







2.1举例
具有自主运动能力的机器人需要什么技术支撑?
首先它得会动,其次,“自主”,必须需要它掌握两个知识:
- 我在哪?(内部自身具体定位)
- 我周围有什么?(外部环境整体建图)
GPS或者周围环境感应,可以解决这两个知识的获取问题,但这两个技术受制精度与成本等,未必是最好的选择。
而SLAM技术,尤其强调未知环境,以不变应万变。这样的技术可以适合更多种类的场景,实现过程也会更加简便。
视觉SLAM主要分为单目,双目以及深度(RGB-D)三种相机,但基本原理和单目均相似。
- 单目相机:成本低,但由于单目无法获取深度,只能通过视频中各种物体运动产生的视差,判断物体的远近和相对大小 ,因此单目相机具有尺度不确定性。
- 双目相机:获得了深度信息,可以确定尺度信息,但是要计算每个点的深度,算力要求较高。
- 深度相机:通过红外结构光或ToF原理,前两个技术只通过软件计算,而深度相机直接发射光并计算距离,计算大大简化。但目前还有噪声,视野小,易受强光干扰等缺点。室内比较适合。
2.2经典视觉SLAM框架
SLAM流程主要包括
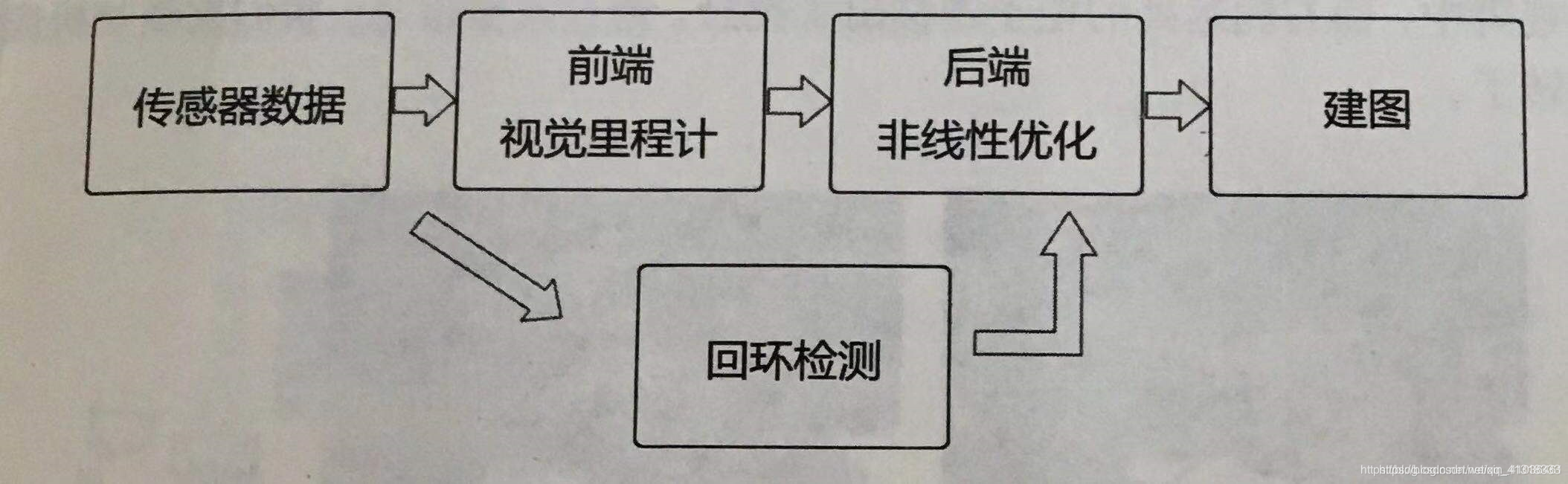
- 传感器信息读取:相机信息读取及预处理
- 前端视觉里程计(visual Odometry):估算相邻图像间相机的运动以及局部地图的样子
- 后端(非线性)优化:接受不同时刻VO测量的相机位姿,以及回环检测的信息,对其进行优化,得到全局一致的轨迹与地图
- 回环检测(loop closure detection):判断机器人事都到达过先前的位置,如果检测到回环,则会把信息提供给后端处理
- 建图:根据估计的轨迹建立与任务要求对应的地图
在VSLAM中,前端与计算机视觉更相关,如特征提取和匹配;后端主要是滤波和非线性优化算法。
如果是静态、刚体、光照变化不明显、没有人为干扰的工作场景,那么这个技术框架是相当成熟的了。
2.2.1视觉里程计
主要关心相邻图像间的相机运动,并根据它恢复场景的空间结构
只计算相邻时间内的运动,如相邻2帧或5-10帧。
易产生累计漂移Acumulating Drift,因为误差会不断传递到下一次的计算中。
漂移Drift的直接影响是每次地图建立会存在不一致(图2-9非常直观地展现了这个现象)。
后端优化以及回环检测就是用来修正漂移的。
2.2.2后端优化
主要用来处理测量误差。从带有噪声的数据中估计整个系统的状态(自身轨迹&地图),以及估计的不确定性,即最大后验概率估计Maximum-a-Posteriori MAP。
后端的问题也是SLAM的主要问题——对运动主体自身和周围环境空间不确定性的估计。
因此我们需要状态估计理论,把定位和建图的不确定性表达出来,然后采用滤波器或非线性优化,估计状态的均值和不确定性(方差)。
2.2.3回环检测
如果机器人回到某处,但是由于漂移,位置估计发生了偏差,这个时候就需要做回环检测
主要的手段就是通过输入的图像的相似性去判断他们是不是同一个地方。检测到之传递给后端优化,然后就可以对轨迹和地图进行调整。
2.2.4建图
