






 本文详细介绍了几种常见的排序算法,包括冒泡排序、快速排序、归并排序和堆排序。针对每种排序算法,讲解了其基本思想、适用场景、优缺点以及算法分析。特别提到了快速排序的优化策略——随机选取基准值,以及V8引擎的sort排序原理,强调了Timsort在实际应用中的高效性。
本文详细介绍了几种常见的排序算法,包括冒泡排序、快速排序、归并排序和堆排序。针对每种排序算法,讲解了其基本思想、适用场景、优缺点以及算法分析。特别提到了快速排序的优化策略——随机选取基准值,以及V8引擎的sort排序原理,强调了Timsort在实际应用中的高效性。
文章目录
排序算法
| 类别 | 排序方法 | 说明 |
|---|---|---|
| 插入排序 | 直接插入排序 | **适合原本就有序(顺序)和短数组** |
| 交换排序 | 冒泡排序 | 适合本身就有序的(正序) |
| 快速排序 | 不适合本身有序的数组,如果本身就有序就会退化成冒泡排序 | |
| 选择排序 | 简单选择排序 | 与初始状态无关 |
| 堆排序 | 与初始状态无关,非常稳定,适合元素个数比较多 | |
| 归并排序 | **与初始状态无关** | |
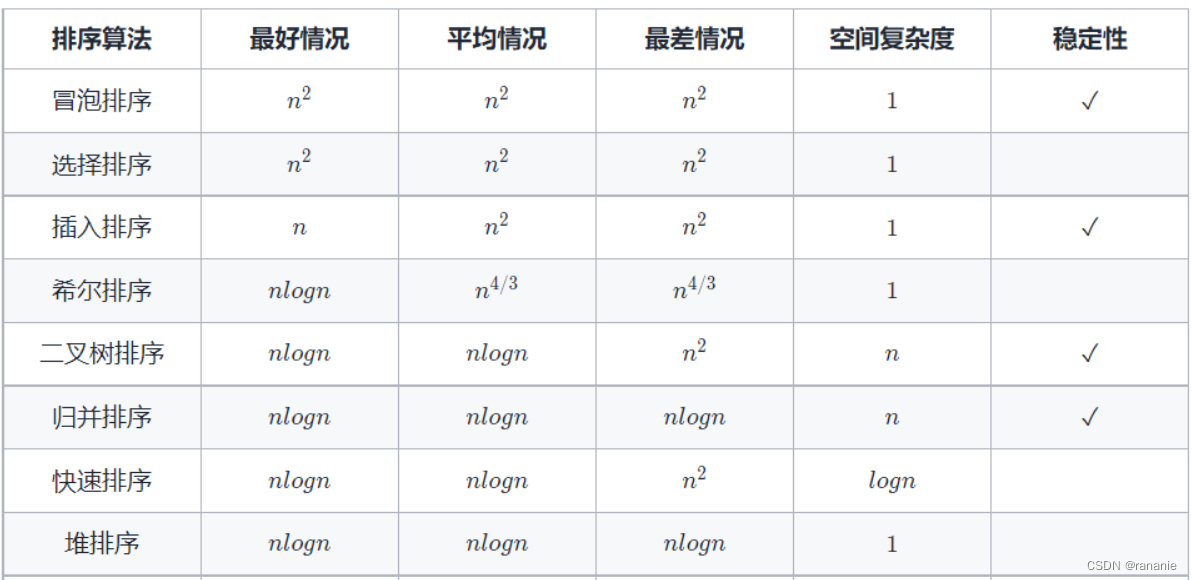
交换算法
基本思想:两两比较,如果发生逆序则交换,直到所有记录都排好序位置
冒泡排序 - 交换算法 适合本身有序
基于简单交换思想
基本思想:每趟不断将记录两两比较,并按"前小后大"规则交换。
每一躺确定一个最大的元素,所以n个元素需要n-1躺。
每一趟比较的次数 = n - 趟数。
如果某一趟比较时不出现记录交换,说明已经排好序了,可以提前结束了
优点
每趟结束时,不仅能让最大值找到位置,还能同时部分理顺其他元素。
function bubble(nums){
let n = nums.length;
for(let i=1;i<n;++i){ //趟数
let flag = false;//false表示没有发生交换,true表示发生了交换,每一趟开始先置false
for(let j=0;j<n-i;j++){//每一趟比较的次数,因为选择nums的元素,所以让j从0开始
if(nums[j]>nums[j+1]){//发生逆序则交换
[nums[j],nums[j+1]]=[nums[j+1],nums[j]];
flag = true;
}
}
//一趟结束了
if(!flag) return nums; //如果某一趟没有元素交换,说明已经排好序了。
}
return nums;
}
算法分析
最好情况(正序)
比较次数:n-1
移动次数:0
最坏情况(逆序)
比较次数:1+2+…n-1
移动次数:3(比较次数)
最好时间复杂度:O(n)
最坏时间复杂度:O(n^2)
平均时间复杂度:O(n^2)
适合本身就有序的(正序)
快速排序 - 交换算法 不适合本身有序
基本快排
思路
- 选择数组中一个元素(如第一个)为基准值pivotkey
- 开始寻找基准值最终的位置,比基准值小的放前面,比基准值大的放后面。最终就是基准值的位置,并且基准值将数组分为左右两个子表。(小 中 大)
- 左表和右表分别再执行1,2步。
- 直到每一个子表只剩下一个元素。
通过一趟排序,将排序的数组分隔成了两个部分,基准元素也找到最终的位置。
一个n个元素,那么就需要n-1趟。
采用递归的思想实现
1.递归的参数、返回值和停止递归的条件
