







Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval
论文引用:Chen, Hui, et al. “Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
时间:2020(CVPR)
论文链接:https://openaccess.thecvf.com/content_CVPR_2020/html/Chen_IMRAM_Iterative_Matching_With_Recurrent_Attention_Memory_for_Cross-Modal_Image-Text_CVPR_2020_paper.html
代码链接:https://github.com/HuiChen24/IMRAM
介绍
作者考虑到文本是由不同含义的不同种类的语义概念构成的,比如有对象、属性和关系等,而不同概念之间通常又存在着很强的相关性,比如说动词会经常性地用来表示不同对象之间的关系等等。并且,人们经常遵循一种潜在结构(如树状结构等)将不同的语义概念组合成可理解的语言。但这些是以往模型都没有考虑到的点,它们会平等地对待不同种类的语义,那么作者在这里就考虑到了不同语义之间的复杂性,并对此进行研究。
人在进行图文匹配的时候,会优先看低级语义概念,再看高级语义概念。受此启发,作者提出一种迭代匹配与重复注意记忆方法,使用多步对齐来捕获图像和文本之间的对应关系。也就是结合跨膜态注意单元和记忆提取单元来细化图像和文本之间的对应关系。
模型
整体结构如下图所示:
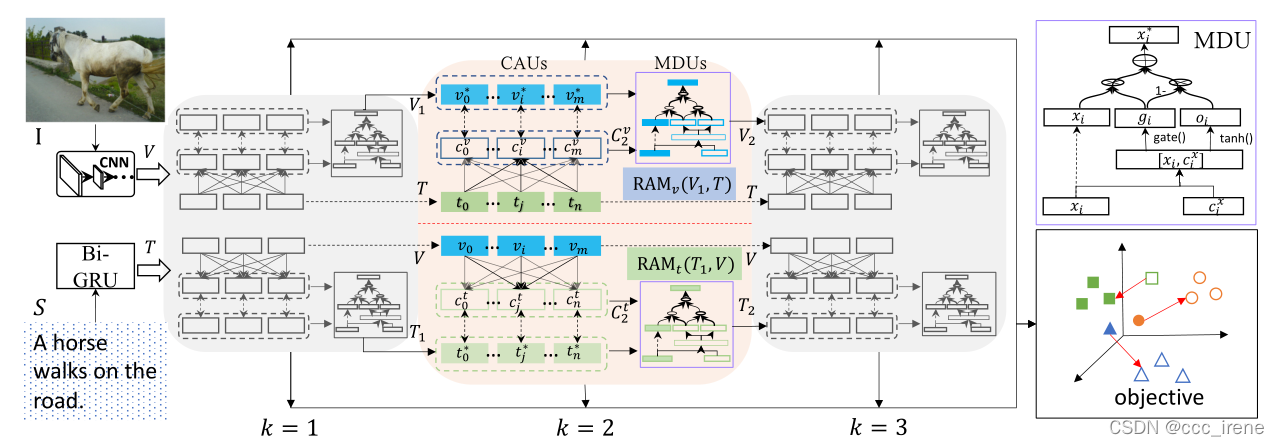
总的分为以下几步:
- 描述学习跨模态特征表示方法
- 使用重复注意记忆模块
- 形成最终的损失函数
跨膜态特征表示
这边的话对于图像和文本与此前的论文一致,图像Faster-RCNN,文本双向GRU
RAM:重复记忆模块
这个模块以循环的方式提炼关于先前片段对齐的知识来达到对齐嵌入空间的片段的目的。也就是说对于给定的两组特征点V和T,使用RAM来计算它们之间的相似度,他又分成CAU、MDU和RAM Block这样三个子块
CAU:跨膜态注意单元
现在给定两组特征点 X = { x 1 , . . . , x m ′ } X=\{x_{1},...,x_{m^{'}}\} X={ x1,...,xm′}和 Y = { y 1 , . . . , y n ′ } Y=\{y_{1},...,y_{n^{'}}\} Y={ y1,...,yn′}
CAU用于为X中的每一个 x i x_{i} xi特征总结Y中的上下文信息,具体来说,分为以下几点:
- 首先计算每队 ( x i , y j ) (x_{i},y_{j}) (xi,yj)之间的相似度并归一化,(这里与SCAN一致): z i j = x i T y j ∥ x i ∥ ∥ y j ∥ z_{ij}=\frac{x_{i}^{T}y_{j}}{\left \| x_{i}\right \|\left \| y_{j}\right \|} zij=∥xi∥∥yj∥xiTyj, z i j ˉ = r e l u ( z i j ) ∑ i = 1 m ′ r e l u ( z i j ) 2 \bar{z_{ij}}=\frac{relu(z_{ij})}{\sqrt{\sum_{i=1}^{m^{'}}relu(z_{ij})^{2}}} zijˉ=∑i=1m′r
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