建的地图会根据实际需求调整其特点,地图种类大致分为2种:
- 度量地图:强调物体位置关系,简单定位的时候使用稀疏sparse地图,只标注重要地标(但墙可能就标了),复杂导航的时候使用稠密dense地图,任意位置都有方格表达信息,因此耗空间,也容易出现不一致问题。
- 拓扑地图:强调地图元素之间的关系,只有节点、边和连通情况,表达更紧凑,适合简单结构地图。
2.3 SLAM问题的数学表述
假设地图由多个路标组成,每个时刻相机或传感器会测量到一部分路标点
2.3.1 基本变量
离散时刻
t
t
t =
1
,
.
.
.
,
K
1, ... , K
1,...,K
相机各时刻位置
x
1
,
.
.
.
,
x
K
x_1,...,x_K
x1,...,xK
路标总数
N
N
N
路标位置
y
1
,
.
.
.
,
y
N
y_1,...,y_N
y1,...,yN
2.3.2 基本通用数学模型
-
运动方程
从 k − 1 k-1 k−1时刻到 k k k时刻,位置 x x x的变化情况,描述为:
x k = f ( x k − 1 , u k , w k ) x_k=f(x_{k-1},u_k,w_k) xk=f(xk−1,uk,wk)
u k u_k uk为运动传感器, w k w_k wk为过程中加入的噪声 -
观测方程
在 x k x_k xk位置看到路标点 y j y_j yj时,产生了一个观测数据 z k , j z_{k,j} zk,j,关系描述为
z k , j = h ( y j , x k , v k , j ) z_{k,j}=h(y_j,x_k,v_{k,j}) zk,j=h(yj,xk,vk,j)
v k , j v_{k,j} vk,j是这次观测里的噪声 -
SLAM过程可总结为两个基本方程:
{ x k = f ( x k − 1 , u k , w k ) , k = 1 , . . . , K z k , j = h ( y j , x k , v k , j ) , ( k , j ) ∈ O \left\{ \begin{array}{c} x_k=f(x_{k-1},u_k,w_k), k=1,...,K\\ z_{k,j}=h(y_j,x_k,v_{k,j}), (k,j) \in O \end{array} \right. {xk=f(xk−1,uk,wk),k=1,...,Kzk,j=h(yj,xk,vk,j),(k,j)∈O
O O O为集合,记录着在哪个时刻看到了哪个路标。
这两个基本方程描述了最基本的SLAM问题,当知道运动测量的读数 u u u,传感器的读数 z z z时,如何求解定位问题(估计 x x x)和建图问题(估计 y y y)。即建模成一个状态估计问题。
2.3.3 参数化
根据传感器的不同,这里的 x k x_k xk, u k u_k uk, z j , k z_{j,k} zj,k等也会有不同的参数化形式。
这里给了一个以二维激光传感器的例子,不过感觉用latex写太麻烦,以后补充。
2.3.4 求解
按照运动和观测方程成是否为线性,噪声是否服从高斯分布进行分类。