一般采用左右边界的方法来对数组进行区间划分。
所以我们需要知道数组、左右边界。
我们通过在数组中交换元素进行排序,所以修改了数组本身的值,不需要返回值。
递归的终止条件是子表只有一个元素时,停止。
function qSort(nums,left,right){
//递归终止条件 为什么不是left=right,考虑基准值在边界的情况,那么下一次的left就会小于right
if(left>=right) return;
}
2.本层递归逻辑
寻找基准值的位置,根据基准值分为左右两个部分,左右那部分继续排序
function qSort(nums,left,right){
if(left<right){
let index = partiton(nums,left,right);//寻找基准值的位置
qSort(nums,left,index-1);//左表排序
qSort(nums,index+1,right);//右表排序
}
}
function partiton(nums,left,right){
let pivotkey = nums[left]; //假设数组的第一个元素为基准点
while(left<right){
//右边的指针先行,如果找到比基准点小的就可以去覆盖左边指针位置的值,而左边指针位置的值就是我们的基准点,已经被存起来了
while(left<right && nums[right]>=pivotkey)right--;
nums[left]=nums[right];
while(left<right && nums[left]<=pivotkey)left++;
nums[right]=nums[left]
}
//退出循环说明找到了
nums[left] = pivotkey;
return left;
}
优化:随机基准值的快排
基本快排的问题:不适合本身有序的数组,如果本身就有序就会退化成冒泡排序
通过随机选取基准值,可以降低初始顺序对快速排序效率的影响。
1.随机选取一个下标
1.1 范围在[left,right]之间,需要生成[left,right]之间的随机整数
2.该下标的值与第一个元素进行交换,就可以开始寻找基准值的位置了。
需要生成[left,right]之间的随机整数
Math.random() 随机 返回[0,1)随机数
Math.random()*(right-left+1) //[0,5)的随机数
Math.floor(Math.random()*(right-left+1)) //[0,5)的随机整数
left+Math.floor(Math.random()*(right-left+1)) //[2,7)的随机整数
随机基准值选取
let randomIndex = left+Math.floor(Math.random()*(right-left+1)) ;
[nums[randomIndex],nums[left]] = [nums[left],nums[randomIndex]];
let pivotkey = nums[left];
完整代码
function sortArray(nums: number[]): number[] {
let len = nums.length;
if(len==1)return nums;
qSort(nums,0,len-1);
return nums;
};
function qSort(nums,left,right){
