




一、ollama
1.1 docker 方式
1.1.1 ollama启动
(1)拉取镜像
docker pull ollama/ollama
(2)启动
docker run -d --restart=always --gpus=all -v /home/docker/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# -v 是存储挂载,之后你使用ollama下载的模型权重都会保存早本地/home/docker/ollama路径下
(3)启动完成后,您可以通过访问 http://<您的IP地址>:11434/api/tags 来查看当前已下载的大模型列表。同时,通过访问 http://<您的IP地址>:11434/api/version 可以获取当前安装的 Ollama 版本信息。
请注意:
- 在上述 URL 中,请将 <您的IP地址> 替换为您实际的服务器 IP 地址或域名。
- 对于 Ollama 0.3.0 及以上版本,用户能够配置更多的高级选项,如多并发处理能力和模型后台运行的最大时长等。这些功能可以通过执行特定的命令来实现。
curl http://ip:11434/api/generate -d '{"model":"qwen2:7b","keep_alive": -1}'
# 将qwen2:7b模型一直保持在后台
1.1.2 Open WebUI
(1)拉取 Open WebUI 镜像
docker pull openwebui/open-webui
(2)运行 Open WebUI 服务
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
(3)访问 Open WebUI
打开浏览器,访问 http://ip:8080就能打开以上页面了。
