






1.Introduction
时序异常检测几个可以运用的点:1.欺诈检测 2.工业数据检测
简介一下:异常检测很久之前就有了 最早可以追溯到. J. Fox. 1972. Outliers in Time Series. Journal of the Royal Statistical Society: Series B (Methodological) 34, 3 (1972), 350–363.
后来经过一段时间的混乱发展时期,现在已经发展基本成熟。离群点 和相关的概念确定的经典作品是 M. Hawkins. 1980. Identification of outliers. Springer Netherlands, New York.
一种与其他观测结果偏离甚大的观测结果,从而引起怀疑,认为它是由不同的机制产生的
通常可以将异常的含义分为两类:(其实就是拿到数据的作用不同,也就是基于我们分析的目的不同)

一类是废物数据,需要我们进行数据清洗 例如在调查普通国民平均收入的时候我们使用这种技术来排除马云等人的工资,得出普通老百姓的工资
一类是有用的数据,是我们分析的数据 例如我们在调查贪官的时候,我们得到国民的平均收入之后,可能就要特别关注那些 收入很高的人 看看有没有贪官
2. A TAXONOMY OF OUTLIER DETECTION TECHNIQUES IN THE TIME SERIES CONTEXT

分类方式如上图 虽然这篇文章发表自ACM 但是我还是觉得这种分法有点奇怪。。。、
Outlier type:(大家可能对 subsequence 和 time series 产生一定的误解)
1.点离群点是指在特定时间瞬间与时间序列中的其他值(全局离群点)或与其相邻点(局部离群点)进行比较时,表现异常的基准)。 可以使一个或多个时间变量组成
2.子序列异常值。 是指在一段时间内的部分时间点出现的异常

3.而时间序列异常:整个时间序列也可以是异常值,但只有当输入数据是多元时间序列时才能检测到它们

3. Point Outliers
这部分介绍分为单元 和 多元 就像上图锁分类的一样 特别的是否含有时序信息也将作为重要的影响因素被考虑在内(评判标准:是否可以实时处理数据)
3.1 单一变量时间序列


Estimation models :
1、基于常数或分段常数模型 例如获取数据的中位数 并用来作为 xˆt
2. 另一种方法就是识别不太符合模型的数据点 例如使用GMM 比较常见的几种方法就是 建立最大和最小的可能区间,设立一个阈值 或者是 分析多种模型的残差
Predict models:
1. 把任务当成了一个单纯的预测任务 使用各种方法来预测
2.考虑时间因素 例如使用滑动窗口的方式不断的预测和使用
3. extreme value theory 使用我们预测过的数据进行 retrain 我们给出一个固定的风险 q 如果 Xt > q 我们就重新确定 q , 就算会导致 q 会忽上忽下
其中一些基于预测的方法周期性地重新训练底层模型,或者每次新的点到达时。 因此,它们可以适应数据的演变。 然而,它们中没有一个应用增量模型学习方法,其中模型不是每次从零开始重建,而是使用接收到的新信息进行增量更新
Density-based
通常的判断方法为

d通常表示为欧式距离 , xt 需要被分析的数据 X 为 一系列的数据点 如果是一个estimation 的问题的的话 xt 就需要和 前后的进行估计并且让他们的和小于 τ 则为 异常点
局域密度的方法通常用于非时期数据中,因为它更急倾向于领域的时间关系
缺点:不同的time step 可能会导致出现对同一点的不同判断
Histogramming
这种方法是基于移除点之后误差比原始值更低来实现的
3.2多变量的时间预测
3.2.1 含有多个时序有关的变量 但是不考虑这些变量之间的关系 最著名的就是LSTM
但是 单一时间变量会导致信息的损失 如何解决这个问题
--> 通过将这些元素进行预处理使得其变为 非相关变量
这些方法一般 都是通过降维来实现的
其中一些降维技术是基于通过计算初始变量的线性组合来找到新的不相关变量集 例如:PCA 等等
其他技术将输入的多元时间序列减少为一个单一的时间相关变量,而不是一组不相关的变量

3.2.2 多变量处理的时序异常检测
这个部分和之前的不一样的地方在于 不使用预先编码的数据而是直接使用数据进行处理

同样的 在estimation model 中 auto-encoder(一种神经网络,它只学习作为正常参考的训练集的最重要特征,异常点通常与这些点没有直接的关系,所以会无法reconstruct) 是最常用的模型
上述公式(4) 是适用于prediction model-based 这一类别中的技术也将模型与多元时间序列相匹配,但期望值是根据过去的价值对未来作出的预测
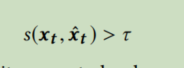
测量两个多元点之间的差异,这些方法通常不直接使用原始数据,而是使用不同的表示方法。
例如:用一个图表示数据,其中节点是序列的多元点,边是用径向基函数(RBF)计算的它们之间的相似度值)。
通过将在与向量相同的时间戳处收集的测量值处理到多元时间序列。 与单变量情况类似,该方法旨在检测应该删除的向量,以便改进剩余数据的压缩表示(直方图。 作者提出了一种流系列和非流系列的算法来寻找近似最优偏差。
4.子序列异常
一般情况下异常是一系列的点

首先,子序列由一组点组成,而不是由一个点组成,因此它们有一定的长度。通常采用固定长度。
其次就是损失函数的定义 相对一个点来说一个序列的损失函数更加难以定义。
最后就是输入输出的形式非常的受限制
周期子序列也是一个很重要的问题但是很少有人研究
4.1 单变量的子序列异常检测

例如下图中表示出的01 和o2位置上出现的明显的discord

这种方法一遍用于已经确定长度的案例中,但是上述的方法并不知道什么是正常的,同时不知道是否是异常 只能确定一段时间内最异常的那个。
下面这两种是附属的
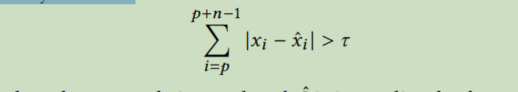
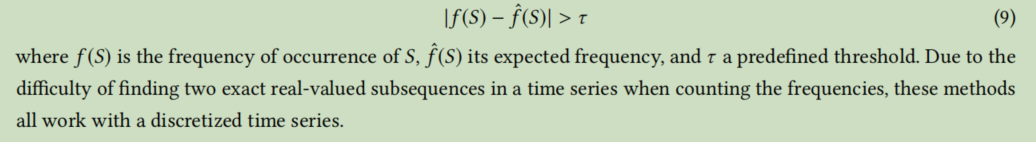


















 124
124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