if(left<right){
let index = partiton(nums,left,right);//寻找基准值的位置
qSort(nums,left,index-1);//左表排序
qSort(nums,index+1,right);//右表排序
}
}
function partiton(nums,left,right){
let randomIndex = left+Math.floor((Math.random()*(right-left+1))) ;
[nums[randomIndex],nums[left]] = [nums[left],nums[randomIndex]];
let pivotkey = nums[left];
while(left<right){
while(left<right && nums[right]>=pivotkey)right--;
nums[left]=nums[right];
while(left<right && nums[left]<=pivotkey)left++;
nums[right]=nums[left]
}
//退出循环说明找到了
nums[left] = pivotkey;
return left;
}
算法分析
- 时间复杂度 O(nlogn)
- QSort()递归的深度使logn:O(logn)
- partiton():O(n)
- 空间复杂度 O(logn)
快速排序不适合对原本有序或基本有序的记录序列进行排序
划分元素的选取是影响时间性能的关键。
归并排序 与初始状态无关
当我们需要排序一个数组时,先将数组分成一半,想办法把左边的数组给排序,右边的数组给排序,之后再将它们归并起来。那现在对数组的排序就变成了对左边数组的排序和右边数组的排序。
当然了当我们对左边的数组和右边的素组进行排序的时候,再分别将左边的数组和右边的数组分成一半,然后对每一个部分归并。
什么时候停止递归,只有一个元素时已经有序了,就不用再排序了,直接归并就好了。
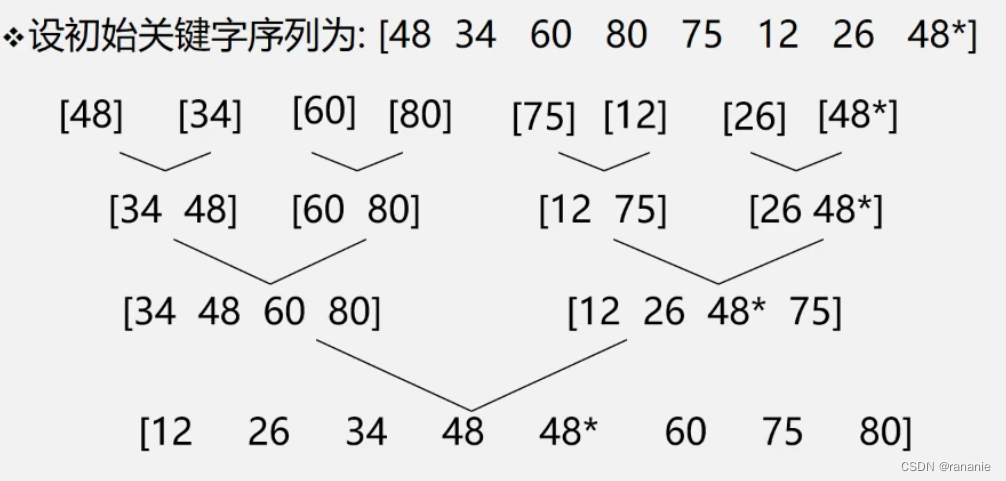
这个思路不就是递归的思路吗!归并的过程就是在递归。
递归三部曲
递归的参数和返回值
直接对原数组nums进行修改
参数需要原数组和两个划分区间的指针left、right
function merge (let nums,let left,let right){
}
递归的终止条件
只有一个元素时,自然就是有序的,不需要在进行划分了
if(left==right) return;
本层递归逻辑
本层递归需要把有序的两个部分合并成有序的一个部分。
function merge (nums,left,right){
if(left==right) return;
let mid = (left+right)>>1; //除以2的操作
merge(nums,left,mid); //左边的有序数组
merge(nums,mid+1,right);//右边的有序数组
//优化:如果此时已经有序了,就不用在进行有序合并了
if(nums[mid]<=nums[mid+1])return;
//对左边和右边数组进行排序合
mergeSort(nums,left,mid,right);
return nums;
}
//两个数组进行排序
function mergeSort(nums,left,mid,right){