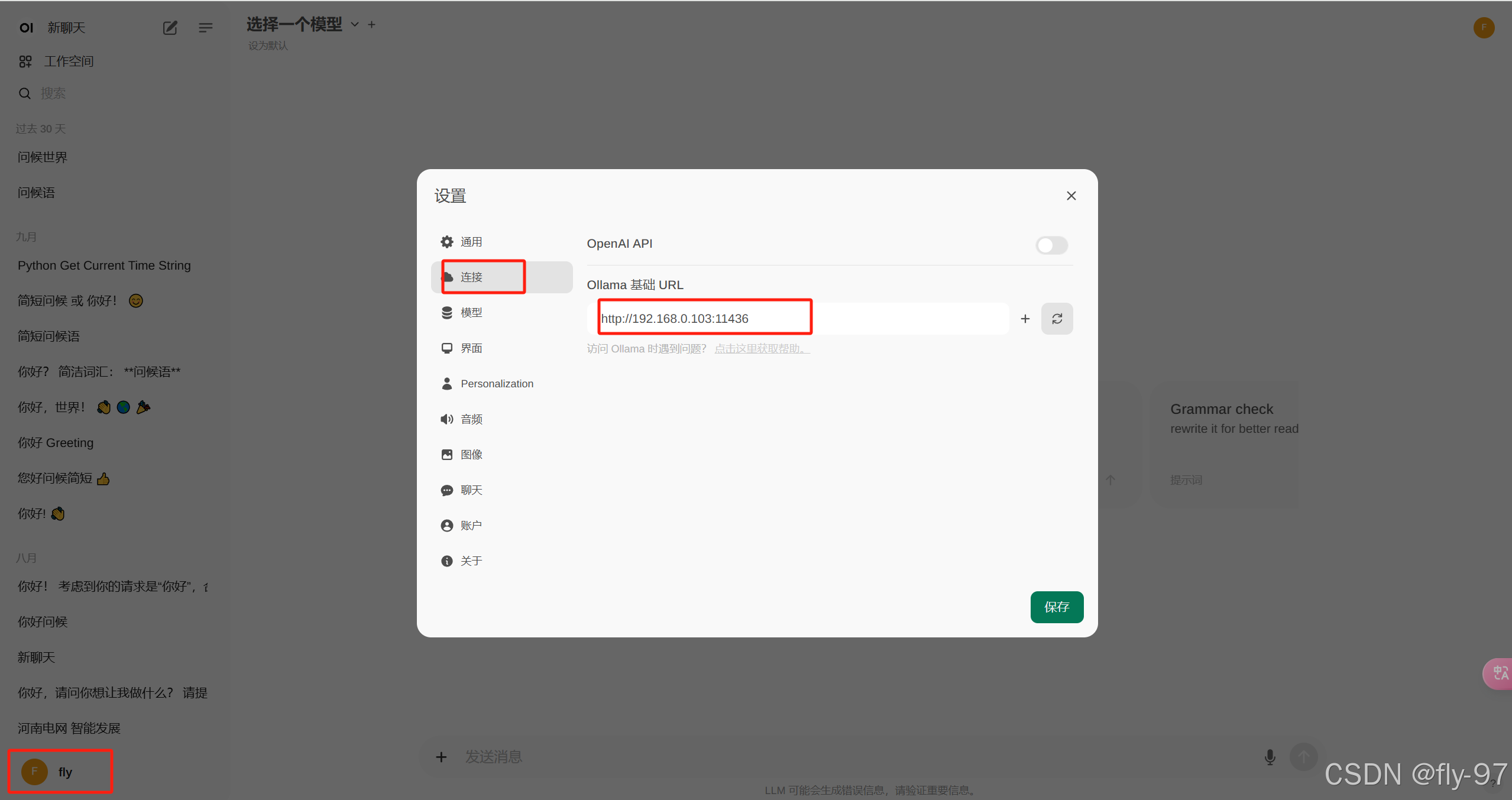
这个是配置刚刚ollama的服务,保存之后就可以在下面的模型模块看到已有的模型
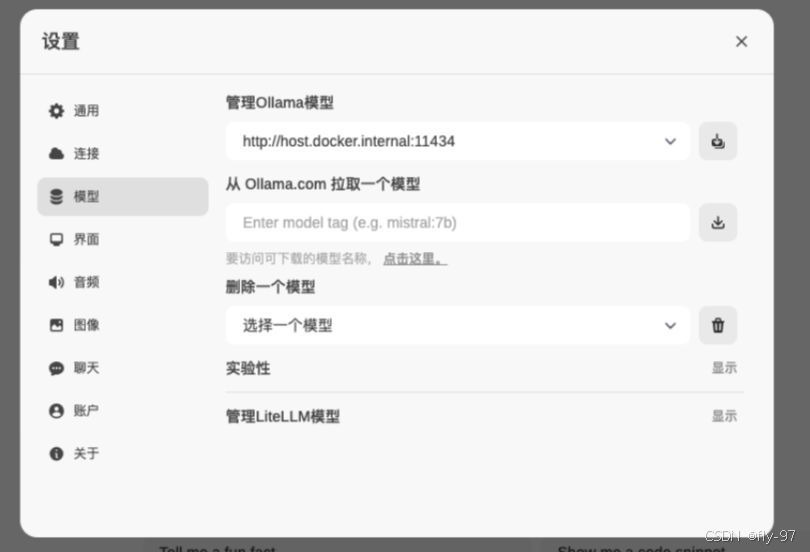
在模型管理模块中,您可以下载所需的模型(请注意,模型名称必须准确无误)。为了方便查找和选择合适的模型,您可以访问 Ollama 模型库。
完成模型下载后,您就可以开始与模型进行对话了。如果您想探索更多功能,建议搜索有关 Open WebUI 的使用教程,那里有详细的指南和技巧可以帮助您更好地利用这一工具。
二、huggingface、modelscope
2.1 huggingface方式
Hugging Face 是一个非常流行的开源平台,提供了大量的预训练模型和工具,使得开发者和研究人员可以轻松地使用和微调各种深度学习模型。本文将介绍如何在 Hugging Face 上运行大模型,并提供一些实用的技巧和注意事项。
前提条件:
(1)Python:建议使用 Python 3.7 或更高版本。
(2)Transformers 库:这是 Hugging Face 提供的核心库,包含了大量预训练模型。
(3)Torch 或 TensorFlow:根据您的需求选择其中一个深度学习框架。
由于官网需要科学上网的方式才能访问,所以推荐使用国内的镜像 https://hf-mirror.com
对应的每个大模型下都会有如何调用的方法:

代码默认的是使用官网下载大模型,我们可以直接使用以上的镜像网址在网页上进行下载
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1852
1852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









