



 该文提出了一种基于LSTM的异常检测方法,通过堆叠LSTM网络学习时间序列的正常行为,无需预先指定的上下文窗口或数据预处理。模型预测误差分布并用多元高斯函数建模,以检测异常。实验表明,这种方法在多个真实世界数据集上表现良好,尤其是在捕捉短期和长期依赖性方面优于传统的RNN-AD。
该文提出了一种基于LSTM的异常检测方法,通过堆叠LSTM网络学习时间序列的正常行为,无需预先指定的上下文窗口或数据预处理。模型预测误差分布并用多元高斯函数建模,以检测异常。实验表明,这种方法在多个真实世界数据集上表现良好,尤其是在捕捉短期和长期依赖性方面优于传统的RNN-AD。
1.abstruct
本文的主要贡献在于使用了正常的数据训练,然后通过若干时序进行预测。使用多元高斯函数作为错误检测函数。
因为传统的方法主要是通过时间窗口内的累积和(CUSUM)和指数加权移动平均(EWMA)来检测底层分布的变化。LSTM 通过使用 ‘memory cells‘ 克服了RNN的梯度消失的问题,不需要对数据预处理 等很多优点
基于LSTM 本文贡献在于:
我们证明了通过堆叠LSTM网络建模一个时间序列的正常行为,我们可以准确地检测偏离正常行为,而不需要任何预先指定的上下文窗口或预处理。
1. 为了确保网络可以捕捉到时间序列的信息,所以会预测接下来几步的信息,因此一个点在之前也会多个不同的预测值,利用错误的概率分布来预测测试集的数据
2. 同时可以通过控制变量法来预测部分自变量 这迫使网络通过控制变量和传感器因变量的预测误差的联合分布来学习,可以让明显错误的输入也被检测到
2.LSMT-AD 的实现
一个时间序列 X={X(1),X(2),......,X(n)} ( 就是一系列的输入向量) X(t) 包括m维的时间序列 {X(t)1,X(t)2,......,X(t)m} 这就是一个m维的具体的向量 我们的模型会预测 接下来的 L 个值
序列分为四组:正常训练集(sN)、正常验证集-1(vN1)、正常验证集-2(vN2)和正常测试集(tN)。异常序列分为两组:异常验证集(vA)和异常测试集(tA)。
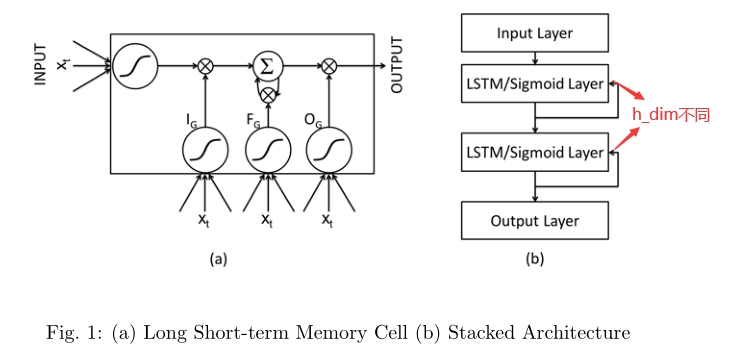
1. 我们首先学习一个使用叠加LSTM网络的预测模型,然后计算预测误差分布,用以检测异常:
在输入层为每个m维取一个单位,在输出层取d×l单位的输出 隐藏层中的LSTM单元通过循环连接完全连接
2.基于预测误差分布的异常检测
当预测长度为 L 时,对于 L < t ≤ n − L,x(t)∈X所选择的d维,每一个都被预测L次。我们计算点x(t)的误差向量e(t),即e(t)=[e(t)11,......,e(t)1l,......,e(t)d1,......,e(t)dl],其中e(t)ij是x(t)i与其在时间t−j预测的值之间的差。
将误差向量建模为多元高斯分布
结论
i)堆叠的LSTM网络能够在没有模式持续时间的先验知识的情况下学习更高层次的时间模式,因此(ii)堆叠的LSTM网络可能是一种可行的技术来模拟正常的时间序列行为,然后可以用来检测异常。我们的LSTM-AD方法在四个真实世界的数据集上产生了有希望的结果,这些数据集涉及对短期和长期时间依赖性的建模。与RNN-AD相比,LSTM-AD给出了更好或相似的结果,这表明基于LSTM的预测模型可能比基于RNN的模型更稳健,特别是当我们事先不知道正常行为是否涉及长期依赖时。
ref
https://www.cnblogs.com/wupiao/articles/13462140.html

















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