let l =left;
let r = mid+1;
let k = 0;
let arr = new Array(right-left+1); //记录排好序的结果
while(l<=mid && r<=right){
if(nums[l]<=nums[r]) arr[k++] = nums[l++];
else arr[k++] = nums[r++];
}
while(l<=mid){
arr[k++] = nums[l++];
}
while(r<=right){
arr[k++] = nums[r++];
}
for(let i=0;i<arr.length;i++){ //新数组覆盖老数组
nums[left+i] = arr[i];
}
}
算法分析
- 时间复杂度:O(NlogN),这里 N 是数组的长度;
- 空间复杂度:O(N),辅助数组与输入数组规模相当
选择排序
基本思想:在待排序的数组中选出最大/小的元素放在最终位置
简单选择排序
- 首先通过n-1次关键字比较,从n个记录中找出关键字最小的数,将它与第一个数交换
- .在通过n-2次比较,从剩余的n-1个记录中找出关键字最小的数,与第二个数交换
- 重复上述操作,共进行n-1躺排序后(因为每躺排序好一个元素),排序结束。
function simpleChoice(arr){
let min = 0;
for(let i=0;i<arr.length;++i){ //躺数
min = i ; //初始化最小值的下标,i左边的已经排好序了
for(let j=i+1;j<arr.length;++j){//比较次数
if(arr[min]>arr[j])min=j;
}
if(i!=min)[arr[min],arr[i]]=[arr[i],arr[min]]
}
return arr;
}
//测试代码
console.log(simpleChoice([3,2,3,1,2,4,5,5,6]));
堆排序
堆排序很稳定,不管正序逆序(与初始状态无关),最好最坏时间复杂度都是O(nlogn)
堆的介绍

堆实质使满足: 二叉树中任意非叶子结点均小于(大于)它的孩子节点的 完全二叉树(除叶子节点都每一层都满,叶子节点从左到右填充)
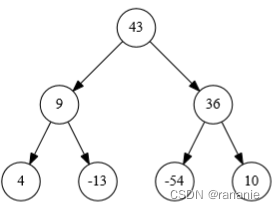
在大根堆/小根堆中堆顶是最大值(最小值),输出堆顶元素后,调整堆,依次输出堆顶就是排好序的。
所以堆排序需要解决两个问题:
- 如何由一个无序序列建成一个堆?
- 如何输出堆顶元素后,调整剩余元素为新堆
调整新堆
以大根堆为例
需要调整的下标:index
需要调整的元素左孩子节点:index*2+1 (数组下标从0开始)
带排序的最后一个元素下标:end
输出堆顶元素后,以堆中待排序的最后一个元素下标为index作为新的根,通过调整该元素,使得剩余的元素成为新堆。
具体的思路就是:从二叉树中进行选边
function adjust(nums,index,end){
//左孩子节点不是最后一个元素,需要调整到最后一个元素为止
while(2*index+1<=end){
//选择排序就是找出最大/最小值,所以需要开始从左孩子节点寻找
let max = 2*index+1; //初始化最大值下标
//如果右孩子节点存在,且右孩子>左孩子,那么max记录右孩子
if(max+1<=end && nums[max]<nums[max+1])max++;