- 线性高斯(LG)系统:最为简单,它的无偏最优估计可由卡尔曼滤波器给出。
- 非线性非高斯(NLNG)系统:使用以扩展卡尔曼滤波器(EKF)和非线性优化两大方法去求解
早期的主流方法为EKF,但存在线性化误差和噪声高斯分布假设等缺点。于是后来使用粒子滤波器等滤波器或者非线性优化的方法。现在主流VSLAM更多使用图优化为代表的优化技术进行状态估计。且在计算资源充足的情况下,优化技术明显优于滤波技术。
2.4编程基础
2.4.1linux
建议18.04,不过目前我用的还是16.04
2.4.2HelloWorld
使用g++对c++源码文件进行编译,然后运行编译后的文件,即可实现功能。
2.4.3 cmake
真实的项目中,类与类关系错综复杂,有的要编译成可执行文件,有的要编译成库文件,如果用g++,就要用大量的编译指令,这一般会用makefile去解决。
但cmake整体上会更加方便,且工程上被广泛使用。我们通过cmake命令生成makefile,然后用make指令,根据makefile去编译整个工程。
CMakeList.txt用于陈述cmake要执行的任务,有特定语法。维护几个CMakefile会比输入很多g++指令方便的多。
常见cmake流程:
mkdir build
cd build
cmake ..
make
这样做可以把cmake生成的中间文件隔离在build中,易于管理。
2.4.4 库
一些代码不会变成可执行程序,只会被打包在一起,供其他程序调用,即为库。
本领域常见的库有:OpenCV(视觉),Eigen(矩阵代数计算)等。
cmake中,添加add_library代码实现库的编译任务。
linux中,编译好的库文件分为:
- 静态库:.a为后缀,每次被调用都生成副本
- 共享库:.so为后缀,只有一个副本,更省空间
编译好的库文件是二进制的,因此我们还需要头文件指明其用法。
在CMakeLists中,生成可执行程序处,也需要将其链接到使用的库上
add_executable(useHello useHello.cpp)
target_link_libraries(useHello hello_shared)
cmake总结
- cmake编译,生成一些中间文件,make编译,编译整个工程
- 程序代码由头文件和源文件组成
- 带有main的源文件编译成可执行程序,其余为库文件
- 如果可执行程序想调用库函数,须参考库文件提供的头文件,同时把可执行文件连接到库文件上
这里提醒了一下不加链接的后果。
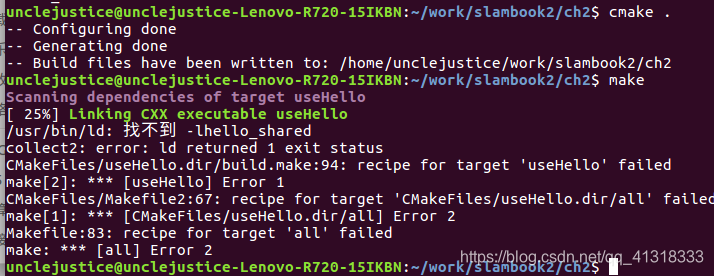 cmake正常,但是make,编译可执行文件时会报错,显示找不到库。
cmake正常,但是make,编译可执行文件时会报错,显示找不到库。
2.4.5 IDE
介绍了KDevelop和CLion,不过个人觉得vscode会是未来。

















 3018
3018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









