k}R(v_{i},a^{t}_{i})}{k} SAVG(I,T)=k∑i=1kR(vi,ait))
- 很少去考虑一些没有太大意义的对齐的干扰,比如下图中"a"和"in"和其他实例之间的关系
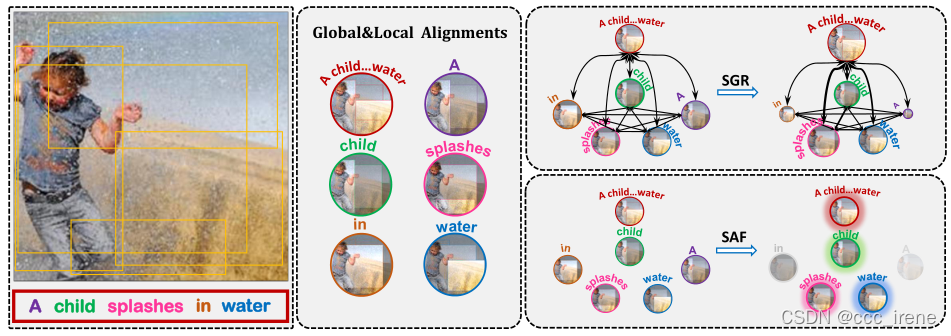
那么,为了解决上述三点问题,作者提出了一种相似图推理和注意过滤网络。具体来说:
- 首先捕捉整个图像和句子之间的全局对齐,以及图像区域和句子单词之间的局部对齐。在这里,使用基于向量的相似性表示来更有效地表示这种跨模态关联;
- 使用SGR相似图推理模块来捕捉局部对齐和全局对齐之间的关系,从而推理更为准确的图像文本相似性,在这里,SGR模块基于GCNN图卷积神经网络构成;
- 使用SAF相似性注意过滤模块来聚合所有具有不同显著性分数的对齐,从而减少无意义的干扰。
注意的是,这里不是说先用SGR再用SAF,也就是这两个模块没有先后顺序,作者进行实验的时候也是分模块进行的实验
方法
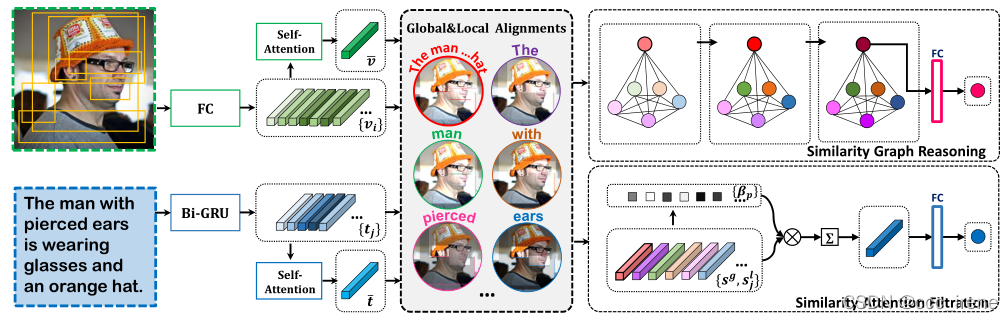
整体的模型结构如上所示,可以看到,经过特征提取后,就进行全局对齐和局部对齐,然后将对齐的结果分别进入SGR和SAF模块进行相似度的计算,这两个模块是独立的。那么下面也将分成四个部分进行说明重点说明。
特征提取
图特征提取
使用Faster RCNN提取图特征,添加一个全连接层转成d维向量,得到每个区域的表示 V = { v 1 , . . . , v k } V=\{v_{1},...,v_{k}\} V={ v1,...,vk},这里和SCAN是一致的。
然后,在每个区域上执行自注意力机制,该机制采用平均特征 q v ˉ = 1 K ∑ i = 1 K v i \bar{q_{v}}=\frac{1}{K}\sum_{i=1}^{K}v_{i} qvˉ=K1∑i=1Kvi作为查询并汇总所有区域以获得全局表示 v ˉ \bar{v} vˉ。代码对应部分如下:
class VisualSA(nn.Module):
def __init__(self, embed_dim, dropout_rate, num_region):
super(VisualSA, self).__init__()
self.embedding_local = nn.Sequential(nn.Linear(embed_dim, embed_dim),
nn.BatchNorm1d(num_region),
nn.Tanh(), nn.Dropout(dropout_rate))
self.embedding_global = nn.Sequential(nn.Linear(embed_dim, embed_dim),
nn.BatchNorm1d(embed_dim),
nn.Tanh(), nn.Dropout(dropout_rate))
self.embedding_common = nn.Sequential(nn.Linear(embed_dim, 1))
self.init_weights()
self.softmax = nn.Softmax(dim=1)
# local (batch, 36, d=1024)
# global (batch, d=1024)
def forward(self, local, raw_global):
# compute embedding of local regions and raw global image
l_emb = self.embedding_local(local)
g_emb = self.embedding_global(raw_global)
# compute the normalized weights, shape: (batch_size, 36)
g_emb = g_emb.unsqueeze(1).repeat(1, l_emb.size(1), 1)
common = l_emb.mul(g_emb)
weights = self.embedding_common(common).squeeze(2)
weights = self.softmax(weights)
# compute final image, shape: (batch_size, 1024)
new_global = (weights.unsqueeze(2) * local).sum(dim=1)
new_global = l2norm(new_global, dim=-1)
# new_global (shape, d=1024)
return new_global
文本特征提取
使用GRU提取文本特征,得到表示 T = { t 1 , . . . , t L } T=\{t_{1},...,t_{L}\} T={
t1,...,tL},按照同样的方式,得到文本的全局表示。这一部分在代码中体现在class TextSA(nn.Module)中
相似性表示学习
向量相似函数
之前说过,作者没有使用余弦距离或欧几里得距离来计算相似性标量,而是用的一个相似向量来表示不同模态之间的相似关联程度。那么在这里,作者就是用的如下函数:
s ( x , y ; W ) = W ∣ x − y ∣ 2 ∣ ∣ W ∣ x − y ∣ 2 ∣ ∣ 2 (1) s(x,y;W)=\frac{W|x-y|^{2}}{||W|x-y|^{2}||_{2}} \tag{1} s(x,y;W)=∣∣W∣x−y∣2∣∣2W∣x−y∣
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