/*
此时max记录的左右孩子中的最大值
如果父节点更大,直接退出,调整完毕
*/
if(nums[index]>nums[max]) break;
//说明没有调整结束,大的孩子节点作为根节点
[nums[max],nums[index]]=[nums[index],nums[max]];
index =max;//沿key大的孩子节点向下筛选
}
}
建堆
创建堆就是一个返回筛选创建堆的过程
在完全二叉树中,叶子节点是堆,所以叶子节点不用调整,从第一个非叶子节点开始调整。
最后一个元素下标为n,所以第一个非叶子节点的坐标为Math.floor(n-1/2)。只需要依次以序号Math.floor(n-1/2) ......0的节点为根的子树进行调整成堆。
function heapify(nums){
let n = nums.length-1;
for(let i=(n-1)/2;i>=0;--i){
adjust(nums,i,n-1);
}
}
堆排序
function heapSort(nums){
//建堆
let n = nums.length-1;
for(let i=Math.floor((n-1)/2);i>=0;--i){
adjust(nums,i,n);
}
//输出栈顶元素,根与最后一个待排序元素元素i交换,大根堆,交换之后最后一个元素最大,输出是从小到大
for(let i=n;i>0;i--){ //只有0号元素不调整
[nums[i],nums[0]] = [nums[0],nums[i]];//交换之后.重新调整成堆
//此时下标i的是已经有序的,最后一个待排序的为i-1
adjust(nums,0,i-1);
}
return nums;
}
function adjust(nums,index,end){
//左孩子节点不是最后一个元素,需要调整到最后一个元素为止
while(2*index+1<=end){
//选择排序就是找出最大/最小值,所以需要开始从左孩子节点寻找
let max = 2*index+1; //初始化最大值下标
//如果右孩子节点存在,且右孩子>左孩子,那么max记录右孩子
if(max+1<=end && nums[max]<nums[max+1])max++;
/*
此时max记录的左右孩子中的最大值
如果父节点更大,直接退出,用于建堆时
*/
if(nums[index]>nums[max]) break;
//说明没有调整结束,大的孩子节点作为根节点
[nums[max],nums[index]]=[nums[index],nums[max]];
index =max;//沿key大的孩子节点向下筛选
}
}
//测试
console.log(heapSort([3,2,3,1,2,4,5,5,6]));
插入排序
基本思想(类似扑克牌):每步将一个待排序的对象,按其大小插入到前面已经排好序的数组中的适当位置,直到对象全部插入为止。
边插入边排序,保证子序列中随时都是排好序的。

如何找到插入位置?根据寻找插入位置的不同,将插入排序分成3类
- 顺序法定位插入位置:直接插入排序
- 二分法定位插入位置: 二分插入排序
- 缩小增量多遍插入顺序:希尔排序
直接插入排序
当前需要排序的位置是i,先将这个位置存起来,因为之后找到位置后,可能其他元素需要后移。
需要在[0,i-1]有序数组中寻找,这里从后往前找,可以边找边移动。
function sort(nums){
for(let i=1;i<nums.length;i++){ //有n-1需要排序
let cur = nums[i];
for(let j=i-1;j>=0;j--){ //从后往前找,从小到大排序
if(cur>=nums[j]) break;
else{
nums[j+1] = nums[j];//元素后移
nums[j] = cur;
}
}
}
return nums;
}
最好的情况,从小到大有序(顺序)
- 比较的次数:n个元素排序,n-1个需要和前面有序的进行比较
- 移动次数:0
提高查找速度
- 减少元素的比较次数
- 减少元素的移动次数
适用场景
1.基本有序
2.数组较短
希尔排序

基本思想
将整个待排记录序列分割成若干子序列,分别进行直接插入排序,待整个序列中的记录基本有序,再对全体记录进行一次插入排序
特点
- 缩小增量,增量序列递减,最后以一个必须是1,- - 也就是对全体记录进行一次插入排序
- 多遍插入排序
- 一次移动,移动位置较大,跳跃式地接近排序后的最终位置
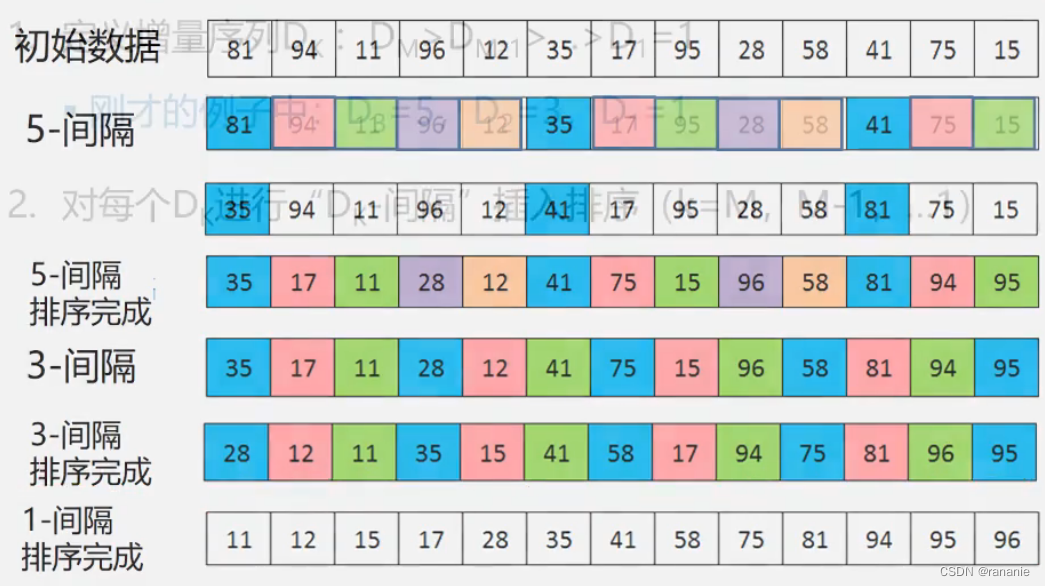
1.选择增量序列 D3=5,D2=3,D1=1
2.进行DK-间隔插入排序,每隔DK个的元素一起进行排序
算法分析
希尔排序算法效率与增量序列的取值有关
是不稳定的排序算法
V8引擎sort排序的原理
根据数组长度来选择具体的方法
- 数组长度小于10时使用插入排序
- 数组长度大于10时,采用
混合排序的算法TimSort,在数据量小的子数组中使用插入排序,然后再使用归并排序将有序的子数组进行合并排序 。
思路
Timsort 会遍历所有数据,找出数据中所有有序的分区(run),然后按照一定的规则将这些分区(run)归并为一个。本质是利用现实数据集中存在者大量的有序元素
具体过程
- 扫描数组,并寻找所谓的 runs ,一个 run 可以认为是已经排序的小数组,也包括以逆向排序的,因为这些数组可以简单地翻转就成为一个run。假设有序子数组长度为
currentRunLength - 计算最小合并序列长度
minRunLength(这个值是变化的),currentRunLength<minRunLength的 run 会通过 插入排序 补足长度到minRunLength。 - 反复归并一些相邻 长度满足条件的run,过程中避免归并长度相差很大的片段,直至整个排序完成
如何避免归并长度相差很大 run 呢?
在 Timsort 排序过程中,会存在一个栈用于记录每个 run 的起始索引位置与长度, 依次将 run 压入栈中,若栈顶 A 、B、C 的长度 |C| > |B| + |A| |B| < |A| 合并A+B
需要保证栈内任意 3 个连续的 run(run0, run1, run2)从下至上满足run0 > run1 + run2 && run1 > run2 ,不满足的话进行调整直至满足(下面的最大,中间的第二大)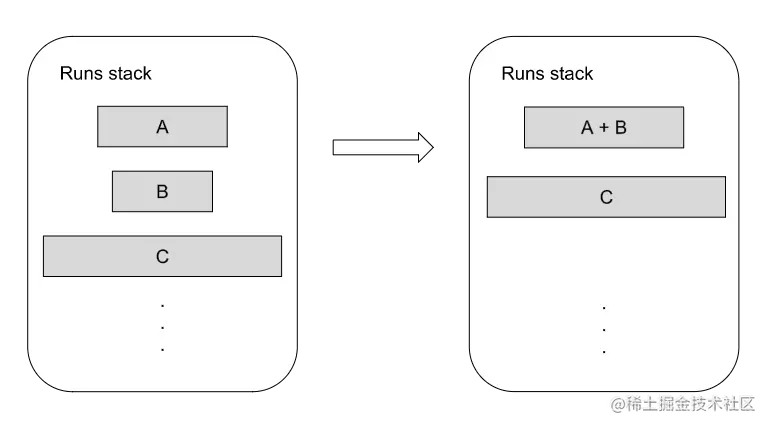 时间复杂度分析对于已经排序好的数组,会以
时间复杂度分析对于已经排序好的数组,会以 O(n) 的时间内完成排序,因为不需要合并操作。
最坏的情况是 O(n log n) 。

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









